AI大模型時代的“賣鏟人”:堆棧AI Infra
類比計算機系統的基礎軟件層以及雲計算三層架構的PaaS層級,我們認爲,AI產業鏈中也有層級相似,定位於算力與應用之間的“橋梁”角色的基礎軟件設施層即AI Infra。新一輪生成式AI浪潮,對於上層應用而言機遇與挑战並存,而AI Infra作爲必要的基礎設施,我們認爲其技術及商業發展前景的確定性或更強。本文我們聚焦AI Infra,揭示其內涵並總結目前國內外項目的商業化進展,再從工作流視角詳細梳理各環節及代表廠商。我們認爲,AI Infra是AI產業必不可少的基礎軟件堆棧,“掘金賣鏟”邏輯強、商業潛質高,建議投資者持續關注AI Infra相關投資機會。
摘要
在預訓練大模型時代,我們可以從應用落地過程裏提煉出標准化的工作流,AI Infra的投資機會得以演繹。傳統ML時代AI模型通用性較低,項目落地停留在“手工作坊”階段,流程難以統一規範。而大規模預訓練模型統一了“從0到1”的技術路徑,具備解決問題的泛化能力,能夠賦能“從1到100”的各類應用,並存在相對標准化的工作流,由此衍生出AI Infra投資機會。GPT 4的开發經驗也體現專業分工的必要性:根據OpenAI的披露,在GPT 4的开發過程中,其對249人研發團隊進行了明確分工,並使用了數據標注、分布式計算框架、實驗管理等點工具。我們認爲這也說明了在大模型時代應用基礎軟件的必要性。目前,AI Infra產業處於高速增長的發展早期,我們預計未來3-5年內各細分賽道空間或保持30%+的高速增長,且各方向均有變現實踐與養成獨角獸企業的潛力。
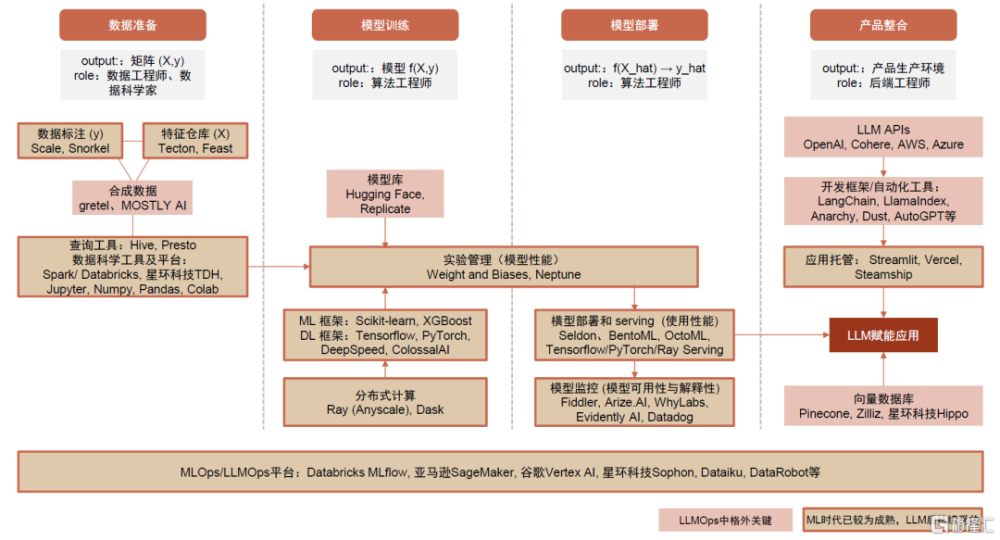
“AI = Data + Code”,組織AI所需的養料即數據,管理AI模型的訓練部署過程,以及支持從模型到應用的整合是AI Infra工具的關鍵能力。1)數據准備:無論是支持經典的機器學習模型還是大規模預訓練模型,數據准備都是耗時較久、較爲關鍵的一環。我們認爲,LLM浪潮下高質量的標注數據和特徵庫需求將持續增長,未來海量訓練數據的需求或由合成數據滿足。此外,我們強調Data+AI平台廠商的關鍵卡位。2)模型訓練:預訓練模型的獲取使得模型庫更加流行,LLM大規模訓練需求也驅動底層分布式計算引擎和訓練框架的迭代。此外,我們認爲實驗管理工具重要性較高。3)模型部署:LLM模型端的突破釋放出大規模應用落地的潛能,更多模型從實驗走向生產環境,我們認爲有望整體提振模型部署和監控的需求。4)應用整合:LLM賦能應用催生對向量數據庫和應用編排工具等的新需求。我們觀察到經典的機器學習時代與大模型時代工具棧需求側重點有所不同,同時,部分點工具正在拓寬產品功能邊界,LLMOps平台型產品的可及市場空間天花板或更高。
風險
技術進展不及預期、應用落地不及預期、行業競爭加劇。
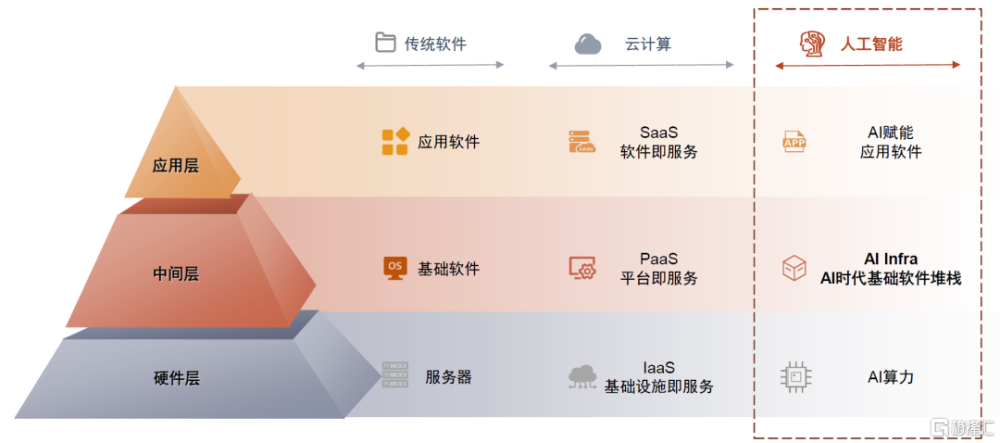
圖表1:一圖詳解大模型時代的基礎軟件堆棧——AI Infra

注:圖中市場規模數據爲我們在正文圖表9相關資料來源基礎上估算得到的約數;圖中灰色文本框爲我們的觀點 資料來源:Grand View Research,Foresight News,Gartner,MarketsandMarkets,拾象科技,Firstmark,a16z,各公司官網,中金公司研究部
初見:AI Infra是連接算力和應用的AI中間層基礎設施
本章主要討論:1)AI Infra在AI時代IT生態中的定位;2)爲什么大模型浪潮下需要格外關注AI Infra投資機會;3)AI Infra基礎軟件工具棧涵蓋內容;4)AI Infra商業化初探。
類比基礎軟件和PaaS,AI Infra是AI時代的中間層基礎設施
從類比的角度理解AI Infra:AI時代連接硬件和上層應用的中間層基礎設施。傳統本地部署時代,三大基礎軟件(數據庫、操作系統、中間件)實現控制硬件交互、存儲管理數據、網絡通信調度等共性功能,抽象並隔絕底層硬件系統的復雜性,讓上層應用开發者能夠專注於業務邏輯和應用功能本身的創新實現。雲時代同理,形成了IaaS、PaaS、SaaS三層架構,其中PaaS層提供應用开發環境和基礎的數據分析管理服務。類比來看,我們認爲,進入AI時代也有承擔類似功能的、連接算力和應用的基礎設施中間層即AI Infra,提供基礎模型服務、賦能模型微調和應用开發。
圖表2:AI Infra是人工智能時代連接硬件和上層應用的中間層基礎設施
資料來源:中金公司研究部
大模型通用性賦能下應用落地流程更加標准化,催生AI Infra投資機會
LLM流行前,AI模型通用性較低,項目落地停留在“手工作坊”階段,流程難以統一規範。人工智能已有數十年的發展歷史,尤其是2006年以來以深度學習爲代表的訓練方法的成熟推動第三波發展浪潮。然而,由於傳統的機器學習模型沒有泛化能力,大部分AI應用落地以定制化項目的形式,包括需求、數據、算法設計、訓練評估、部署和運維等階段,其中,數據和訓練評估階段往往需要多次循環,較難形成一套標准化的端到端的流程和解決方案,也由此造成了邊際成本高、重復造輪子等問題。
大規模預訓練模型完成了“從0到1”的技術統一,泛化能力和通用性釋放出“從1到100”的落地需求,且存在相對標准化的流程,衍生出AI Infra投資機會。基於Transformer算法、超大參數量的預訓練模型擁有泛化能力,一定程度上解決了原先需要按項目定制訓練的問題,過去正因爲ML模型的非標和項目制,下遊需求並未被完全激發出來,LLM模型端的突破釋放出更大規模的應用落地潛能。而後續的應用過程中主要涉及:高質量樣本數據的准備、基礎模型獲取、模型微調及部署監控、應用編排开發上线等環節,工作流較爲標准化,我們建議投資者持續關注AI Infra投資機會。
圖表3:具有泛化能力的通用大規模預訓練模型賦能下,後續工作流較爲標准化,衍生出AI Infra投資機會
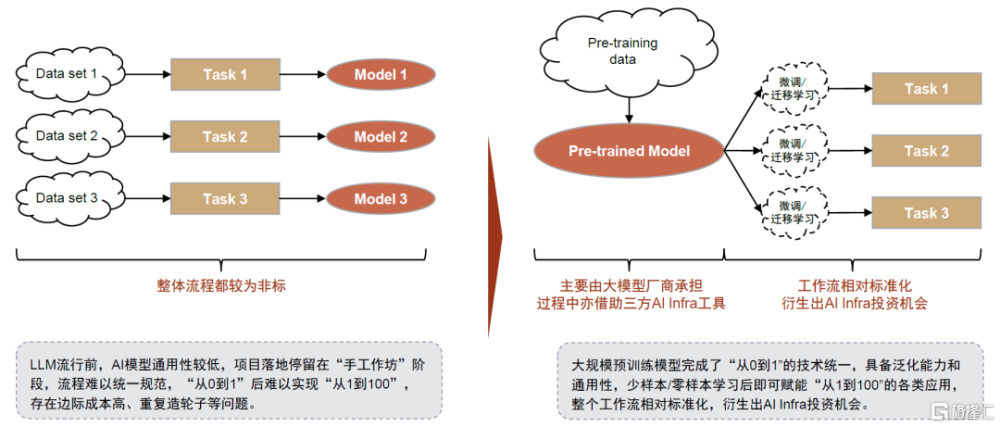
資料來源:中金公司研究部
從OpenAI實踐看分工必要性,核心關注工作流相關的基礎軟件工具棧
參考海外OpenAI的率先嘗試,工作流分工、點工具加持助力成功。一方面,OpenAI在《GPT-4 Technical Report》論文中[1]中披露了參與GPT 4开發的人員分工,共249人,角色分工明確,預訓練、強化學習和對齊、部署等6個大方向下又拆分成不同小組,其中數據集/數據基礎設施、分布式訓練基礎設施、推理基礎設施等分別對應工作流中的數據准備、模型訓練、部署應用等環節;另一方面,OpenAI使用了Scale數據標注服務、Ray分布式計算框架和Weights and Biases(W&B)實驗管理工具,且W&B的創立靈感就來自於其創始人之一在OpenAI的實習經歷。我們認爲,OpenAI的率先嘗試經驗一定程度上說明專業分工和AI Infra基礎軟件堆棧在大模型時代的必要性。
圖表4:Open AI《GPT-4 Technical Report》中披露的人員分工明確

資料來源:《GPT-4 Technical Report》(OpenAI,2022),中金公司研究部
AI Infra廣義上包含了基礎模型和基礎軟件棧兩層,本篇報告核心關注其中和工作流相關的基礎軟件工具棧。工作流的視角下,LLM的开發應用主要涉及數據准備、模型訓練、模型部署、產品整合四個主要環節,每個環節都有對應的點工具,亦有集大成的LLMOps平台型產品,我們將在下一章詳細解讀。
圖表5:AI Infra全景圖

資料來源:a16z官網,拾象科技公衆號,中金公司研究部
商業化起步中,已有變現實踐,細分賽道或均有長出獨角獸的潛力
商業化起步階段,有望在未來幾年快速成長爲百億美元量級的產業。我們認爲,AI Infra整體處於高速增長的發展早期,如圖表9的整理,根據第三方數據,目前大部分細分賽道規模在幾億至幾十億美元量級,我們預計在未來3-5年內或將保持30+%的高速增長。同時,Data+AI、MLOps/LLMOps等平台型產品的市場空間天花板可能更高,我們也觀察到點工具廠商正在積極拓展產品邊界。我們認爲,AI Infra是AI時代不可或缺的基礎設施中間層,“掘金賣鏟”邏輯的確定性高,有望持續受益於LLM、AI應用的繁榮。
圖表6:AI Infra細分賽道市場規模
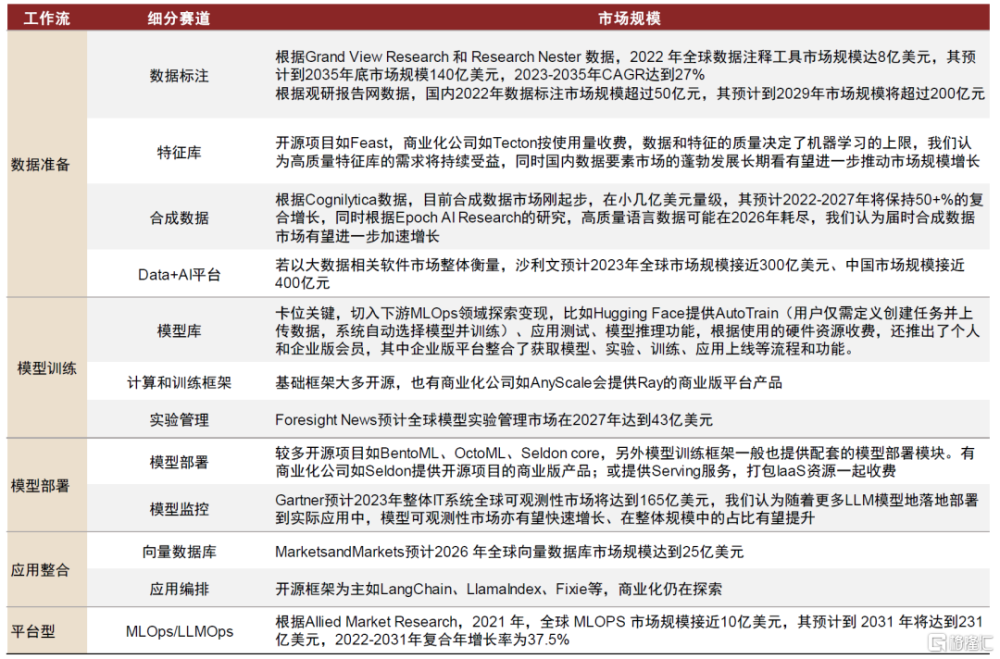
資料來源:Grand View Research,Foresight News,Gartner,MarketsandMarkets,Cognilytica,沙利文,Allied Market Research,Research Nester,中金公司研究部
海外廠商積極探索變現,細分賽道或均有長出獨角獸的潛力。從微觀的視角,我們整理了AI Infra各細分賽道海外代表公司的商業模式,基本遵循按使用量付費的定價模式。大多數創業公司成立時間較短,詳見圖表10,目前收入體量在數千萬至小幾億美元量級,其中數據相關的、平台型的廠商起步較早、已初具規模,我們認爲這也符合數據需要前置於AI模型投入、平台型廠商收入天花板更高的邏輯。此外,我們認爲LLM模型端突破將釋放出更大規模應用落地的潛能,有望帶動模型部署、應用整合等後續環節的逐步起量。
圖表7:AI Infra各賽道代表公司的商業模式一覽
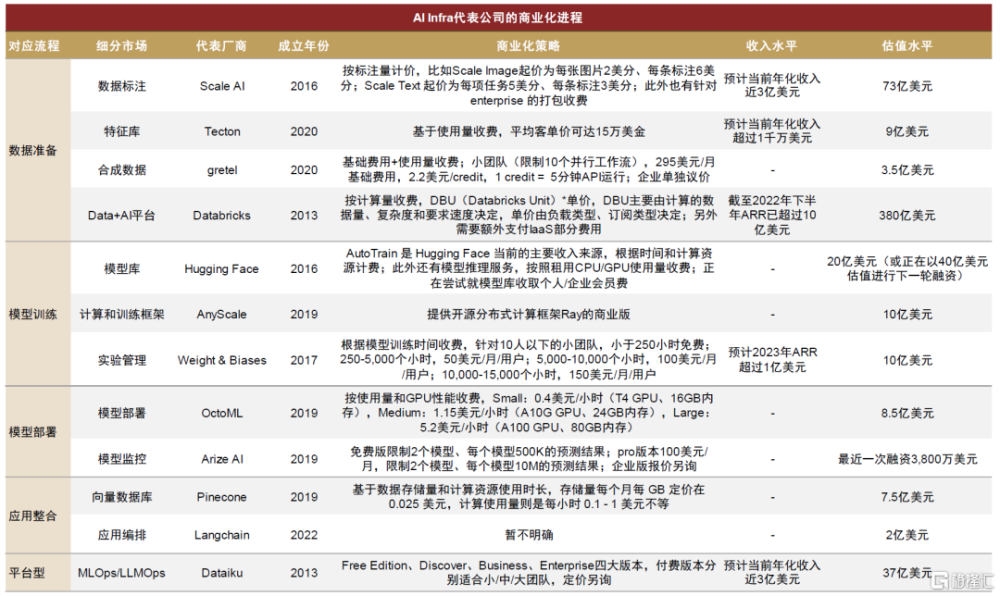
注:估值取最近一次公开融資披露數據,統計截至2023年7月;收入水平中,Scale AI、Tecton、Dataiku爲Growjo網站預測,Databricks來自公司官網披露,Weight&Biases爲海外獨角獸公衆號預計 資料來源:各公司官網,海外獨角獸公衆號,Growjo,中金公司研究部
探祕:從工作流視角梳理AI Infra投資機會
大模型時代和傳統機器學習時代工具棧側重點有所不同
本章從企業訓練模型、構建AI賦能應用的工作流視角出發,詳解涉及的主要環節,並關注LLMOps和MLOps在流程上的側重點差異。我們認爲AI = Data + Code,歷經數據准備、模型訓練、模型部署、產品整合,分環節看:
► 數據准備:高質量標注數據、特徵庫需求持續,合成數據或成未來趨勢。數據准備無論在傳統的MLOps還是LLMOps中都是耗時較久、較爲重要的一環。無監督學習降低對標注數據的需求,但RLHF機制體現了高質量標注數據的重要性,我們認爲未來超大參數量模型對海量訓練數據的需求或由合成數據滿足。此外,Data+AI平台廠商卡位關鍵。
► 模型訓練:模型庫更加剛需,訓練框架持續迭代,軟件工具協助實驗管理。基於通用的LLM大模型微調、蒸餾出小模型成爲高性價比的落地方式,因此需要能夠高效便捷地獲取預訓練模型的模型庫;也催生更適應LLM大規模訓練需求的底層分布式計算引擎和訓練框架。此外,我們認爲實驗管理工具的重要性或始終較高。
► 模型部署:更多模型從實驗走向真實業務環境,部署和監控需求提升。我們認爲,LLM模型端的突破釋放出大規模應用落地的潛能,更多的模型從實驗環境走向生產環境,有望整體提振模型部署和監控的需求。
► 應用整合:催生向量數據庫和應用編排框架新需求。LLM賦能應用催生出對應用產品整合相關工具產品的需求,其中較爲關鍵的是向量數據庫和應用編排工具。
圖表8:從工作流視角梳理,大模型時代和傳統ML時代工具棧側重點有所不同
資料來源:拾象科技,Firstmark,a16z官網,中金公司研究部
數據准備:高質量標注數據、特徵庫需求持續,合成數據或成未來趨勢
數據是模型的起點,一定程度上決定了模型的效果和質量,數據准備無論在傳統的MLOps還是LLMOps中都是耗時較久、較爲重要的一環。LLM帶來的新變化主要包括:1)雖然LLM的無監督學習機制降低了對標注數據的需求,但OpenAI的RLHF(Reinforcement Learning from Human Feedback)體現了高質量標注數據重要性;2)模型規模大幅提升,帶來日益增長的訓練數據需求,長期看可能無法僅通過真實世界數據滿足,合成數據提供一種AIGC反哺AI的解法。此外,數據基礎管理軟件平台的卡位始終關鍵,Data+AI平台化趨勢持續演進。
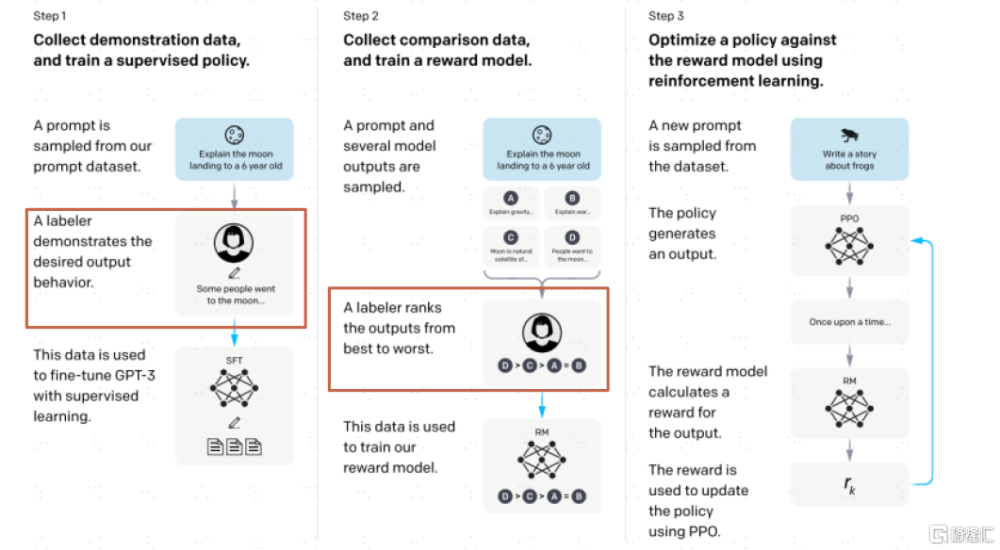
數據標注:GPT的成功說明了高質量標注數據對提升模型效果的重要性。數據標注位於模型开發的最上遊,對圖像、視頻、文本、音頻等非結構化原始數據添加標籤,爲AI提供人類先驗知識的輸入。近年,無監督學習(事先不定義明確目的)、強化學習(通過獎勵函數來指導學習過程)等不需要標注數據的機器學習分支方法論的出現引發市場對於數據標注必要性的討論與擔憂。不過,OpenAI通過RLHF即基於人類反饋的強化學習來優化模型,且從OpenAI[2]披露的分工中能看到有很多負責預訓練、強化學習等的AI科學家也參與到數據准備中;最新开源的LLAMA 2的論文[3]中也有一段強調高質量數據對模型訓練結果影響的表述,Meta與第三方供應商合作收集了近3萬個高質量標注,又向市場證明了高質量數據標注工作的重要性。
圖表9:高質量標注數據在GPT模型訓練中起重要作用
資料來源:《Training language models to follow instructions with human feedback》(OpenAI, 2022),中金公司研究部
數據標注廠商正在尋求智能化轉型、減少對人力的依賴。在數據標注助力AI快速發展的同時,AI也將反哺數據標注更加自動化、智能化,如利用模型進行數據預處理再人工審核等。今年4月Meta AI發布的Segment Anything Model[4]的訓練數據集SA-1B,就是通過智能數據引擎來輔助自動化生成的,該數據引擎經歷了輔助手動標注-半自動標注-自動化標注的訓練過程。
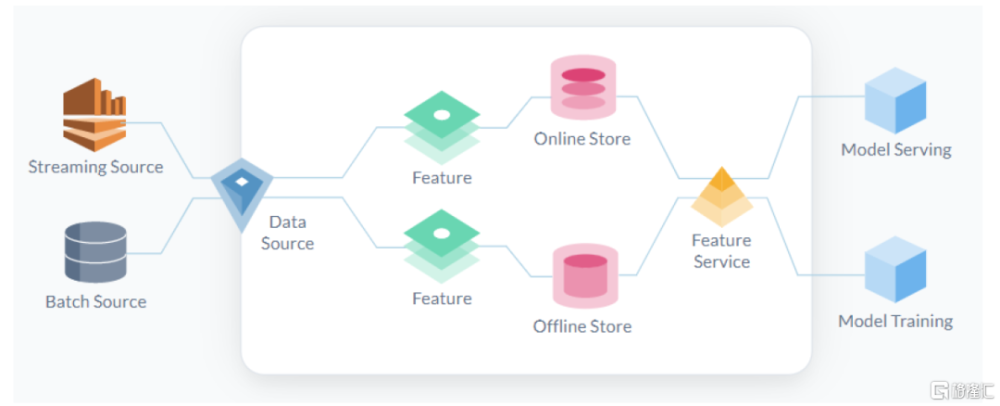
特徵庫(Feature Store):高質量特徵庫持續受益。特徵是預測模型的輸入信號,可以簡單理解爲模型中的自變量X,需要經過特徵工程從原始數據中篩選得到。而特徵庫則是生產、管理、運營ML過程中所需數據及特徵的系統,主要實現1)運行各類數據管道(Pipeline)將原始數據轉換爲特徵值;2)存儲和管理特徵和數據;3)爲訓練和推理提供一致的特徵服務。目前該領域的代表性產品包括:开源項目如Feast,獨立商業化公司如Tecton,大型科技廠商的ML平台如Databricks、SageMaker等中亦有相應模塊。數據和特徵的質量決定了機器學習的上限,我們認爲高質量特徵庫有望持續受益,同時國內數據要素市場的蓬勃發展長期看有望爲AI模型供應更多高質量的數據燃料。
圖表10:特徵庫是生產、管理、運營ML過程中所需數據及特徵的系統
資料來源:Tecton官網產品文檔,中金公司研究部
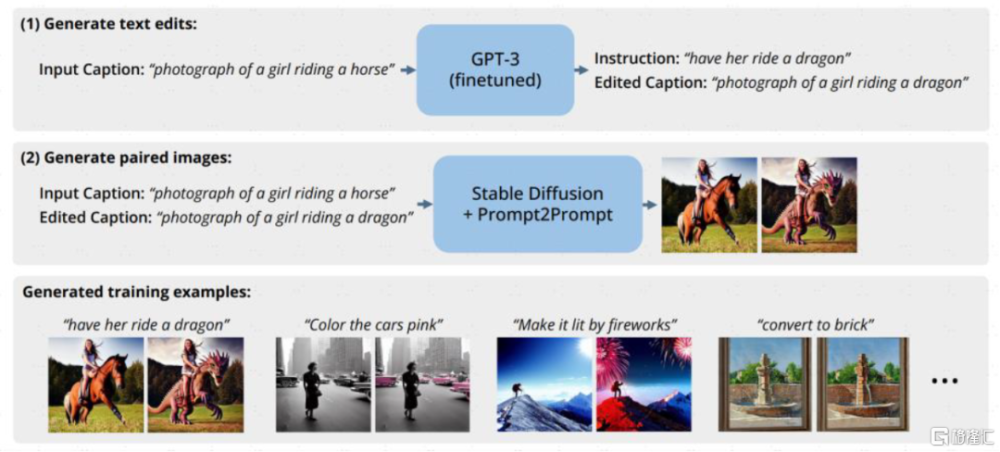
合成數據:做真實數據的“平替”,用AIGC反哺AI。一項來自Epoch AI Research團隊的研究預測存量的高質量語言數據將在2026年耗盡[5],低質量的語言和圖像數據存量也將在未來的數十年間枯竭。面對潛在的數據瓶頸,合成數據即運用計算機模擬生成的人造數據,提供了一種成本低、具有多樣性、規避了潛在隱私安全風險的解決方法,生成式AI的逐漸成熟進一步提供技術支撐。比如,自然語言修改圖片的Instruct-Pix2Pix模型在訓練的時候就用到GPT3和Stable Diffusion來合成需要的提示詞和圖像的配對數據集;Amazon也利用合成數據來訓練智能助手Alexa[6],以避免用戶隱私問題。合成數據市場參與者較多,獨立公司/項目如gretel、MOSTLY AI、datagen、hazy等,數據標注廠商如Scale亦推出相關產品,此外主流科技公司英偉達、微軟、亞馬遜等均有不同場景的嘗試。
圖表11:Instruct-Pix2Pix借助GPT-3、Stable Diffusion生成指令-圖像訓練數據集
資料來源:《InstructPix2Pix: Learning to Follow Image Editing Instructions(Tim Brooks等,2022》,中金公司研究部
數據科學基礎平台:數據卡位始終關鍵,Data+AI是行業趨勢。廣義的數據科學涵蓋利用各類工具、算法理解數據蕴藏含義的全過程,機器學習可以視爲其中的一種方式和手段;狹義的數據科學也可以僅指代機器學習的前置步驟,包括准備、預處理數據並進行探索性分析等。正如我們從報告《》开始一直強調的觀點,數據和AI一體兩翼,數據是模型的起點、且一定程度上決定了模型的最終效果和質量,數據基礎設施廠商卡位關鍵,從Data向AI布局是技術能力和業務邏輯的自然延伸。LLM等大模型的滲透發展不僅額外增加了數據平台上AI相關的工作流負載,還可以帶動底層Data基礎設施的需求。
模型訓練:模型庫更加剛需,訓練框架持續迭代,軟件工具協助實驗管理
大模型具有一定通用性,开發者們可以“站在巨人的肩膀上”,在預訓練模型的基礎上通過少量增量訓練蒸餾出專精的小模型以解決垂類場景的需求。LLM帶來的新變化主要包括:1)要想高效便捷地獲取模型,則需要一個集成托管各類模型的社區也即模型庫;2)催生更適應LLM大規模訓練需求的底層分布式計算引擎和訓練框架。此外,模型訓練過程涉及多次往復的修改迭代,無論是ML還是LLM都需要借助實驗管理工具進行版本控制和協作管理。
模型庫(Model Hub):把握從數據到模型的工作流入口。模型庫顧名思義是一個托管、共享了大量开源模型的平台社區,供开發者下載各類預訓練模型,除模型外,主流的Model Hub平台上還同時提供各類共享的數據集、應用程序Demo等,是AI、ML細分領域的“GitHub”。典型代表廠商包括海外的Hugging Face、Replicate,國內關注Gitee(开源中國推出的代碼托管平台)和ModelScope(阿裏達摩院推出的AI开源模型社區)等項目。在商業模型上,Model Hub廠商一般選擇切入下遊的AutoTrain(自動創建、優化、評估模型)或模型推理服務,也在嘗試就Model Hub功能收取訂閱制會員費用。
圖表12:Hugging Face上托管了NLP、機器視覺等各類模型
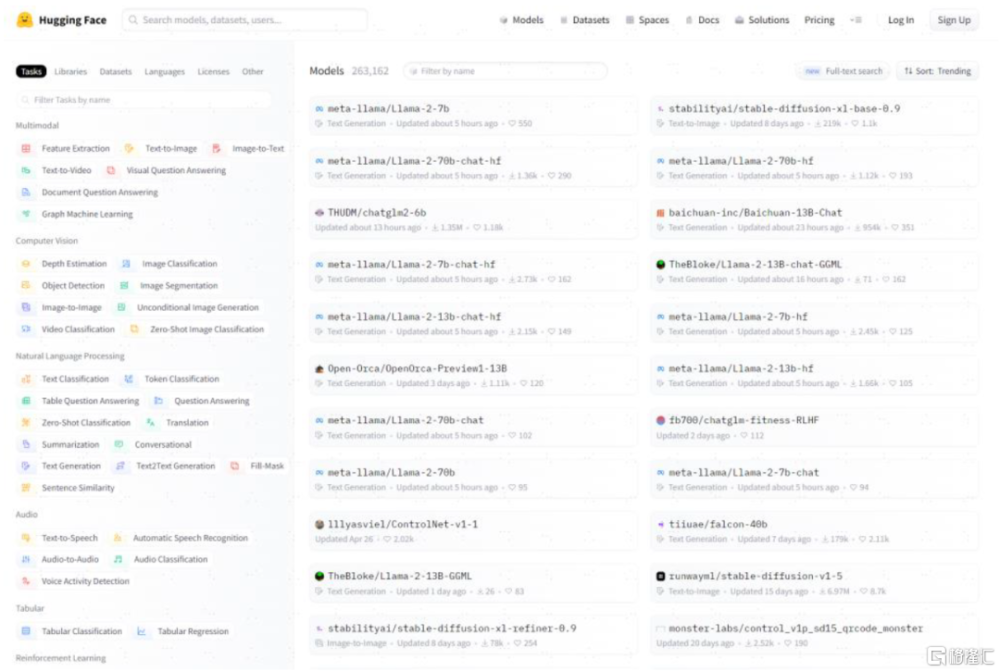
資料來源:Hugging Face官網,中金公司研究部
分布式計算和深度學習框架:大模型“煉丹爐”。分布式計算引擎方面,LLM的訓練過程需要大規模的GPU分布式計算集群,過去大數據已帶動了以MapReduce、Spark爲代表的分布式計算引擎的發展,但以Ray爲代表的近年在AI大潮下興起的分布式計算框架則更貼合AI需求(Ray的首篇論文名爲《Ray: A Distributed Framework for Emerging AI Applications[7]》),其核心模塊Ray Tune、Ray Rllib、Ray Train分別對應機器學習調參、強化、深度學習調參的流程。Ray在官網的用戶案例中表示“Ray是使OpenAI能夠增強其訓練ChatGPT和類似模型能力的關鍵”[8]。此外,Ray作爲更底層的分布式計算引擎,和TensorFlow、PyTorch等深度學習框架兼容,而DeepSpeed、ColossalAI等則是在PyTorch等基礎框架之上針對LLM的優化訓練設計的新一代框架。
實驗管理:記錄實驗元數據,輔助版本控制,保障結果可復現。模型訓練是一種實驗科學,需要反復的修改與迭代,同時由於無法提前預知實驗結果往往還涉及版本回溯、多次往復,因此模型的版本控制和管理就較爲必要,實驗管理軟件可以輔助技術人員和團隊追蹤模型版本、檢驗模型性能。該領域代表廠商爲Weights and Biases(W&B)和Neptune,跟蹤機器學習實驗,記錄實驗元數據,包括訓練使用數據集、框架、進度、結果等,支持以可視化的形式展現結果、多實驗結果對比、團隊協作共享等。此外,實驗管理也是LLMOps/MLOps平台型產品如星環科技Sophon、Google Vertex AI等產品中的重要模塊之一。
圖表13:以Neptune爲例,記錄每次實驗的元數據,支持多實驗結果對比
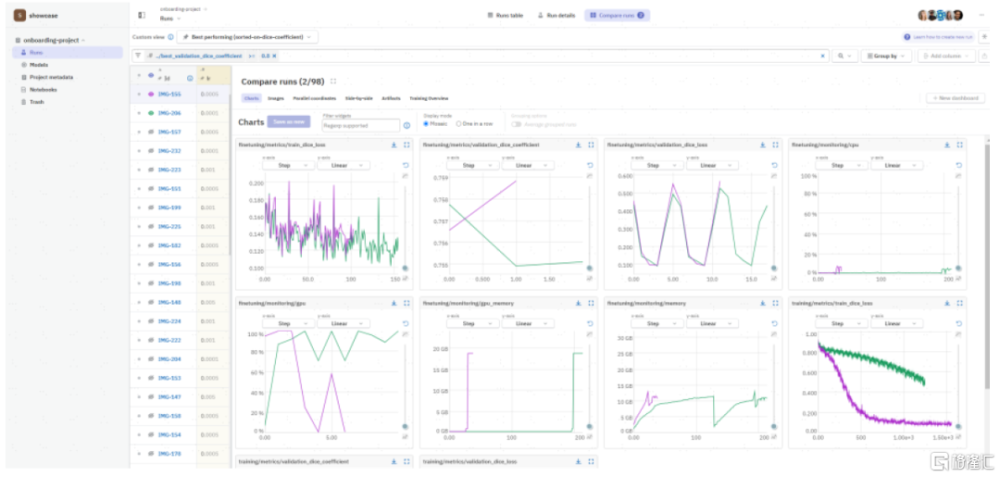
資料來源:Neptune官網,中金公司研究部
模型部署:更多模型從實驗走向真實業務環境,部署和監控需求提升
模型部署是讓模型從實驗環境走向真實生產環境的重要環節,借助模型部署工具能夠解決模型框架兼容性差的問題並提升模型運行速度。模型監控通過對模型輸出結果和性能指標的追蹤,保障模型上线後的可用性。我們認爲,過去由於ML模型的非標和項目制,大規模、持續性的模型部署和監控需求未被完全激發出來,LLM模型端的突破釋放出大規模應用落地的潛能,更多的模型從實驗環境走向生產環境,我們認爲有望整體提振模型部署和監控的需求。
模型部署:從實驗走向生產的重要環節。模型部署指把訓練好的模型在特定環境中運行,需要盡量最大化資源利用效率,保證用戶使用端的高性能。模型部署領域參與者較多,比如Ray、Tensorflow、PyTorch等訓練框架都提供配套的模型部署功能,模型庫廠商如Hugging Face、實驗管理廠商如W&B也有相關產品,此外還有如Seldon、BentoML、OctoML等獨立項目/產品。和訓練框架自帶的部署模塊相比,三方的綜合性產品能夠爲不同框架下訓練出來的模型提供一套相對統一的部署方式。以Seldon爲例,在復雜的多模型推理場景下,Seldon通過模型可解釋性、異常值檢測等模塊,最終選出表現最好的模型進行結果反饋。
圖表14:Seldon支持的單一模型、復雜多模型的推理過程示意
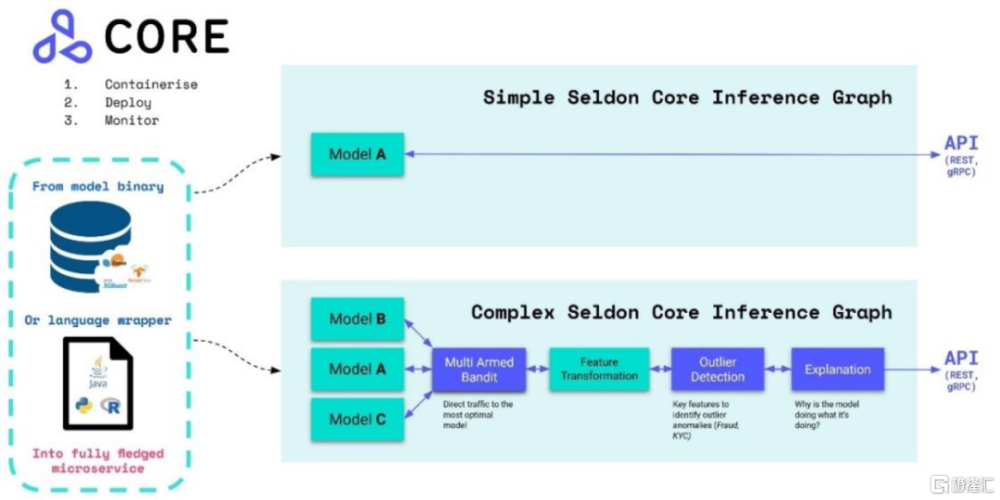
資料來源:Seldon官網產品文檔,中金公司研究部
模型監控:模型可觀測性保障可靠可用。可觀測性在傳統IT系統運維中就是重要的數智化手段之一,通過監控各類機器、系統的運行數據對故障和異常值提前告警。模型監控同理,監測模型上线後的數據流質量以及表現性能,關注模型可解釋性,對故障進行根因分析,預防數據漂移、模型幻覺等問題。模型可觀測性領域有較多創業公司,包括Fiddler、WhyLabs、Evidently AI等,實驗管理廠商如W&B、模型部署廠商如Seldon也有所涉及,此外,傳統的IT運維可觀測性廠商也有機會切入AI模型監控領域,海外如Datadog已經嘗試將Open AI的模型服務加入納管範疇,我們也建議關注國內相關廠商的後續進展。
圖表15:以WhyLabs爲例看模型可觀測性在工作流中的具體環節定位
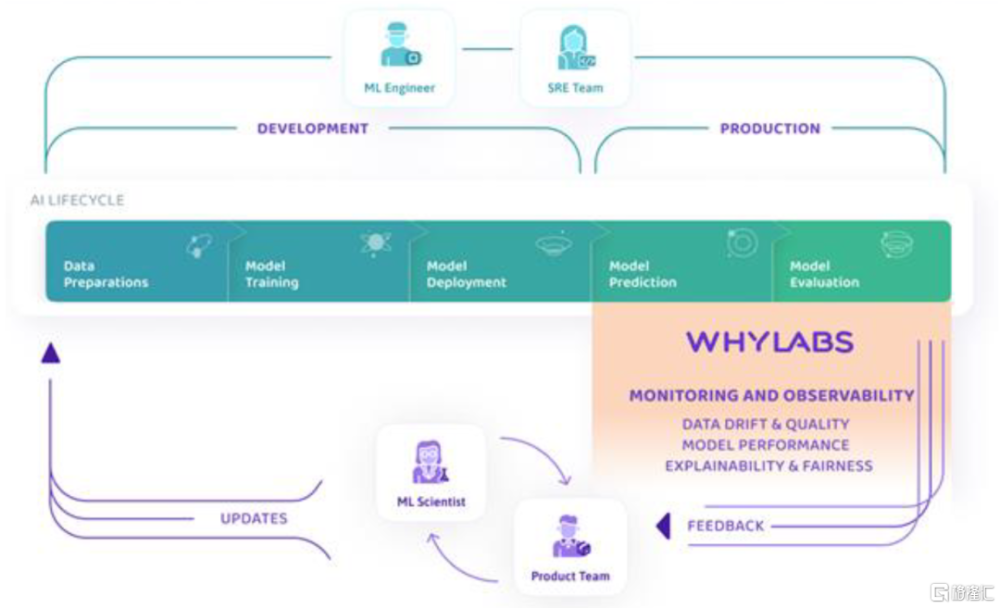
資料來源:WhyLabs官網產品文檔,中金公司研究部
應用整合:催生向量數據庫和應用編排框架新需求
正如前文提及,LLM模型端的突破釋放出更多應用落地的潛能,由此催生出對應用產品整合相關工具產品的需求,其中較爲關鍵的是向量數據庫和LLM應用編排工具。
向量數據庫:LLM的外部知識庫。讓通用大模型具備專業知識主要有兩種途徑,一是通過微調將專有知識內化到LLM中;另一種則是利用向量數據庫給LLM增加外部知識庫,後者成本更低。向量數據庫和LLM的具體交互過程爲:用戶首先將企業知識庫的全量信息通過嵌入模型轉化爲向量後儲存在向量數據庫中,用戶輸入prompt時,先將其同樣向量化,並在向量數據庫中檢索最爲相關的內容,再將檢索到的相關信息和初始prompt一起輸入給LLM模型,以得到最終返回結果。
向量化技術本身已較爲成熟,海外模型如Word2Vec、FastText等,國內中文Embedding模型有MokaAI开源的M3E、IDEA CCNL[9]开源的二郎神系列。向量數據庫廠商/產品主要包括Pinecone、Zilliz、星環科技Hippo等,另外也有傳統數據庫、大數據平台廠商如PGSQL、Databricks通過增加向量查詢引擎插件來實現支持。我們認爲,向量數據庫是AI Answers類應用落地的剛需,同時本土廠商在中文Embedding方面可能更具優勢。
圖表16:向量數據庫和LLM的具體交互過程
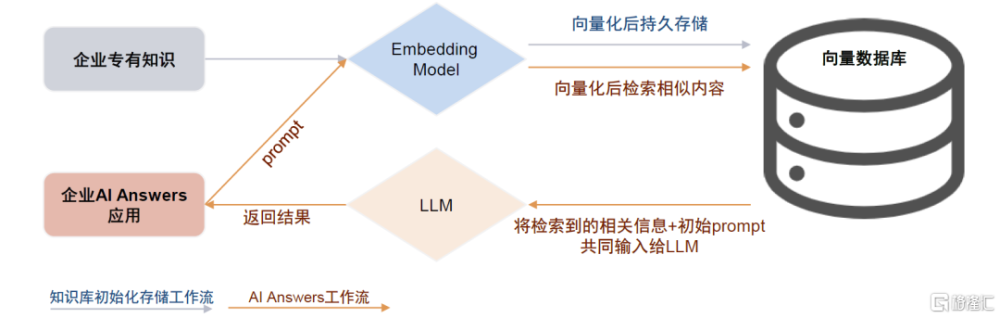
資料來源:Pinecone官網,星環科技公衆號,中金公司研究部
應用編排框架:LLM應用“粘合劑”。LLM應用編排框架是一個封裝了各種大語言模型應用开發所需邏輯和工具的代碼庫,LangChain是當下最流行的框架之一,還有Anarchy、Dust、AutoGPT、LlamaIndex等。初始化的大模型存在無法聯網、無法調用其他API、無法訪問本地文件、對Prompt要求高、生成能力強但內容准確度無法保證等問題,應用編排框架提供了相應功能模塊,幫助實現從LLM到最終應用的跨越。以LangChain爲例,它主要包含以下幾個模塊:1)Prompt實現指令的補全和優化;2)Chain調用外部數據源、工具鏈;3)Agent優化模塊間的調用順序和流程;4)Memory增加上下文記憶。
集成开發環境:交互式Notebook逐漸流行。在上述AI建模流程中,开發者需要處理大量代碼編寫、分析、編譯、調試等工作,可以直接在對應環節或平台型產品的內置環境中進行,也可以使用專門的集成开發環境並調取所需功能。其中,Notebook是一種交互式的开發環境,和傳統的非交互式开發環境相比,Notebook可以逐單元格(Cell)編寫和運行程序,出現錯誤時,僅需調整並運行出現錯誤的單元格,大大提升开發效率,因此近年逐漸流行、深受數據科學家和算法工程師的喜愛,被廣泛應用於AI算法开發訓練領域。
點工具不斷拓寬產品邊界,LLMOps一站式解決方案或更適應國內市場
點工具廠商正不斷拓寬能力邊界。前文我們詳細介紹了模型訓練、構建應用工作流涉及的主要環節及各環節點工具廠商,事實上,這些點工具廠商在強項環節之外亦不斷拓寬產品能力邊界,比如數據標注廠商Scale AI拓展合成數據業務並正在投入LLMOps領域的Scale Spellbook(做一個基於大語言模型的开發者工具平台);模型庫廠商Hugging face切入AutoTrain和模型部署;實驗管理廠商W&B切入模型部署和模型監控等。
MLOps/LLMOps提供一站式平台解決方案,可及市場空間更大,多採取Data+AI一體化战略。除點工具外還有平台型的MLOps/LLMOps產品,基本涵蓋了上述流程的主要環節,大型科技企業、數據基礎軟件廠商均參與其中。我們認爲,基於整體數字化進程和軟件付費意愿習慣判斷,海外企業客戶可能傾向於選取點工具自組工具棧,而國內客戶可能傾向於一站式的解決方案。此外,從目前AI Infra領域獨角獸的估值水平來看,平台型廠商多採取Data+AI一體化战略,起步較早、規模天花板更高。
圖表17:AI Infra領域獨角獸企業一覽

注:統計截至2023年7月,最新估值截至各公司最近一次融資 資料來源:Crunchbase,中金公司研究部
求索:海外重點項目及公司一覽
(Scale、Hugging Face、Weight & Biases、Pinecone、Databricks、C3.AI)
數據准備:Scale
數據標注是核心業務,AI輔助或能降低人工參與比例。Scale從自動駕駛領域的標注起家,自動駕駛之後,公司的訂單還來自政府、電商、機器人、大模型(RLHF)等領域,對應着過去幾年AI行業的趨勢。目前公司支持地圖、商品目錄、圖像、視頻、文檔、音頻等各類數據的標注,按標注量計價,比如Scale lmage起價爲每張圖片2美分、每條標注6美分。數據標注產業較爲依賴人力,但公司也在訓練標注算法通過AI輔助降低人工參與比例。Open AI、Stability、Co:here等領先的生成式AI廠商均爲公司客戶。
積極布局LLMOps領域,推出企業級生成式AI平台產品。順應大模型趨勢,Scale推出了LLMOps應用开發平台工具Scale Spellbook,用戶僅需上傳數據、編輯指令,並可以直接比較、微調不同prompt、不同LLM的效果,快速構建智能問答、總結、生成、分類等功能的LLM應用。結合數據標注和LLMOps能力,Scale能提供一整套企業AI應用开發解決方案。
圖表18:Scale AI的產品布局一覽和企業級生成式AI平台方案
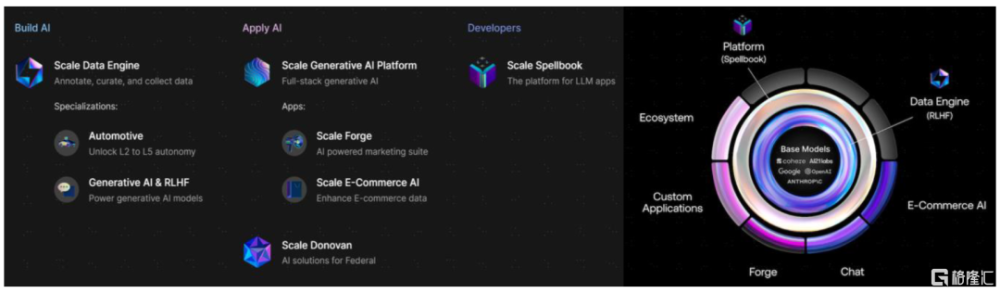
資料來源:Scale官網,中金公司研究部
模型訓練:Hugging Face
Hugging Face是當前最流行的AI/ML社區平台之一。LLM浪潮下,Hugging Face憑借高質量的Transformers模型庫和社區受到關注。用戶可以在Hugging Face上托管和共享ML模型、數據集、應用程序Demo,也可以直接基於平台構建、訓練和部署模型。截至7月底,Hugging Face上有超過26萬個預訓練模型,是ML領域的“Github”,超過5千家機構正在使用。
Hugging Face卡位關鍵,切入下遊MLOps探索變現。商業化層面,Hugging Face推出了個人和企業會員,個人會員每月9美元,在推理API和AutoTrain功能上享有優先級;企業版收費20美元/月/用戶,覆蓋整合了模型實驗、自動訓練、應用測試、最終上线部署等功能環節,同時提供更多企業級安全方面的支持。此外,AutoTrain(用戶僅需定義創建任務並上傳數據,系統自動選擇模型並訓練)、應用測試、模型推理功能亦支持單獨根據使用的硬件資源按用量收費。
圖表19:Hugging Face可以托管共享ML模型、數據集,也可以構建、訓練和部署模型
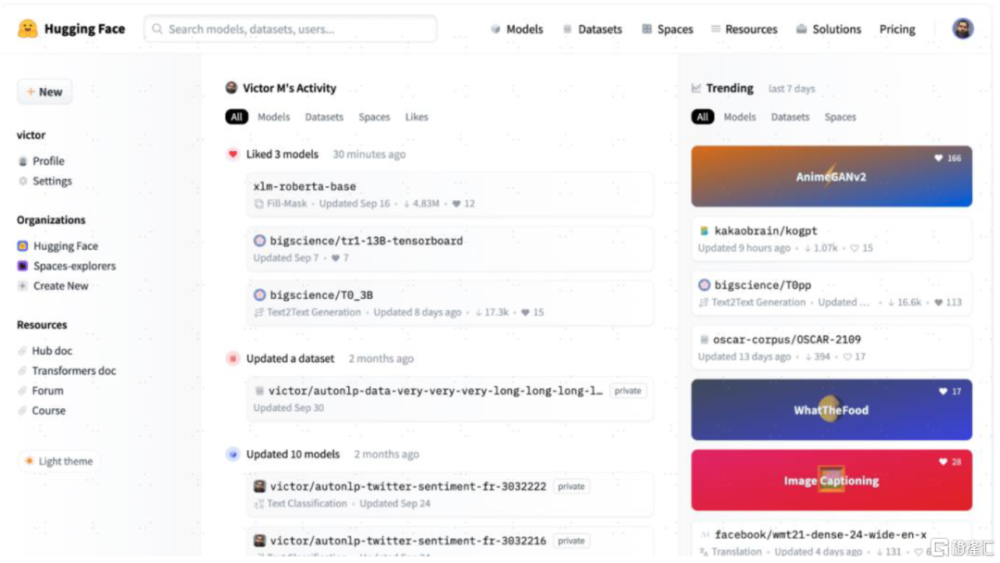
資料來源:Hugging Face官網,中金公司研究部
模型訓練&部署:Weight & Biases
Weights & Biases成立於2017年,從實驗管理到MLOps全生命周期。W&B創立靈感來源於創始人在OpenAI的一次實習經歷,初衷是希望研發一款方便AI/ML團隊協同的工具。因此W&B從模型實驗管理環節起家,並延伸至對數據准備、模型訓練和模型部署全生命周期的管理,爲技術人員提供追蹤模型版本、檢驗模型性能的功能,幫助其選擇最優版本的模型進行上线。官網最新顯示,目前其平台產品包含10大功能模塊,在實驗追蹤、協作可視化、模型版本管理、超參調節基礎功能之外,新增了ML工作流自動化、模型監控、LLM提示詞工程、ML應用开發環境等。
W&B支持雲和本地化部署,從定價看,Personal方案免費,只對個人用戶开放;Starter方案針對10人以下的小團隊,按照模型訓練時間範圍收取每用戶每月50-150美元不等的費用;Enterprise方案針對10人以上的公司、定制化報價。作爲MLOps模型管理賽道中的翹楚,公司受益於大模型發展紅利高速增長,OpenAI、DeepMind等都是其客戶。公司於2021年10月完成C輪融資,融資1.35億美元,估值超過10億美元。
圖表20:W&B產品擁有十大功能模塊,覆蓋機器學習全流程

資料來源:Weights & Biases官網,中金公司研究部
應用整合:Pinecone
商業化向量數據庫的領先實踐。Pinecone的CEO Edo Liberty曾在AWS領導Sagemaker產品,而後擔任亞馬遜AI Lab的負責人。在亞馬遜期間,Edo觀察到很多公司運用ML的難點不在於訓練或部署模型,而在於實時處理海量的向量數據,由此萌生創業念頭。2021年初Pinecone公司正式成立。Pinecone在成立之初就確立了閉源商業化的運營思路,按照存儲0.025美元每個月每GB,計算每小時0.1 - 1美元不等收費。目前Pinecone是海外最流行的向量數據庫之一,我們觀察到在大多數ML工作流上下遊廠商官網的適配名單中都有Pinecone的身影,在海外逐漸形成了“OpenAI+Pinecone”的AI應用开發技術棧共識。
Data+AI:Databricks
Databricks提供全球領先的數據科學計算分析平台,強調以數據爲中心的機器學習模式。Databricks是Spark官方發行版的开發公司,提供一體化的數據湖倉平台產品,實現對海量結構及非結構化數據的存儲、分析,並重視平台對數據科學、機器學習等AI相關工作流的支持,直接提供Machine Learning平台產品,涵蓋數據准備、模型訓練到模型投入生產的全流程,此外,Databricks還在2018年开發並开源了MLOps工具鏈項目MLflow,也是其ML平台的重要能力組件之一。
今年6月底召开的峰會上發布多項Data+AI技術進展。1)生成式AI相關進展主要集中在自然語言交互、AI應用开發工具鏈兩方面:Databricks發布SDK for Spark、LakehouseIQ,實現开發、查詢、檢索等場景的自然語言交互;發布Lakehouse AI旨在更高效便捷地組織AI應用开發工作流。2)數據管理平台基礎能力亦持續迭代:Databricks發布UniForm存儲格式與Hudi、Iceberg互通等。自研之外,Databricks亦通過收購擴大能力圈,近期AI相關交易頻繁。
國內AI Infra相關廠商巡禮
星環科技:Data+AI平台型廠商
提供完整大模型工具鏈、發布向量數據庫,助力企業打造垂類大模型、开發專屬AI應用。今年5月底公司舉辦技術峰會,並發布了多項Data+AI產品進展。Sophon LLMOps是在公司原有的Sophon MLOps平台基礎之上,針對大語言模型及其衍生數據、模型、應用問題進行相應功能增強後的大模型开發運維一站式工具鏈,賦能企業客戶微調垂類領域專屬大模型。同時,星環推出自研的企業級分布式向量數據庫Hippo,支持存儲、索引、管理海量向量式數據集,爲大模型補充實時、變化、專有領域的知識信息並能解決輸入token數量有限的問題,拓展大模型的時間和空間維度,賦能企業客戶構建基於大模型的個性化應用。除工具外,星環計劃推出兩個自研行業垂類大模型。
圖表21:基於星環產品棧的企業自有大模型應用構建流程示意圖
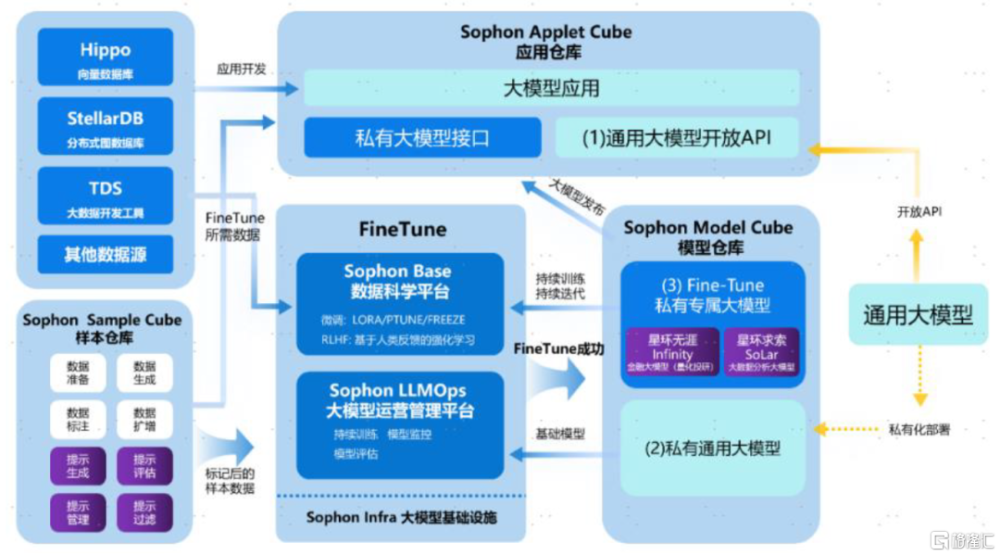
資料來源:WAIC大會,星環科技公衆號,中金公司研究部
第四範式(未上市):人工智能解決方案供應商,發布企業級類GPT產品
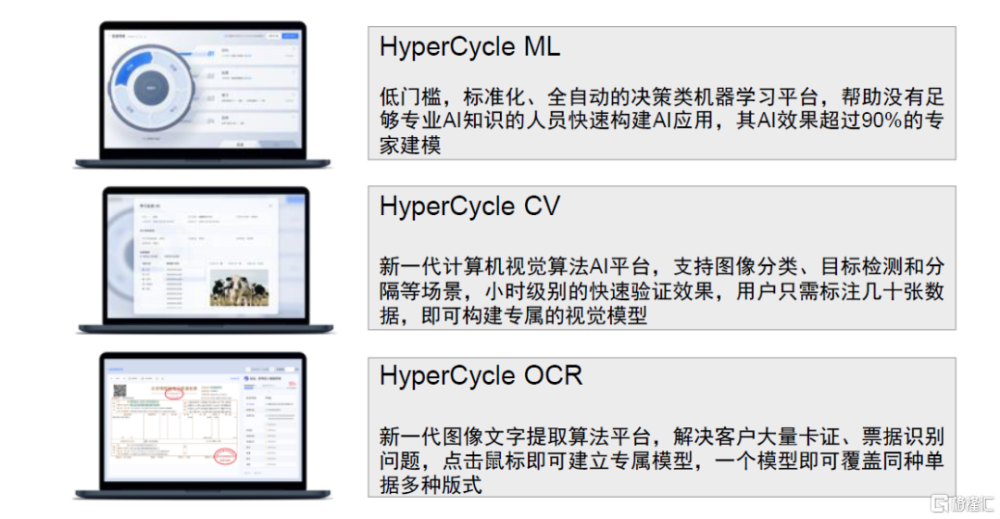
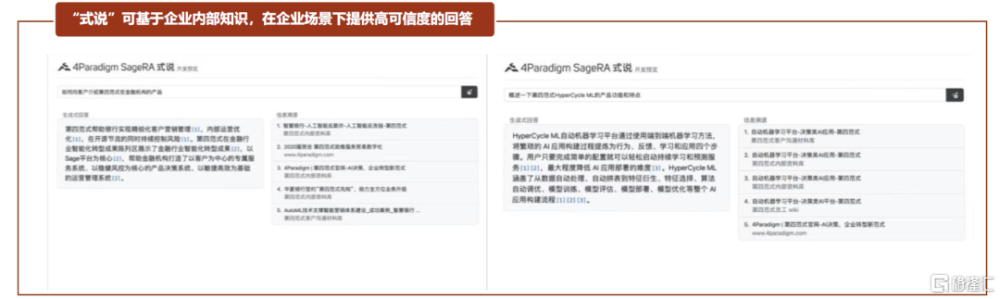
第四範式致力於爲企業提供以平台爲中心的AI解決方案。授人以魚不如授人以漁,除了提供AI業務應用之外,第四範式爲企業自行機器學習模型开發場景提供了企業級AI操作系統4Paradiagm AIOS和人工智能機器學習平台HyperCycle。LLM趨勢下推出企業級類GPT產品“式說”,助力企業利用內部知識解決問題。第四範式通過將類GPT語言模型與垂直領域知識進行融合,推出“式說”產品,旨在解決大型生成式語言模型在企業內部使用場景下的局限,滿足企業場景下的AIGC需求。“式說”主打三大產品特點:1)數據安全,通過私有化部署解決企業客戶對數據安全的顧慮;2)內容可信,“式說”基於企業內部數據庫,並且在提供回答時標注信息原始出處,增加了回答的可信性和可靠性;3)成本可控,“式說”算力成本相對可控,對數據標注量的需求較小。
圖表22:機器學習平台HyperCycle的三個子產品
資料來源:第四範式官網,中金公司研究部
圖表23:第四範式“式說”產品工作界面
資料來源:第四範式公司官網,中金公司研究部
雲知聲(未上市):發布山海大模型,賦能醫療等垂類場景
山海大模型發布,模型兼具通用能力與行業落地能力。雲知聲成立於2012年,是中國AGI技術產業化的先驅之一,2016年开始建立Atlas人工智能基礎設施,並據此开發了擁有600億個參數的專有大模型山海大模型,於2023年5月正式發布。山海大模型通用能力包括語言生成、語言理解、知識問答、推理能力、數學能力、代碼能力和安全合規能力;落地能力包括插件擴展、領域增強和企業定制,並支持企業私有化部署。
山海大模型可以從多個場景進行賦能,醫療是標杆賽道。雲知聲選擇的垂類包括智慧醫療(手術記錄撰寫助手、門診病歷撰寫助手)、商保智能理賠系統、雲貝銷售管理系統、山海知識管理系統(企業服務通用管理)、教育(山海AI口語)和智慧物聯(智能物業管家,貼心生活助手),應用具備橫向拓展性。
圖表24:雲知聲山海大模型能力概覽

資料來源:雲知聲山海大模型發布會,中金公司研究部
九章雲極(未上市):機器學習平台供應商
九章雲極定位人工智能基礎軟件供應商。九章雲極成立於2013年,專注數據科學平台的研發,提供機器學習建模能力、自動機器學習(AutoML)能力和實時數據計算能力。目前其核心產品主要有DataCanvas APS,是集數據准備、特徵工程、算法實現、模型开發、模型發布、模型生產化管理於一體的機器學習平台;和DataCanvas RT,支持分布式流數據實時處理,能夠將多種數據流接入實時處理並分析,將ETL、業務模型、機器學習、人工智能、可視化擴展到實時的大數據產品。
創新奇智:領先的“AI+制造”解決方案供應商,推出AInnoGC
企業級AI解決方案供應商,專注於“AI+制造”領域。創新奇智自研的“MMOC人工智能技術平台”具有深度學習能力,支持自動化、低代碼技術开發,以及“雲、邊、端”一體化部署交付,能端到端支持AI解決方案創新、研發和交付。同時,公司2018年成立以來聚焦於AI+制造領域,根據IDC數據[10],2022年創新奇智位居中國工業數據智能市場領導者象限,連續3年位居中國第二大AI工業質檢廠商。創新奇智推出以工業預訓練大模型爲核心的AIGC引擎奇智孔明AInnoGC。AInnoGC具有:1)適合工業場景的基礎大模型;2)完善的企業級Fine Tune機制和Prompt工程支持;3)豐富的API/SDK和MaaS服務等產品特徵。
漢得信息(未覆蓋):基於漢得融合中台HZERO,發布AIGC中台
發布AIGC中台,打造漢得AI知識、智慧交互平台。漢得基於融合中台HZERO,着手打造AIGC中台,預置“百模”對接和大量AIGC通用應用功能,並提供低代碼AIGC應用編排工具。具體組件來看,構建AIGC中台-知識庫組件,幫助企業更便捷地應用AIGC知識問答能力;提供智慧交互助手,預置語音、數據查詢、業務處理等能力,提供一個企業“AI助手”基礎版本,降低在各業務場景下構築AIGC應用的難度。
萬達信息(未覆蓋):自研AI中台,和華爲盤古合作打造行業垂類大模型
自研AI科技中台、參與制定MLOps能力成熟度模型。2022年的人工智能大會上,公司發布了AI科技中台,提供AI模型訓練和應用开發、部署、運維的全生命周期管理服務。此外,公司還參與制定全國首個AI模型开發管理標准《人工智能研發運營一體化(Model/MLOps)能力成熟度模型》系列標准[11]。面向智慧城市、醫療衛生等行業研發AI場景與平台,與華爲盤古合作打造行業大模型。萬達信息基於傳統主業政務信息化、醫療信息化等行業know-how結合AI能力,形成了數百項行業人工智能算法模型及多項AI解決方案與產品。此外,今年7月,公司與華爲雲籤署合作協議[12],計劃基於盤古大模型打造智慧城市、醫療健康垂類行業大模型,推動城市數字化轉型。
軟通動力(未覆蓋):天璇MaaS平台持續迭代,和百度、華爲大模型合作
軟通天璇MaaS平台迭代至2.0版本。軟通天璇2.0是基於昇思MindSpore人工智能框架打造的包含大模型技術底座、行業大模型及管理、場景大模型應用以及大模型一站式運營服務、數據治理和安全服務五要素的MaaS平台。與百度、華爲雲達成战略籤約,共築大模型產業化落地。今年7月,軟通動力和百度正式籤訂战略合作協議[13],推動文心千帆大模型平台與軟通天璇2.0 MaaS平台的互補優勢,共建面向工業、能源、制造、金融等多行業、多領域的智能應用。同月,軟通動力與華爲雲籤約,成爲盤古大模型的垂域模型標注訓練、服務交付、應用解決方案和昇騰遷移領域的合作夥伴,並計劃共同打造保險行業大模型。
海天瑞聲(未覆蓋):國內領先的數據標注廠商
海天瑞聲是國內領先的數據標注廠商。通過設計數據集結構、組織數據採集、對取得的原料數據進行加工,形成可供AI算法模型訓練使用的專業數據集,並以軟件形式向客戶交付。公司所提供的訓練數據涵蓋智能語音、計算機視覺、自然語言等領域,服務於人機交互、智能家居、智能駕駛、智慧金融、智能安防等應用場景。公司公告披露,截至2022年底,公司客戶累計數量810家,覆蓋科技互聯網、社交、IoT、智能駕駛、智慧金融、教育科研以及部分政企機構,包括阿裏巴巴、騰訊、百度、科大訊飛、海康威視、字節跳動、微軟、亞馬遜、三星、中國科學院、清華大學等。
Gitee(未上市):开源中國旗下代碼托管及DevOps平台
开源中國旗下代碼托管及DevOps平台。开源中國(Open Source China,OSC)是國內的一個开源技術社區,成立於2008年,官網數據顯示目前OSCHINA有600萬活躍开發者[14]。2013年,OSCHINA建立了代碼托管與DevOps平台“碼雲 Gitee”,爲廣大开發者提供團隊協作、源碼托管、代碼質量分析、代碼評審、測試、CI/CD與代碼演示等功能,官網數據顯示目前Gitee社區开發者超過1,000萬,托管項目超過2,500萬,匯聚幾乎所有本土原創开源項目[15],並於2016年推出企業版。
風險
技術進展不及預期:人工智能作爲前沿新興技術,仍處於技術的快速發展期,其進展有一定的不確定性,若技術進展不及預期,可能導致產業化進展緩慢。
應用落地不及預期:應用及商業化落地是人工智能能否順利走向下一階段的關鍵點,若國內應用及商業化落地節奏不及預期,對人工智能的進展將帶來負面影響。
行業競爭加劇:人工智能是產業的熱點,未來商業價值顯著,科技巨頭、初創公司均在此領域布局,未來垂類及應用層的行業競爭可能會進一步加劇。
[1]https://arxiv.org/pdf/2303.08774.pdf 《GPT-4 Technical Report》(OpenAI,2022)
[2]https://arxiv.org/pdf/2303.08774.pdf 《GPT-4 Technical Report》(OpenAI,2022)
[3]https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/
[4]https://arxiv.org/pdf/2304.02643.pdf 《Segment Anything》(Alexander Kirillov等,2023)
[5]《Will we run out of data? An analysis of the limits of scaling datasets in Machine Learning》(Pablo Villalobos等,2022);https://arxiv.org/pdf/2211.04325.pdf
[6]https://www.statice.ai/post/types-synthetic-data-examples-real-life-examples
[7]https://arxiv.org/pdf/1712.05889.pdf 《Ray: A Distributed Framework for Emerging AI Applications》(Philipp Moritz等,2018)
[8]https://docs.ray.io/en/releases-2.4.0/ray-overview/use-cases.html
[9]全稱爲IDEA研究院認知計算與自然語言研究中心
[10]https://mp.weixin.qq.com/s/WYGs59rNYz-EgxQLupO_GQ
[11]https://www.wondersgroup.com/05161643118326.html
[12]https://www.wondersgroup.com/07101657518645.html
[13]https://mp.weixin.qq.com/s/h0IYFNptWHwhUhLvGZcy-Q
[14]https://www.oschina.net/home/aboutosc
[15]https://gitee.com/about-us
注:本文摘自中金公司2023年8月8日已經發布的《人工智能十年展望(十二):詳解大模型時代的基礎軟件堆棧AI Infra》,分析師:
韓蕊 分析員 SAC 執證編號:S0080523070010
於鐘海 分析員 SAC 執證編號:S0080518070011 SFC CE Ref:BOP246
胡安琪 聯系人 SAC 執證編號:S0080122070070
王之昊 分析員 SAC 執證編號:S0080522050001 SFC CE Ref:BSS168
魏鸛霏 分析員 SAC 執證編號:S0080523060019 SFC CE Ref:BSX734
標題:AI大模型時代的“賣鏟人”:堆棧AI Infra
地址:https://www.iknowplus.com/post/22394.html







