中金:DeepSeek本地部署需求盛行,一體機硬件乘風而上
在AI進化論系列的前序報告中,我們深度分析了DeepSeek(下稱DS)的开源與技術創新,並探討訓練及推理硬件的需求變化。得益於模型工程優化的創新,DeepSeek-R1表現出領先的成本優勢和綜合性能,其开源策略也降低了AI前沿技術的獲取門檻,推升了下遊客戶對於AI大模型的本地部署需求,我們預期以一體機爲代表的私有化算力硬件景氣度有望向上。
摘要
C端場景:DeepSeek-R1蒸餾技術實現輕量化模型突破。R1蒸餾技術通過知識蒸餾,將復雜的“教師模型”(671B參數)的決策邏輯和特徵表徵能力遷移至輕量化的“學生模型”,生成了6個不同版本的蒸餾模型。這些蒸餾模型在保持大模型性能的同時,減少了對顯存、內存和存儲的需求,適合在資源受限的終端設備上運行。我們認爲,PC是承載本地模型的重要終端,更高性能端側模型的部署,有望成爲AI PC產業升級的有力推手。
B端場景:DS一體機提供私有化部署的全棧解決方案。DS一體機是一種專爲大模型應用和部署設計的集成計算設備,可基於NV或國產硬件實現,其中國產算力芯片由於契合主流下遊需求,或成爲主要算力支撐。
我們認爲,當前DS一體機的軟硬件協同仍面臨一些挑战,1)主流國產AI芯片缺少對FP8精度的支持,如果採用FP16或BF16精度,硬件效率將下降;2)爲了在單台8卡服務器上實現全參數DeepSeek-R1模型的部署,一體機廠商需要進行定點量化,需在算力效率和模型效果間尋求平衡。但得益於DS模型優勢,以及一體機本地私有化、快速部署等優勢,DS一體機國內市場空間有望快速提升。DS一體機在滿足企業數據安全和合規要求方面具有優勢,對於政府、金融等數據安全要求較高的行業適配度高,我們預估樂觀情形下25年DS一體機市場規模有望達到540億元。
風險
生成式AI模型創新/模型本地化部署需求/AI算力硬件技術迭代不及預期。
DeepSeek开源大模型推動私有化部署新趨勢
中國企業DeepSeek(以下簡稱DS)全面开源的創新成果引發了市場對生成式AI技術發展與算力硬件需求的熱烈討論,其V3版本模型以僅1/10訓練成本消耗便獲得了與海外領先模型GPT-4o/Llama3.3對標的能力,並通過對V3同一基礎模型的後訓練獲得R1模型,R1在後訓練階段大規模使用了強化學習技術,在僅有少量標注數據的情況下,提升了模型推理能力,在數據、代碼、自然語言推理等任務上,性能比肩OpenAI o1正式版。此外,DS於2025年2月24日正式啓動“开源周”,連續5天每天开源一個項目,豐富AGI領域的开源生態。
我們認爲,高質量的开源模型有望推動AI大模型的能力邊界探索,並加速AI應用落地,利好作爲底層支撐的算力硬件需求。在此前的AI進化論系列報告中,我們探討了訓練硬件市場需求的變化,提出DS的創新是在命題作文下(中美貿易摩擦背景下AI硬件採購受限)的較優解,並未提出任何反“Scaling Law”的趨勢,傑文斯悖論(Jevons Paradox)爲DS帶來的“大模型平權”創新行爲影響指明了方向——全行業算力資源使用效率的提升,可能會創造更大的需求。在應用推理方面,我們看到DS在C端表現亮眼,根據Data.ai數據,DS APP自2025年1月11日發布以來,下載量呈指數級增長,1月20日至26日單周下載量達170萬次,次周(1月27日至2月2日)達到1576萬次,環比增長超800%,截至2025年2月24日,累計下載量已突破4000萬次;在B端,DS的开源屬性與模塊化設計加速了其在垂直領域的滲透,包括政務、醫療、汽車、工業、金融等領域,根據愛分析[1]的統計數據,截至2025年2月21日,已有45%的央企完成了DS模型的部署。
圖表1:DeepSeek APP下載量
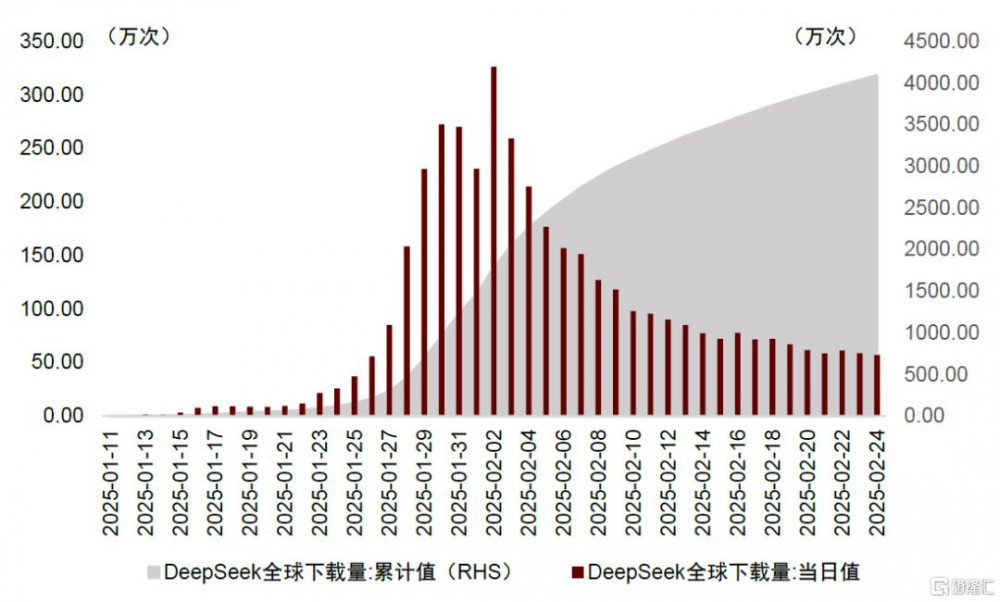
資料來源:Data.ai,中金公司研究部
大模型雲端部署帶動的雲端算力需求提升,頭部雲廠商進入資本开支上行周期。大模型的雲端部署以彈性算力和快速迭代見長,我們認爲,R1模型作爲高質量、低成本的模型代表,开發者通過雲廠商調用API、部署模型並开發應用,有望推動雲資源消耗量提升。根據阿裏巴巴財報,AI推動阿裏雲收入增速持續提升,4Q24季度收入重回13%的同比雙位數增長,AI相關產品收入連續六個季度實現三位數同比增長,單季度資本开支44.1億美元,環比增長81%;業績電話會上[2]集團CEO表示,未來三年雲和AI基礎設施投入預計超過過去10年總和,AI capex指引積極。
我們認爲,DS部署不止於雲端,本地化私有部署同樣具備廣闊的應用場景,私有化部署方式使得企業及個人能夠完全掌控自身的數據環境,有力保障數據安全,降低數據泄露和遭受外部幹擾的風險。
► C端呼喚雲端協同範式:面向消費級AIPC等場景,"雲端協同"成爲優化體驗與隱私保護的必然選擇。通過將非敏感任務卸載至雲端,可突破終端算力限制,支撐復雜模型推理;同時端側部署輕量化模型處理隱私數據,既滿足GDPR等法規要求,又減少網絡依賴帶來的延遲抖動及可能的體驗中斷。
► B端部分行業剛性需求驅動本地化部署:部分企業級市場對私有化部署呈現強依賴性,1)尤其是金融、醫療等行業公司,處理較多高度敏感的數據,本地化部署能夠防止數據離开企業內部網絡,降低數據被外部惡意行爲者竊取或濫用的風險;2)定制化需求旺盛,需針對行業知識庫進行微調訓練,從而推動DS大模型形成容器化交付、私有化調優的完整解決方案體系,滿足企業對模型所有權與控制權的雙重訴求。
我們認爲,DeepSeek R1具有技術开源和成本控制的核心特點,降低了企業及個人部署高水平AI大模型的門檻,有望推動包括DeepSeek一體機在內的本地私有化部署需求快速提升。
► 模型性能領先:DeepSeek R1在性能上對標國際前沿模型,在數據、代碼、自然語言推理等任務上,性能比肩OpenAI o1正式版。
► 开源策略:在閉源模式下,企業依賴大模型廠商的服務訂閱,成本與技術的不透明度高。對比之下,DeepSeek採用MIT开源協議,允許企業免費商用和二次开發,同時,在最新“开源周”,DeepSeek陸續开源了FlashMLA、DeepEP、DeepGEMM、並行優化策略等項目,涉及大模型推理框架、MoE模型、FP8計算性能等方面提升,降低了前沿AI技術的獲取門檻。
► 硬件成本:在本系列的前序報告中,我們對DS團隊最新开源成果中的創新進行深入分析,DS團隊通過MLA(多頭潛在注意力機制)、NSA(原生稀疏注意力機制)、Prefill/Decode分離、高度EP等技術創新,實現推理成本下降;同時,通過知識蒸餾等技術,實現參數量分別爲1.5B、7B、8B、14B、32B和70B的蒸餾版模型,在保持大模型性能的同時,減少了對顯存、內存和存儲的需求,進一步降低本地私有化部署的硬件成本。
► 硬件適配優化:DeepSeek早期的模型訓練基於NV硬件實現,例如DS團隊开源了MLA相關內核(Kernel),解密MLA結構在NV硬件上的具體實現。但我們看到,國產主流GPU廠商已宣布適配DeepSeek,爲基於國產卡的DeepSeek一體機的快速落地奠定了基礎,而DS團隊基於NV硬件的優化方式开源也爲开發者優化適配其他硬件提供了思路。
綜上所述,DeepSeek大模型的私有化部署需求迫切,本篇研究我們將聚焦DeepSeek本地私有化部署的硬件配置及技術難點、一體機的需求空間及產業鏈。
蒸餾模型利好C端部署,一體機方案收獲B端青睞
C端:DeepSeek-R1+蒸餾技術,輕量化模型推動AI端側部署
DeepSeek-R1蒸餾:“小模型”蕴含“大智慧”
知識蒸餾(Knowledge Distillation)的本質是知識遷移和壓縮,其核心在於將復雜“教師模型”的決策邏輯與特徵表徵能力遷移至輕量“學生模型”。根據DeepSeek-R1技術論文[3],使用671B參數量的DeepSeek-R1(教師模型)生成80萬條高質量訓練數據,涵蓋數學推理、編程、科學問答等場景任務,並通過規則過濾混合預研、冗余段落和代碼塊,最終數據樣本中包括最終答案和多專家協作的決策邏輯;通過知識蒸餾技術,將671B參數大模型的復雜推理模式(如長鏈思考、自我驗證等)遷移至輕量模型(學生模型),從而形成參數量爲1.5B、7B、8B、14B、32B、70B的6個不同版本蒸餾模型。
圖表2:“教師模型”通過知識蒸餾後得到“學生模型”
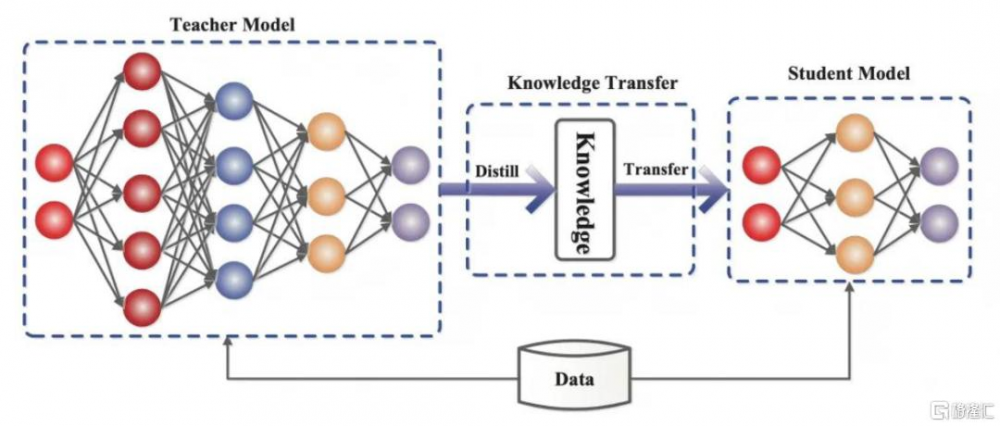
資料來源:Gou, J., Yu, B., Maybank, S.J., & Tao, D. (2020). Knowledge Distillation: A Survey. International Journal of Computer Vision,中金公司研究部
DeepSeek-R1蒸餾版模型的推理性能超越同規模傳統模型。DeepSeek蒸餾技術融合了數據蒸餾與模型蒸餾,採用監督微調(SFT)方式,利用DeepSeek-R1生成的80萬個數據樣本對基礎模型(如Qwen和Llama系列)進行微調,並且在架構優化中增加層次化特徵提取、多任務適應性、參數共享與壓縮等設計,實現了高效的知識遷移。得益於模型結構優化和蒸餾技術的應用,蒸餾版本模型在多個推理基准測試中表現優異,根據DeepSeek-R1技術論文,DeepSeek-R1-Distill-Qwen-7B在AIME 2024基准測試中實現了55.5%的Pass@1(模型首次生成答案即正確的概率),超越了QwQ-32B-Preview,DeepSeek-R1-Distill-Qwen-32B在AIME 2024上則實現了72.6%的Pass@1,在MATH-500上實現了94.3%的Pass@1,超過了OpenAI-o1-mini。
論文還進一步對比了蒸餾模型和基於Qwen-32B-Base模型、使用數學、代碼和STEM領域數據進行了超過1萬步大規模強化學習(RL)訓練而來的小模型,結果顯示,在所有推理基准測試中,蒸餾模型DeepSeek-R1-Distill-Qwen-32B均優於後者(DeepSeek-R1-Zero-Qwen-32B),且耗費更少的計算資源,兼具經濟性與有效性。我們判斷主要得益於蒸餾的知識遷移優勢、更高效的學習過程、以及繼承了教師模型一部分泛化能力。
圖表3:DeepSeek-R1蒸餾模型與其他模型推理性能對比
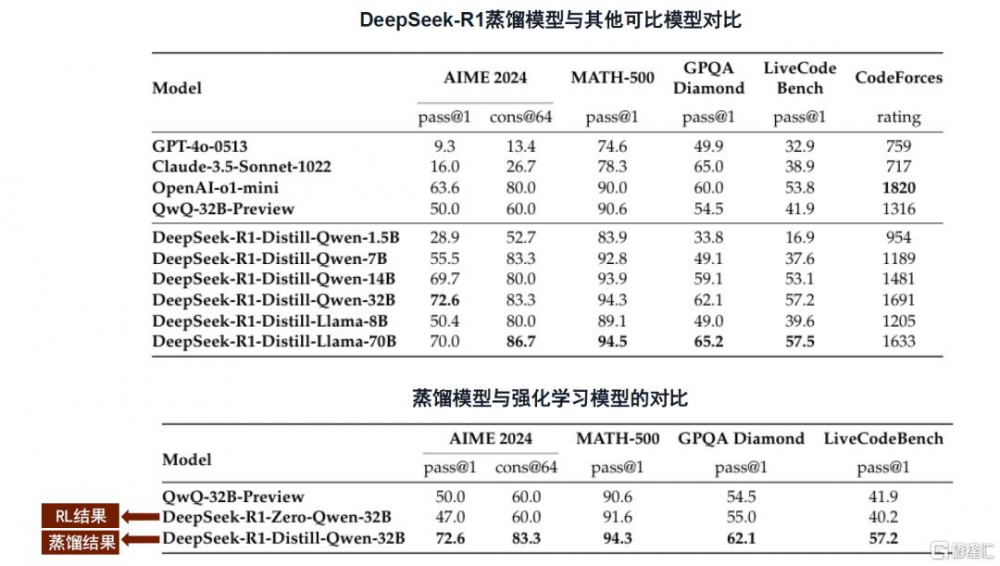
注:Pass@1指模型首次生成答案即正確的概率,主要評估模型的及時響應能力;Cons@64是通過64次獨立生成答案後取多數投票結果作爲最終答案的評估指標,主要評估多次採用後的穩定性和一致性。
資料來源:DeepSeek-R1技術報告,中金公司研究部
DeepSeek-R1蒸餾模型本地部署的硬件要求?
傳統大模型在推理時需要大量計算資源、以及足夠大的內存和存儲空間,如滿血版671B參數量的DeepSeek-R1在採用FP8訓練(精度系數爲1)時,顯存需求約850GB,若採用INT4量化,只考慮加載模型參數仍需佔用313GB的顯存,對內存和硬盤空間的要求也較高,超出PC、手機等終端設備的硬件承載閾值。蒸餾模型在盡量保持大模型性能的基礎上,減少了對顯存、內存和存儲的需求,更加適合搭載於資源受限的終端設備,適用於C端場景。
DeepSeek-R1蒸餾模型的本地部署需要根據模型大小和計算需求,選擇合適的終端硬件配置。蒸餾後的DeepSeek-R1模型可以通過Ollama和AnythingLLM實現PC本地部署。根據聯想官網信息[4]以及ollama[5],我們梳理了運行不同版本參數蒸餾模型所需的硬件配置:
若只運行1.5B的超輕量模型,具備實時基礎問答、文本情感分析等功能,集成顯卡的配置基本足以支持;若需要執行中等復雜度任務如文本摘要、翻譯、圖像描述生成等,需部署7B或者8B端側模型,INT4量化假設下的最低顯存要求需達到4-5GB,普通的消費級硬件(如RTX 3060/3070/4060等)可支持運行,推薦內存配置爲16GB+,硬盤容量大於10GB;若要部署14B中型模型,用於跨模態理解、復雜代碼生成、本地知識庫檢索等任務,需升級硬件配置,採用RTX 4090/A5000或更高顯存的顯卡、以及32GB+的內存和15GB+的硬盤存儲;而對於32B或70B較大參數量模型的本地部署,以實現多模態任務處理、科研數據分析、復雜語義理解等任務,對PC硬件提出了更高要求,通常需要配置專業級GPU(NVIDIA A100/H100,或採用多卡並行,INT4量化假設下最低顯存要求接近40GB,推薦顯存大小爲80GB,並提出更大的內存和存儲、更高的散熱和電磁屏蔽等要求。
PC是承載本地模型的重要終端,更高規格、性能端側模型的部署正在成爲AI PC升級的有力推手。2月25日,聯想[6]推出全球首批端側部署DeepSeek的AI PC產品——YOGA AI PC元啓系列,在消費級設備上實現70億參數端側模型的流暢運行,用戶文檔的總結、翻譯、撰寫等操作無需調用雲端大模型即可完成,提升了推理效率,充分保障了數據隱私與離线可用性,還可以根據用戶個人需求進行定制化訓練。
我們認爲,AI PC的換機動力仍有提升空間,此前主要受制於端側模型能力有限、國外廠商API調用限制、以及價格高昂;DeepSeek-R1基於知識蒸餾的輕量化模型在本地推理性能上表現優異,以更小參數量實現接近原模型的精度,降低了端側AI任務的門檻。我們認爲,PC作爲生產力工具,其用戶追求性能體驗,隨着應用場景逐步擴展到多模態任務處理、復雜推理等領域,用戶對更優性能、更高規格本地模型部署的需求攀升,傳統PC的算力與內存配置逐漸成爲瓶頸,硬件升級趨勢明確,端側模型進化與硬件迭代形成飛輪效應、有望加速AI PC滲透。
圖表4:不同參數量裁剪版DeepSeek-R1模型本地部署的硬件要求
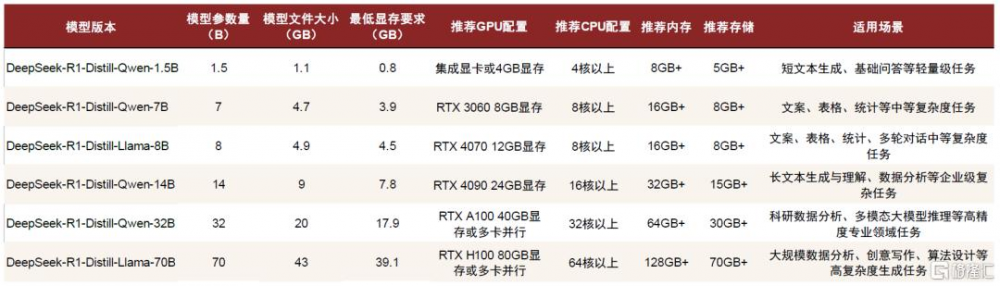
注:1)模型文件大小來源於Ollama官網模型下載文件的大小;2)最低顯存要求的計算方式:假設均採用INT4(4比特)量化,每個參數佔用0.5字節,且考慮到實際部署時需預留額外顯存用於存放中間計算和框架开銷,這部分額外开銷一般佔模型本身大小的20-50%,我們採用20%保守計算,顯存需求(GB)≈參數規模(B)*每個參數的字節數/ (1.024)^3)*(1+20%)
資料來源:Ollama官網,CSDN,聯想集團官網,中金公司研究部
B端:AI私有化部署新趨勢,DeepSeek一體機的全棧式解決方案
DeepSeek一體機重構本地私有化AI部署模式
DeepSeek-R1全參數模型擁有671B參數,相較於32B參數的蒸餾版,展現出更強的數學、代碼及邏輯推理能力,爲B端用戶所需要;但也對系統顯存容量、顯存帶寬、互連帶寬、延遲等提出了更高的要求。根據安擎[7],MoE模型運行所需的顯存可以由公式——模型參數量×精度系數+激活參數量×精度系數+10%~20%其他消耗——計算得到,對於DeepSeek R1而言,模型參數爲671B,單次激活專家參數量爲37B,模型主要採用FP8訓練(精度系數爲1),則所需的顯存約爲850GB。
圖表5:DeepSeek-R1模型性能表現
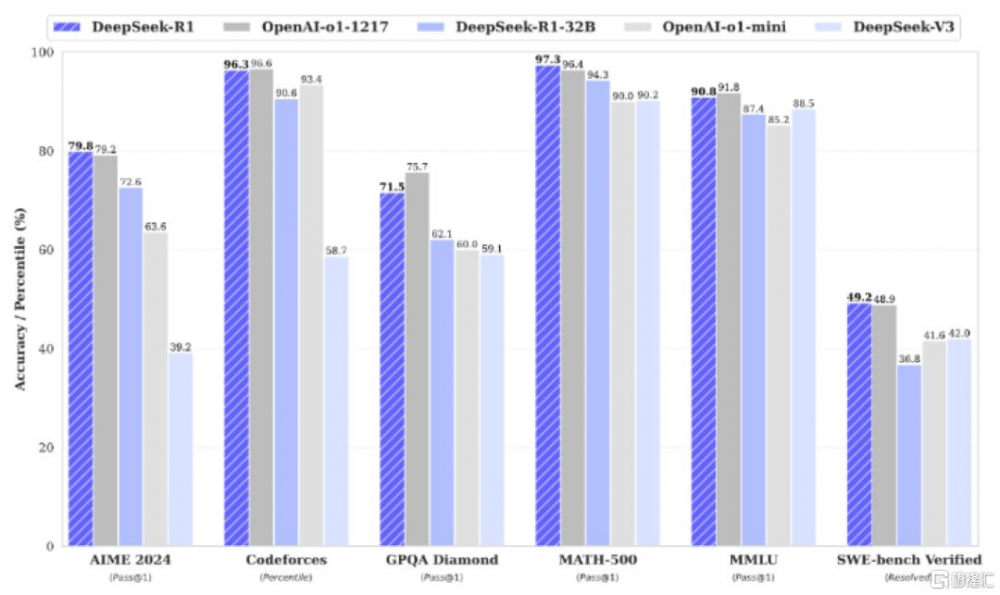
資料來源:DeepSeek,中金公司研究部
一體機是一種專爲大模型應用和部署而設計的集成計算設備,形成“开箱即用”的智能算力解決方案。一般而言,大模型的私有化部署工作量大且部署流程較長,前期在硬件端需要對AI服務器、存儲設備、網絡設備等ICT硬件進行選購及配置,在軟件端需要將大模型與硬件環境適配,處理兼容性等問題,在部署階段需要經歷系統調試等流程,後期還需要專業的運維團隊進行維護管理。相比而言,大模型一體機作爲“軟硬協同、开箱即用”的智能化基礎設施,高效耦合計算、存儲、網絡等硬件設備、大模型微調部署軟件平台和預置大模型,能夠縮短部署周期、深度結合場景、降低落地門檻,重構本地私有化AI部署模式。
► 深度優化的高性能硬件:大模型一體機通過適配專用AI芯片,針對大模型算法進行深度優化,可以充分釋放AI芯片性能;通過配置大容量內存和高速存儲,支持大模型的加載和運行,提高數據讀寫速度。目前,基於昇騰、百度昆侖芯等國產芯片打造的DeepSeek一體機,都對推理性能進行了優化。中國電信[8]推出的息壤智算一體機,基於華爲昇騰芯片,借助自研推理加速引擎,充分發揮DeepSeek性能;浪潮元腦R1推理服務器[9]支持昆侖芯AI芯片並進行深度優化,解決DeepSeek-R1全參數模型部署中的資源瓶頸,從而提升推理效率。
► 內置多種基座大模型:目前的大模型一體機可以提供包括DeepSeek系列、LLaMA系列、Baichuan系列、Qwen系列等在內的多種主流开源大模型,企業用戶可以根據特定應用場景需求,對預置模型進行微調及增量訓練,降低AI大模型的落地門檻。紫鸞大模型一體機[10]預裝DeepSeek R1、Baichuan2、Qwen2、GLM-4、LLAMA等主流大模型及完整運行環境,通過圖形化界面,用戶可在數分鐘內啓動模型並投入使用。
► 全棧工具鏈:大模型一體機通過集成AI全流程开發工具,實現從數據處理、模型訓練到推理部署的全棧式开發,提高模型訓練效率。同時,通過外掛用戶專屬知識庫,結合檢索增強技術,實現專業領域的知識問答,爲企業提供定制化、便捷化、場景化的AI服務;通過可視化管理工具,實現硬件組網、資源監控、故障定位清晰可見,降低運維門檻。
圖表6:大模型一體機參考架構
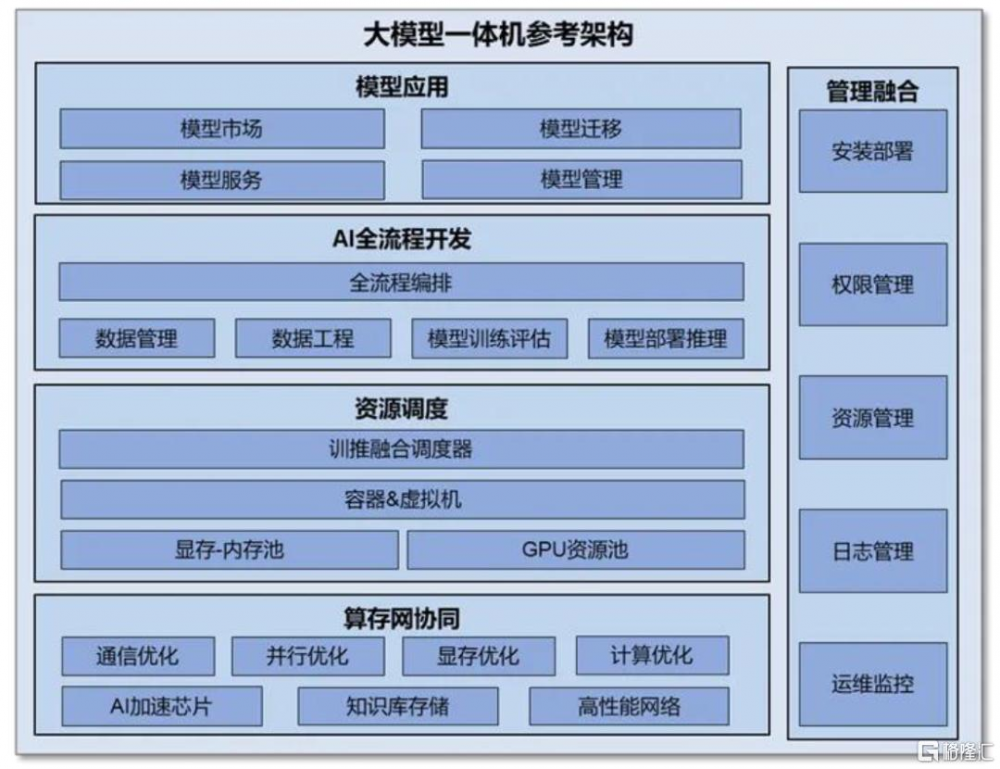
資料來源:中國信通院,中金公司研究部
DeepSeek一體機軟硬件協同難點
當下主流國產AI訓練芯片缺少對FP8精度的支持是運行DS模型的一大問題,採用16位精度單元計算會大幅降低效率。DeepSeek採用的是FP8混合精度,但當前主流的國產AI訓練芯片缺少對FP8精度的支持,如果採用BF16或者FP16來計算,理論上對精度影響較小,但是對計算和顯存的硬件需求幾乎增加一倍。採用上節相同計算方法,採用FP8精度部署671B的DS大模型,顯存需求約爲850GB;如果採用FP16或者BF16部署DS大模型,顯存需求約在1.5T以上,以阿裏雲百煉專屬版AI訓推一體機[11]爲例,單機部署全精度16/8/4bit下高並發滿血版DeepSeek-R1/V3,部署16卡,顯存達到1,536GB。
圖表7:中國AI芯片顯存大小及支持的數據精度
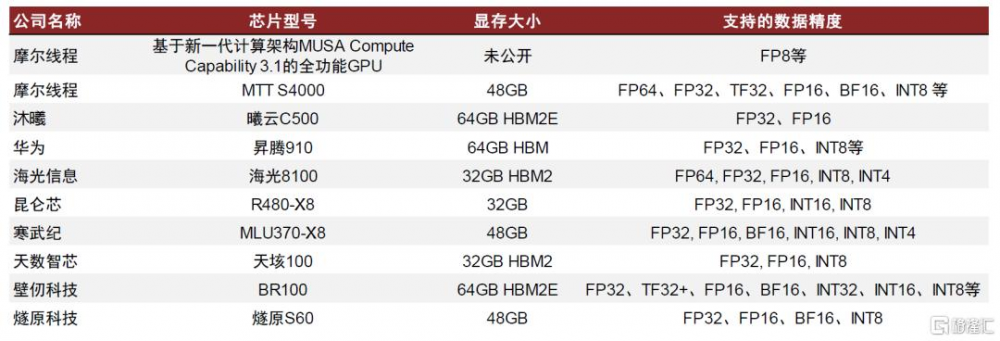
資料來源:摩爾线程官網及公衆號,半導體產業縱橫,京東,華爲,中國算力大會,海光信息,昆侖芯,寒武紀,雲軒Cloud Hin,Hot Chips,燧原科技,中金公司研究部
圖表8:百煉專屬版AI訓推一體機

資料來源:阿裏雲政企公衆號,中金公司研究部
DeepSeek R1模型全參數配置的顯存要求較高,通過定點量化壓縮顯存佔用。以FP8精度部署DS R1全參數模型所需的顯存爲850GB,同時,由於大部分國產AI芯片只支持INT8、FP16、FP32等格式,如果採用FP16精度,單機顯存要求將進一步提升至1.5T顯存以上,超出單台8卡AI服務器的顯存範圍。爲了在單台8卡服務器上實現671B全參數DeepSeek R1模型,廠商需要進行定點量化,即通過降低模型中的參數精度(如從16位浮點數轉換爲8位)來減少模型的大小與計算復雜度,從而降低顯存佔用並提高吞吐效率,並保持可接受的精度損失範圍。以INT 8量化——即將模型從浮點數轉換爲8位整數——爲例,模型的權重和激活值會經過縮放、偏移等量化過程,以盡量多地保留原始浮點數的信息,在推理過程中,這些定點量化值會被反量化回浮點數進行計算,然後再量化回INT8進行下一步。
圖表9:INT8量化示意圖
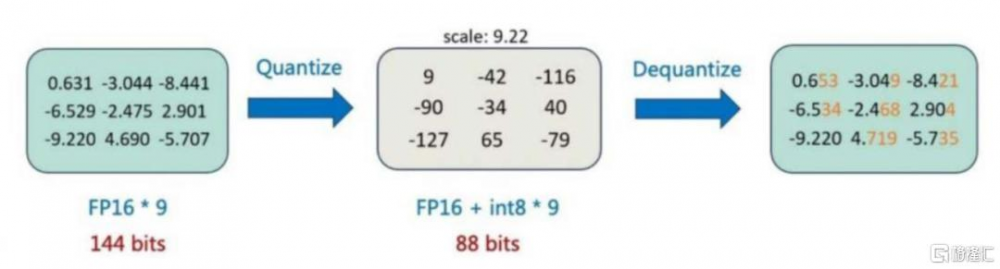
資料來源:53AI,中金公司研究部
DeepSeek一體機並非AI服務器硬件與大模型的簡單疊加,可能會遇到無法部署或資源浪費的問題,一體機廠商需要圍繞AI芯片與大模型進行深度適配,並在優化算力效率與保障模型效果之間尋求平衡點。
DeepSeek一體機迎合本地化部署需求,市場空間廣闊
滿足本地化及快速部署需求,DeepSeek一體機市場空間廣闊
DeepSeek一體機私有化部署,滿足企業數據安全及合規需求。《網絡安全法》、《個人信息保護法》要求企業進行數據分類管理、備份加密、部分關鍵敏感信息須在境內存儲;此外,在一些特定行業,如金融、醫療、能源等,有專門的數據安全和隱私保護行業標准和規範,政府部門也存在敏感信息的本地化需求。DeepSeek一體機部署在企業內部機房等環境,企業對於硬件設備擁有完全的控制權,數據僅在公司內部網絡流轉,與外部網絡實現物理隔離或嚴格的邏輯隔離,避免了數據在公共網絡環境中傳輸和存儲可能面臨的被攔截、竊取等風險,提升了數據安全性;此外,DeepSeek一體機可以根據行業特點和要求進行定制化配置和功能开發,滿足行業標准中對於數據安全、審計、備份恢復等方面的規定,例如金融行業對交易數據的完整性和保密性要求,醫療行業對患者隱私數據的保護要求等。
圖表10:“雲+大模型”環境下數據安全挑战
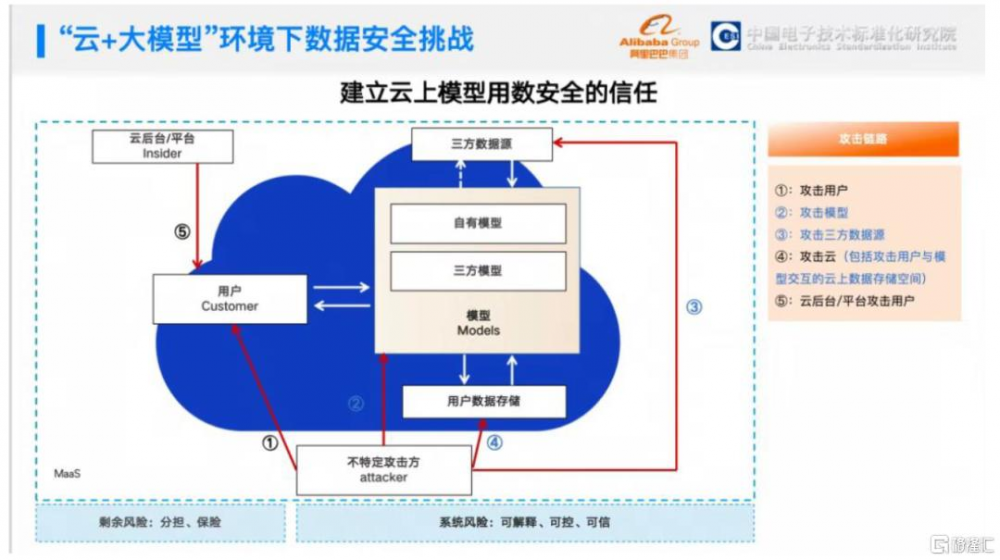
資料來源:阿裏巴巴人工智能治理研究中心公衆號,中金公司研究部
DeepSeek一體機降低AI大模型的部署門檻。政企客戶行業分布廣泛,部分企業客戶开發經驗有限,通常需要全面的售前售後服務支持。目前,DeepSeek一體機廠商提供兩項解決方案:“开箱即用”的部署模式、通過集成工具降低AI开發和應用門檻。
► “开箱即用”部署模式:實現DeepSeek一體機小時級一站式交付、即插即用,配備一個大模型开發平台,綜合覆蓋多元多模數據處理、RAG(檢索-生成)以及數據安全等關鍵環節。廠商將結合客戶的具體需求和數據,對大模型進行开發優化,並配備ISV在現場進行數據治理、模型微調等復雜流程的整合和部署,以加速企業AI應用的落地。對比傳統的數據准備、清洗、治理和跨平台的訓練、微調生態流程,DeepSeek一體機將幫助企業節約大量迭代時間。
► 自主微調模式:針對企業自主微調大模型的需求,DeepSeek一體機集成主流有效的微調方法,內置多種大模型計算框架和基礎模型,微調採用低代碼可視化界面,內置了如Lora、SFT等多種微調框架和優化參數,有效降低復雜性和技術門檻,企業用戶能根據具體需求和數據特性選擇合適的技術、快速开發和部署模型應用。
減弱B端用戶對雲的依賴。公有雲可以爲企業提供短期內大規模的計算資源,同時支持與雲服務提供商自有的AI技術進行協作,從而滿足企業推理需求,但同時也存在穩定性、總成本的風險。穩定性方面,公有雲的平穩運行取決於雲環境及通信網絡,宕機事件或網絡不穩定都會導致推理業務中斷;總成本方面,對於長期模型推理的使用者,雲服務的費用隨時間不斷攀升,且在後期升級時,成本的不可預見性可能會加重企業的資金負擔。DeepSeek一體機採用單次买斷制,有利於企業用戶控制資本开支及AI部署成本。
DeepSeek一體機市場空間測算
AI大模型能夠有效提升政府工作效率,深圳市福田區[12]已上线11大類70名“數智員工”,滿足240個政務場景的需求,其中,個性化定制生成時間從5天壓縮至分鐘級,公文格式修正准確率超95%,審核時間縮短90%,錯誤率控制在5%以內。此外,醫療、金融等行業及央國企由於涉及敏感信息,對於數據安全的要求較高。
我們認爲,DeepSeek大模型一體機作爲开箱即用的私有化部署方案,在實現快速部署AI大模型的同時,能夠滿足對於公民信息、關鍵業務數據等數據安全保障的需求,有望受益於政府及企業的AI轉型趨勢。
DeepSeek一體機有望達到500億元級別市場空間。根據IDC,2025年中國服務器市場出貨量有望達到488萬台,政府、金融、公共事業、醫療等6大政企行業由於涉及隱私數據,存在本地私有化部署需求,2021年上述行業佔中國服務器市場需求約28%。我們預計,樂觀情景下2025年上述行業約5%的需求轉向DeepSeek一體機,則需求達到7萬台,市場規模有望達到540億元。
圖表11:2025年國內DeepSeek一體機市場空間測算
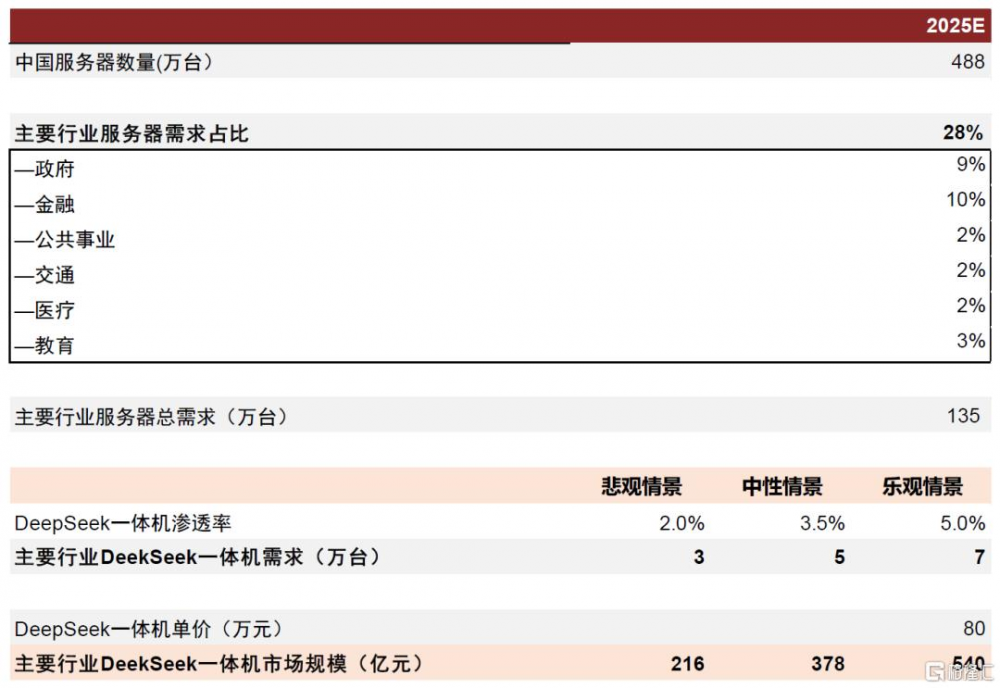
注:DeepSeek一體機單價因配置不同而存有較大差異,測算中採用中位數水平單價 資料來源:IDC,中金公司研究部
國產算力產業鏈全方位適配DeepSeek,服務器及雲廠商擁抱一體機趨勢
國產算力產業鏈全方位適配DeepSeek,一體機方案中國國產AI芯片成爲重要底座。一方面,國產主流GPU廠商已宣布適配DeepSeek,並結合AI infra廠商算法優化,提供性能較優的推理體驗,例如2月1日硅基流動[13]宣布與昇騰雲合作推出DeepSeek R1/V3推理服務,據官方稱在自研推理加速引擎賦能下可實現持平全球高端GPU部署模型的推理效果。
此外,整機廠商及IDC雲廠商也積極適配DeepSeek,根據芯東西統計,2025年2月1日-14日短短兩周時間內,即有24家國產AI芯片企業、6家國產GPU企業、6家國產操作系統企業、86家國產服務器或一體機廠商以及82家中國雲計算廠商及AI基礎設施廠商,合計超過160家國產算力產業鏈企業宣布完成DeepSeek適配。另一方面,目前已有的DeepSeek一體機方案中,昇騰等國產GPU也成爲重要的底層算力支撐。
我們認爲,DeepSeek一體機有望加速AI應用落地,同時,有望推動AI本土產業鏈性能的升級共榮。
圖表12::國產算力硬件產業鏈已全面適配DeepSeek大模型(不完全統計)
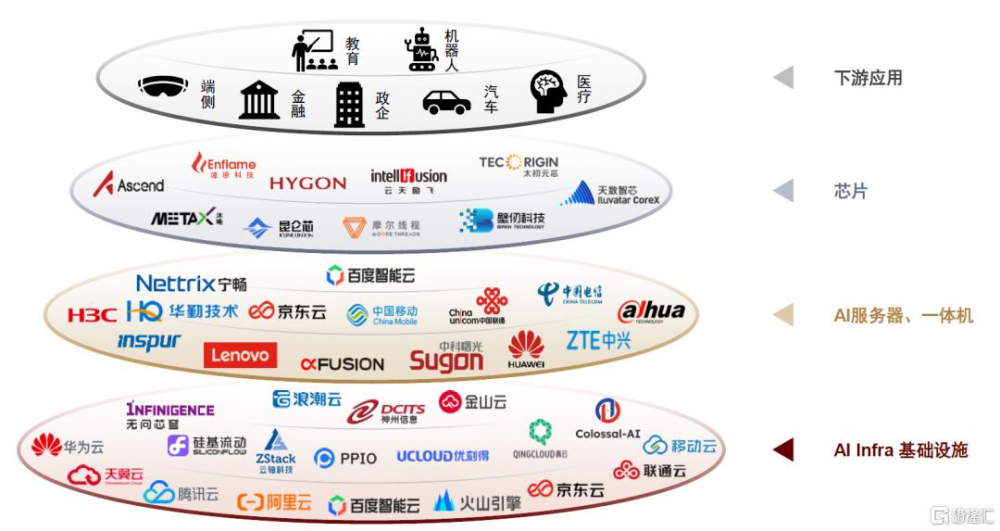
資料來源:公司公告,芯東西,中金公司研究部
算力硬件廠商、雲廠商等均推出DeepSeek一體機,積極擁抱私有本地部署趨勢。我們看好整機環節頭部的一體機供應商。
圖表13:DeepSeek一體機在位廠商布局一覽
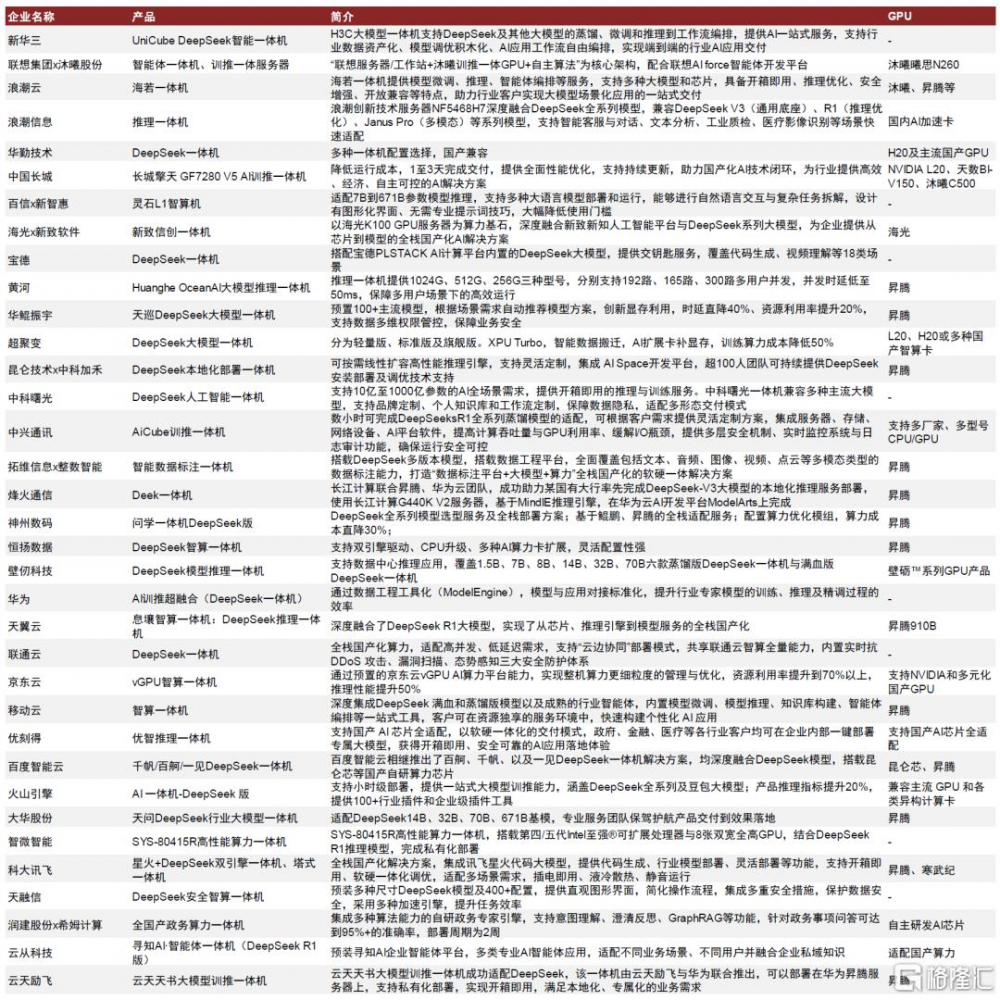
資料來源:新華三官網,c114,長城官網,新智惠想公衆號,寶德服務器公衆號,黃河科技集團公衆號,華鯤振宇公衆號,超聚變公衆號,拓維信息公衆號,中科加禾公衆號,中科曙光公衆號,中興通訊官網,烽火通信公衆號,恆揚數據公衆號,壁仞科技公衆號,天翼雲官網,CWW,京東雲微信公衆號,移動雲官網,優刻得官網,百度智能雲官網,火山引擎公衆號,IT之家,浪潮集團官網,浪潮計算機公衆號,大華股份公衆號,科大訊飛公衆號,天融信官網,神州數碼官網,華勤技術公衆號,新致軟件公衆號,智微智能公衆號,中金公司研究部
相關風險
生成式AI模型創新不及預期。本次DeepSeek模型獲得業內廣泛關注的核心原因之一在於大量細節上的算法創新以及硬件工程創新。如果生成式AI模型技術創新停滯,將直接影響技術迭代與產業升級進程。
模型本地化部署需求不及預期。B端及C端對於AI大模型本地化部署需求受到AI大模型技術迭代、硬件部署成本、IT採購預算等多方面的影響。如果上述因素出現擾動導致下遊模型本地化部署需求不及預期,或對AI PC及一體機市場空間造成負面影響。
AI算力硬件技術迭代不及預期。GPU的算力水平、顯存大小及生態建設均有可能成爲DeepSeek本地部署的制約因素。隨着市場對AI應用需求不斷增長,對一體機的性能要求也會日益提高,一體機作爲集成了多種硬件和軟件功能的綜合性設備,其性能在很大程度上依賴於GPU的算力支持。如果GPU算力瓶頸擴大,可能對一體機的需求產生不利影響。
本文摘自中金公司2025年3月5日已經發布的《AI 進化論(3):DeepSeek本地部署需求盛行,一體機硬件乘風而上》
李詩雯 分析員 SAC 執證編號:S0080521070008 SFC CE Ref:BRG963
朱鏡榆 分析員 SAC 執證編號:S0080523070002
鄭欣怡 分析員 SAC 執證編號:S0080524070006
成喬升 分析員 SAC 執證編號:S0080521060004
彭虎 分析員 SAC 執證編號:S0080521020001 SFC CE Ref:BRE806
陳昊 分析員 SAC 執證編號:S0080520120009 SFC CE Ref:BQS925
標題:中金:DeepSeek本地部署需求盛行,一體機硬件乘風而上
地址:https://www.iknowplus.com/post/199384.html







