光芯片,火力全开
“20倍、50倍、100倍、1000倍、3000倍、10000倍...”,光芯片在計算方面超越硅芯片的速度與日俱增。
近幾十年以來,微電子技術與電子芯片產業遵循着摩爾定律不斷發展,隨着傳統制程工藝逼近極限,電子芯片在進一步提升計算速度和降低功耗方面的技術突破,面臨難以解決的瓶頸。
在後摩爾時代,光芯片這一顛覆性技術被視爲破局的關鍵。
尤其是當前對算力的需求來看,隨着AI的爆發,在未來10年中,增長越來越緩慢的電子芯片,難以匹配增長越來越快的數據需求。
由此,光芯片進入了人們的視野。
然而,從行業現狀來看,光芯片仿佛始終是“雷聲大,雨點小”,並未在市面上見到太多應用案例。那么,在強大優勢背後,光計算芯片目前發展現狀究竟如何?取得了哪些突破和進展,以及還面臨哪些棘手的挑战?
光芯片,難覓用武之地?
實際上,光芯片很早就有,已經很成熟,比如2000年前後的海底光纜,光通訊兩端的收發模塊都是光子芯片,甚至在上課或开會時用的激光筆,裏面也有激光器芯片,也是一種光子芯片。
但這些是不可編程的光學线性計算單元,所以無法運用於計算領域。要想通過光來提升算力,具有實用價值的計算單元就必須具備可編程性。

可編程光學系統的研究突破
(圖源:nature photonics)
而針對光計算的研究也很早就开始了,始於20世紀60年代,但受到當時應用範圍有限以及電子計算技術快速發展的影響,光計算處理器未能成功邁向商用。
直到最近10年,這種光計算芯片才逐漸取得突破性進展。
尤其是在當前時代,AI應用正推動對算力的需求,光芯片作爲重要的潛在顛覆性技術路徑,光計算芯片近年來又重新受到廣泛關注。
光芯片的核心是用波導來代替電芯片的銅導线,來做芯片和板卡上的信號傳輸,其實就是換了一種介質。當光在波導裏面傳輸的時候,波導和波導之間出現光信號幹涉,用這個物理過程來模擬线性計算這一類的計算過程,即通過光在傳播和相互作用之中的信息變化來進行計算。
與最先進的電子神經網絡架構及數字電子系統相比,光子計算架構在速度、帶寬和能效上優勢突出。因此,光子計算能夠有效突破傳統電子器件的性能瓶頸,滿足高速、低功耗通信和計算的需求。
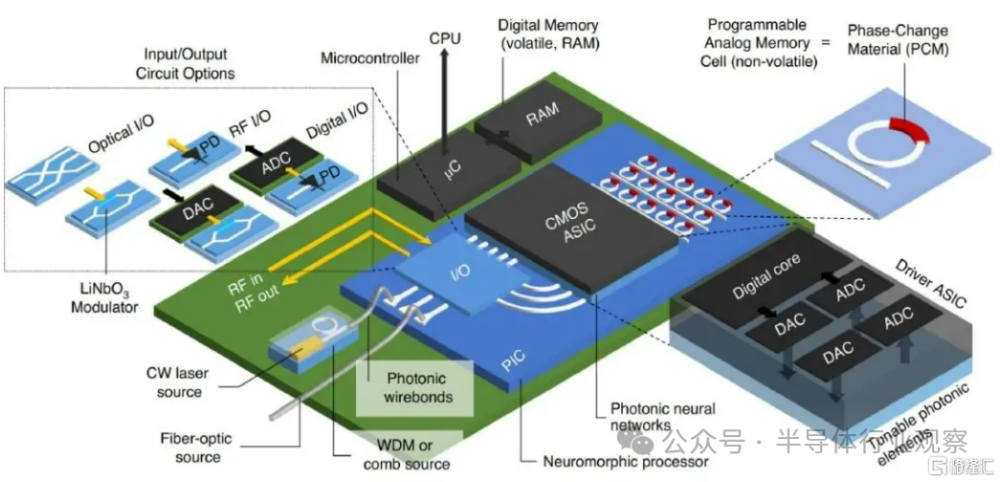
片上光子計算處理示意圖
(圖源:SEMI半導體研究院)
需要指出的是,光子計算的發展目標不是要取代傳統計算機,而是要輔助已有計算技術在基礎物理研究、非线性規劃、機器學習加速和智能信號處理等應用場景更高效地實現低延遲、大帶寬和低能耗。
硅光計算芯片通過在單個芯片上集成多種光子器件實現了更高的集成度,還能兼容現有半導體制造工藝,降低成本,解決後摩爾時代AI硬件的性能需求,突破馮·諾依曼架構的速度和功耗瓶頸。
綜合來看,光芯片的優勢可以總結爲:速度快/低延遲、低能耗、擅長AI矩陣計算等。
速度快/低延遲:光計算芯片最顯著的優勢是速度快、延遲低,在芯片尺寸的釐米尺度上,這個延遲時間是納秒級,且這個延遲與矩陣的尺寸幾乎無關,在尺寸較大的情況下,光子矩陣計算的延遲優勢非常明顯。
低能耗:鏡片折射本身是不需要能量的,是一個被動過程。在實際應用中,由於要對計算系統編程,其中光信號的產生和接收是需要耗能的。在光學器件和其控制電路被較好地優化前提下,基於相對傳統制程的光子計算的能效比,可媲美甚至超越先進制程的數字芯片。
擅長矩陣運算:光波的頻率、波長、偏振態和相位等信息可以代表不同數據,且光路在交叉傳輸時互不幹擾,比如兩束手電筒的光束交叉時,會穿過對方光束形成“X”型,並不會互相幹擾。這些特性使光子更擅長做矩陣計算,而AI大模型90%的計算任務都是矩陣計算。
因此,光計算芯片在AI時代迎來新的用武之地。
光芯片迎來突破性進展
光計算芯片可對神經網絡訓練和推理過程中的大規模矩陣運算、神經元非线性運算進行加速,還可通過對不同神經網絡的拓撲結構進行硬件結構映射,來提高芯片的通用性和靈活性。
據了解,在人工神經網絡計算加速方面,基於硅光平台的神經網絡已取得多項進展。
早在2016年,麻省理工學院(MIT)的光子AI計算研究團隊就打造了首個光學計算系統,2017年就以封面文章的形式發表在了頂級期刊Nature Photonics雜志上。
國際著名光學科學家、斯坦福大學終身正教授David Miller, 曾評價稱這一系列的研究成果極大地推動了集成光學在未來取代傳統電子計算芯片的發展。於是一篇論文在全球範圍內啓發了許多人投入到光子AI芯片的开發中,可以說是开創了光子AI計算領域發展的先河,受到業內矚目。
2017年,曦智科技創始人沈亦晨(MIT團隊成員之一)等人提出一種基於硅光平台的全光前饋神經網絡架構,採用馬赫-曾德幹涉儀(MZI)進行神經元线性部分的計算,非线性激活函數則通過電域仿真的方法實現。
隨着技術不斷發展,基於硅光平台的神經網絡也逐步走向商業化。例如,美國AI芯片公司Lightmatter推出通用光子AI加速器方案“Envise”;曦智科技在2019年4月對外宣布开發出了世界第一款光子芯片原型板卡,2021年推出了光子計算處理器“PACE”。

全球第一個示範出光子優勢的計算系統PACE
據悉,“PACE”把最早4×4的乘法器,提升到了把上萬個光器件集成在一塊芯片上面,單顆光芯片上的器件集成度提高了3個數量級,系統時鐘達1GHz,運行特定循環神經網絡速度可達目前高端GPU的數百倍,這是光子計算領域一個長足的進步。
沈亦晨表示,“PACE是全球僅有的,第一個示範出光子優勢的計算系統,也是已知全球集成度最高的光子芯片,能夠展示光子計算在人工智能和深度學習以外的應用案例。如果和英偉達的GPU 3080跑同一個循環神經網絡算法,PACE花的時間可以做到GPU的1%以內。”
在此之前,華爲在2019年公开了一份名爲“光計算芯片、系統及數據處理技術”的發明專利,接着在2021年華爲全球分析師大會上表示,“到2030年,算力需求將增加100倍,如何打造超級算力將是一個巨大的挑战,未來模擬計算、光子計算面臨巨大的應用場景,所以目前華爲也在研究模擬計算與光子計算。”
近幾年來,國內外企業、高校和研究機構也紛紛對此展开研究,取得了一系列成果和突破。
清華團隊研發超高速光電計算芯片,算力超3000倍
去年10月,清華大學自動化系戴瓊海院士、吳嘉敏助理教授與電子工程系方璐副教授、喬飛副研究員聯合攻關,提出了一種“掙脫”摩爾定律的全新計算架構:光電模擬芯片(ACCEL),算力可達到目前高性能商用GPU芯片的3000余倍,能效提升四百萬余倍,爲超高性能芯片研發开闢全新路徑。
相關成果以《面向高速視覺任務的純模擬光電計算芯片》(All-analog photo-electronic chip for high-speed vision tasks)爲題發表在 Nature 上。
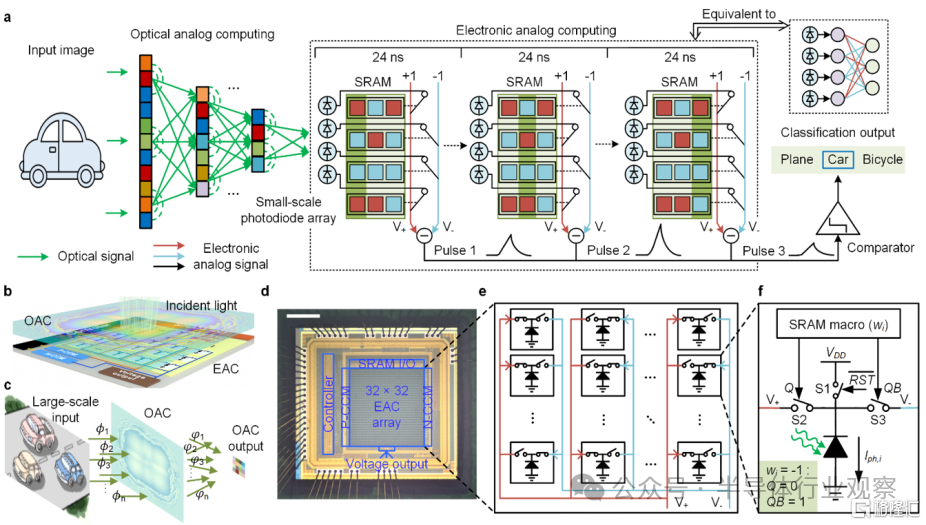
光電計算芯片ACCEL的計算原理和芯片架構
(來源:Nature)
據了解,在這枚光電計算芯片中,清華大學攻關團隊創造性地提出了光電深度融合的計算框架。從最本質的物理原理出發,結合了基於電磁波空間傳播的光計算,與基於基爾霍夫定律的純模擬電子計算,“掙脫”傳統芯片架構中數據轉換速度、精度與功耗相互制約的物理瓶頸,在一枚芯片上突破大規模計算單元集成、高效非线性、高速光電接口三個國際難題。在保證高任務性能的同時,還實現超高的計算能效和計算速度。
實測表現下,ACCEL光電融合芯片的系統級算力較現有的高性能芯片架構提升了數千倍。
然而,這還只是這枚芯片諸多優勢的其中之一。
在研發團隊演示的智能視覺任務和交通場景計算中,光電融合芯片的系統級能效,實測達到了74.8 Peta-OPS/W,是現有高性能芯片的四百萬余倍。形象來說,原本供現有芯片工作一小時的電量,可供它工作五百多年。
此外,在超低功耗下運行的ACCEL有助於大幅度改善發熱問題,對於芯片的未來設計帶來全方位突破,並爲超高速物理觀測提供算力基礎。
更進一步,該芯片光學部分的加工最小线寬僅採用百納米級,而電路部分僅採用180nm CMOS工藝,已取得比7nm制程的高性能芯片多個數量級的性能提升。同時所使用的材料簡單易得,造價僅爲後者的幾十分之一。
憑借諸多優勢,ACCEL未來有望在無人系統、工業檢測和 AI 大模型等方面實現應用。目前團隊僅研制出特定運算功能的光電融合原理樣片,需進一步开展具備通用功能的智能視覺運算芯片研發,以進行大範圍應用。
可以預見,隨着我國芯片加工技術不斷提升,更多新材料的加入,這種顛覆性架構未來的潛力將得到更多釋放。
新型芯片开啓光速AI計算之門
前不久,美國賓夕法尼亞大學工程師也开發了一種新型芯片,它使用光而不是電來執行訓練AI所必需的復雜數學運算。
該芯片有可能從根本上加快計算機的處理速度,同時還可降低能源消耗。相關研究發表在《自然·光子學》上。
據介紹,該芯片首次將本傑明·富蘭克林獎章獲得者納德·恩赫塔在納米尺度上操縱材料的开創性研究與硅光子(SiPh)平台結合起來。前者涉及利用光進行數學計算,後者使用的是硅。
光波與物質的相互作用代表着开發計算機的一種可能途徑,這種方法不受當今芯片局限性的限制。新型芯片的原理本質上與20世紀60年代計算革命初期芯片的原理相同。
研究人員描述了這種芯片的开發過程,其目標是开發一個執行向量矩陣乘法的平台。向量矩陣乘法是神經網絡开發和功能中的核心數學運算,而神經網絡是當今支持AI工具的計算機體系結構。
恩赫塔解釋說,他們可將硅晶片做得更薄,比如150納米,並且使用高度不均勻的硅晶片,在無需添加任何其他材料的情況下,這些高度的變化提供了一種控制光在芯片中傳播的方法,因爲高度的變化可導致光以特定的模式散射,從而允許芯片以光速進行數學計算。但這僅限於特定領域。
除了更快的速度和更少的能耗之外,新型芯片還具有隱私優勢。由於許多計算可同時進行,因此無需在計算機的工作內存中存儲敏感信息,從而使採用此類技術的未來計算機幾乎無法被入侵。
逆向設計高集成度光計算芯片
逆向設計高集成度光子集成器件是近年來的前沿熱點研究方向。
近日,美國賓夕法尼亞大學Vahid Nikkhah,Nader Engheta等學者提出了高效率仿真新方法,逆向設計了大矩陣維度的光學向量-矩陣乘法計算芯片。
傳統的逆向設計過程中,光場仿真時間隨器件面積指數級增長,這限制了器件的設計面積與矩陣計算維度。
爲了解決這個問題,該團隊提出一種壓縮光場仿真時間的方法——p2DEIA,基於光傳播的二維有效折射率近似,能夠大幅縮減逆向設計仿真時間,突破傳統方法在器件面積上的限制,從而設計大矩陣維度的光學向量-矩陣乘法芯片。
此外,由於p2DEIA方法對折射率的約束,該芯片具有無定形透鏡型結構,可以避免諧振特徵引起的窄帶寬和制造誤差敏感性,這在實現大規模集成的光計算芯片中發揮關鍵作用。
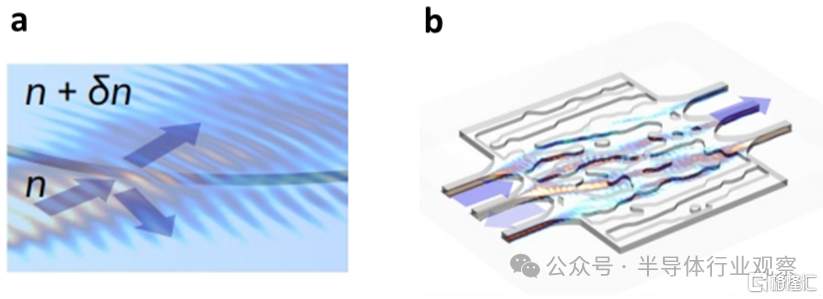
(a):p2DEIA方法示意圖;
(b):無定型透鏡結構示意圖
相關研究人員利用該方法,突破了仿真成本造成的逆向設計面積瓶頸,並成功設計出了大矩陣維度的光學向量-矩陣乘法器,可以完成1×N向量與N×N矩陣的乘法。
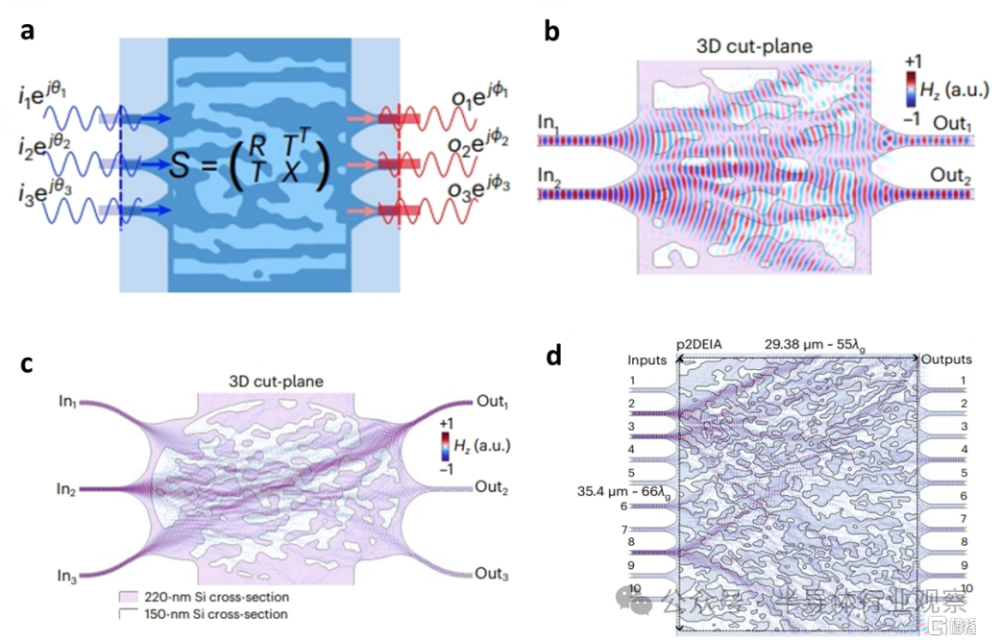
向量-矩陣乘法器設計示意圖
研究人員利用該方法設計了3種向量-矩陣乘法器芯片,矩陣維度分別是2×2、3×3和10×10,並進行了相關器件測試。實驗結果表明,該乘法器的實測性能與仿真性能非常接近,這爲實現大規模集成的光計算芯片提供了新的方法和思路。
中科院成功研制出光計算芯片
據報道,中科院李明研究員和祝寧華院士團隊也成功研制出光計算芯片。
目前而言,絕大多數傳統芯片都是基於馮·諾依曼計算範式的電子芯片。但電子芯片存在的能耗較高、容易發熱等一些問題始終無法解決,而且在計算時還會出現數據潮汐的傳輸問題。當電子數據如同海潮一般襲來,數據接收和處理端自然會有點“手忙腳亂”,影響其性能。
然而,光計算則不同。
光芯片利用光波作爲載體進行信息處理,具有低延時、低功耗、大帶寬等諸多優點,這是一種“傳輸即計算,結構即功能”的計算架構,有望避免馮·諾依曼計算範式中出現的數據潮汐傳輸問題。
尤其是在人工智能領域,經常需要處理大規模的數據和執行龐雜的計算任務,因此需要強大的計算能力和高速的數據傳輸能力。
對此,中國科學院开啓了全速研發,2023年5月,中國科學院發布消息稱,已成功研制出一款超高集成度光學卷積處理器,成功突破了“光計算”技術的壁壘。相關研究成果發表在《自然-通訊》上。
據悉,這款芯片的運算速度比英偉達的A100還要快1.5-10倍。同時,這款光計算芯片功耗比傳統的AI芯片功耗要低很多,關鍵是不需要使用高端光刻機就可以完成生產。
研究者表示,光學卷積處理單元通過兩個4×4多模幹涉耦合器和四個移相器,構造了三個2×2相關的實值卷積核。與其它光計算方案相比,該方案具有高算力密度、超高的线性擴展性。
基於這種技術,光芯片性能再次提升,而一旦這種技術應用於AI領域,能實現對現有AI芯片的顛覆,其速度可能不只是快1.5倍-10倍,可能會更快,應用空間廣闊。
全球領先的微波光子芯片
日前,香港城市大學副教授王騁團隊與香港中文大學研究人員合作,利用鈮酸鋰爲平台,开發出處理速度更快、能耗更低的微波光子芯片,可運用光學進行超快模擬電子信號處理及運算。研究成果已在國際權威學術期刊《自然》上發表。
據了解,微波光子技術使用光學元件以產生、傳輸和調控微波訊號,但集成微波光子系統一直難以同時實現芯片集成、高保真度及低功耗的超高速模擬信號處理。
爲解決這一難題,該團隊开發了集成微波光子系統,將超快電光轉換模塊與低損耗、多功能信號處理模塊同時結合在一塊芯片上,這是前所未有的成果。
據介紹,這種芯片比傳統電子處理器的速度快1000倍,且耗能更低,應用範圍廣泛,涵蓋5/6G無线通訊系統、高解析度雷達系統、人工智能、計算機視覺以及圖像和視頻處理。能實現這種卓越效能,是透過基於薄膜鈮酸鋰平台的集成微波光子處理引擎,該平台能執行模擬信號的多用途處理及計算工作。
未來,鈮酸鋰光子集成芯片有望像硅基集成電路一樣,成爲高速率、高容量、低能耗光學信息處理的重要平台,在光量子計算、大數據中心、人工智能及光傳感激光雷達等領域彰顯其應用價值。
麻省理工光學AI芯片實現裏程碑式突破
麻省理工學院(MIT)光學人工智能團隊首次提出將“時間-空間復用”應用在計算的光芯片設計理念,並採用光電效應做乘法和加法運算。2023年7月,相關論文以《Deep learning with coherent VCSEL neural networks》爲題發表在 Nature Photonics 上。

相關論文
(圖源:Nature Photonics)
這個計算架構在垂直表面發射激光器(VCSEL)陣列實現,並進行實驗驗證,實現了整體性能突破。
值得關注的是,該系統實現了光學計算芯片對電子計算的優勢,提升了100倍的能量效率和20倍的計算密度,有望在近期內實現多個數量級的提升。
當前,AI正在對人們的生活和工作方式產生顛覆性的變化。然而,運轉大規模的AI模型需要巨大的計算能力、時間和能量。例如,訓練GPT-4用到16000個NVIDIA A100 GPU連續運轉4至7個月,消耗成本高達1億美金。
光學芯片是在光而非電子的運動基礎上進行計算。由於超高光學帶寬和低損耗的數據傳輸,光計算芯片有可能在短期內實現幾個數量級的算力突破,從而成爲下一代計算處理器。
但是,目前,與電子計算芯片相比,光計算芯片的能耗、計算密度等性能仍然有顯著差距,可規模化程度低。其主要原因包括:電光轉換的效率較低導致的高能耗、集成光器件的尺寸較大導致計算密度低、缺少非线性運算導致高延時等。
與現有的光學計算系統相比,這種新型光電系統具有三方面的優勢,包括低能量損耗、高計算密度、光學非线性。
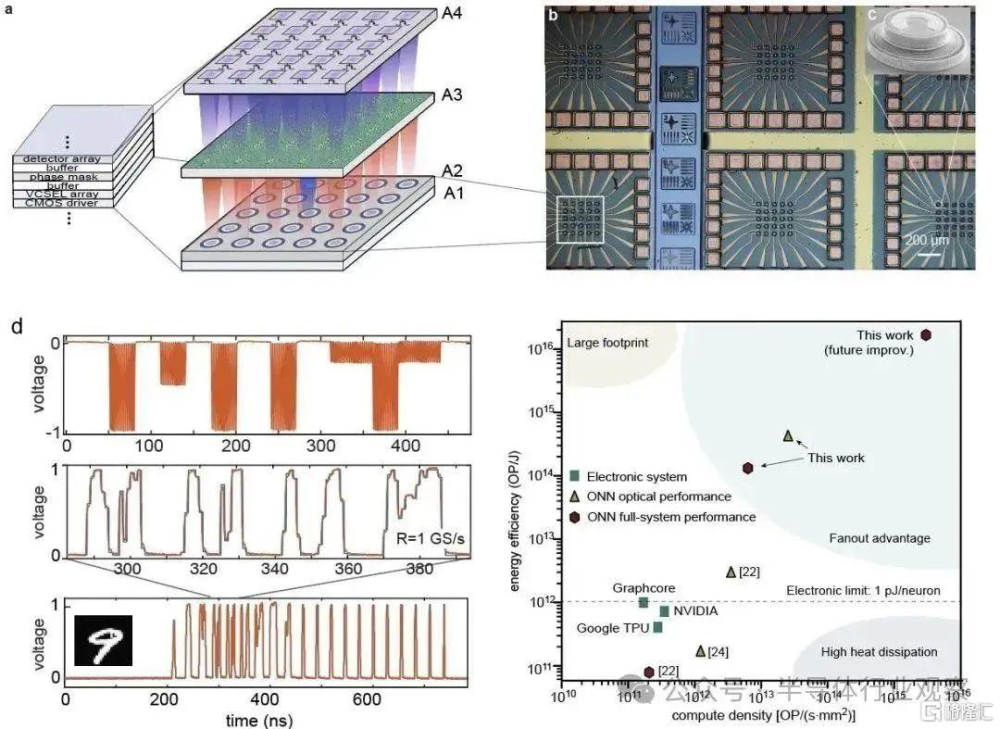
新型AI光子計算芯片系統實驗方案和結果
(圖源:Nature Photonics)
光學計算領域專家、耶魯大學Logan Wright教授對該研究評價稱,“該團隊基於調制VCSEL陣列的系統可能是實現大規模、高速光學神經網絡的可行途徑,這一點鼓舞着我以及該領域的許多其他研究人員。”
並且他對該技術的發展前景給予充分肯定,他認爲,雖然目前這技術仍遠未達到實際有用設備所需的規模和成本,但對未來幾年可以實現的目標感到樂觀,特別是考慮到這些系統必須加速非常大規模、非常昂貴的人工智能系統,例如ChatGPT等流行文本GPT系統中使用的系統。
目前,麻省理工學院博士,現爲南加州大學電子工程系助理教授陳在俊課題組致力於开發高算力、規模化的光學AI計算方法。據悉,目前團隊已經相關申請專利。通過整合目前已有的集成封裝技術,加速規模化。
存內光計算
牛津大學博士後董博維所在的課題組,是目前全球唯一實現存內光計算的實驗室。該團隊由Harish Bhaskaran院士負責,主要研究存內光計算,即存內計算與光計算的結合。
在傳統的馮諾依曼架構之中,由於大量數據在內存和處理器之間傳遞,故會帶來能耗問題和延時問題。而在存內計算之中,內存和處理器在空間上可以重疊放置,從而很好地解決上述問題。
對於光計算來說,它能很好地利用光的高速、低能耗、高並行度等優勢,從而解決電計算的對應瓶頸。
要想實現存內光計算,光存儲器是一個必不可少的組件。光存儲器能夠以非易失性的方式,改變功能材料的光學特性,即改變材料的折射率或吸收率,從而實現非易失性光存儲。
2015年,董博維所在團隊曾使用鍺銻碲材料首次實現硅光芯片上可控非易失性光存儲,並於2019年實現存內光矩陣的運算。
對於人工智能的數據處理來說,高並行度可謂至關重要。傳統的中央處理器CPU,採用的是线性處理的方式,即在單位時間之內執行一次運算。圖像處理器GPU則採用並行處理方式,在單位時間之內可以並行處理多次運算。這也正是GPU被廣泛用於人工智能產業的原因。
高並行度,是光的一大優勢。同時,由於光具備不同的自由度,因此可被用於提高其處理並行度,比如不同的偏振、不同的空間模式、不同的波長等。
過去,人們認爲採取波分復用的方式,可以提供上限最高的並行度。直到2021年,董博維所在課題組通過利用光的波分復用特性、以及存內光矩陣運算,實現了並行度爲4的存內光矩陣運算,並將其成功用於高速圖像卷積處理應用中。
近期,該團隊發現波分復用所提供的並行度提升並不是存內光計算的上限。通過光電集成,可以很方便地將射頻自由度引入存內光計算,實現數個量級的計算並行度提升,這不僅對光計算大有裨益,同時還可用於光通信、光傳感等領域。
此外,該團隊採用了光電混合芯片的設計方式,其中的可控光學交叉陣列設計十分巧妙,具有很強的拓展性。當把運算單元在二維平內內平鋪展开,即可實現大存內光計算矩陣。
爲了展示高並行度的優勢,課題組在實驗中僅使用一個芯片,就能對100張心電圖同時進行卷積處理,在患者死亡風險判別上實現了93.5%的准確率。
通過並行使用更多的光波長與射頻頻率,利用這一方法將能在單一芯片中,針對1000多個數據流進行同時處理,從而能在邊緣雲計算場景中發揮重要作用。
未來,各團隊將繼續拓展存內光計算芯片的輸入、輸出規模,讓其能夠滿足更多的應用場景。
另外,他們還將實現更高效的光電集成。在本次工作中,課題組只是驗證通過引入射頻自由度來提高光計算並行度的可行性,然而當前不少光電器件採用的依然是片外獨立器件。
因此在接下來的工作中,他們非常期待可以將光調制器、光電探測器、解(復用)器件,甚至是光源都集成到單個芯片中,實現高集成度系統。
此外,本次研究中利用了波長自由度和射頻自由度,但是光還具有其它自由度,比如常見的偏振自由度和空間模式自由度,基於此課題組還將通過利用更多光自由度,進一步地提高系統並行性。
超大規模集成光量子計算芯片
2023年4月,北京大學王劍威研究員、龔旗煌教授課題組與合作者經過6年聯合攻關,研制了基於超大規模集成硅基光子學的圖論“光量子計算芯片”——“博雅一號”,發展出了超大規模集成硅基光量子芯片的晶圓級加工和量子調控技術,首次實現了片上多光子高維度量子糾纏態的制備與調控,演示了基於圖論的可任意編程玻色取樣專用型量子計算。
相關研究成果以《超大規模集成的圖量子光子學》爲題,在线發表於《自然·光子學》。
據研究團隊介紹,圖論是數學和計算機科學的一個重要分支,可以用來描述被研究對象間的復雜關系。圖論也爲描述與刻畫量子態、量子器件和量子系統等提供了強有力的數學工具,如圖糾纏態是通用量子計算的重要資源態,量子行走可以模擬圖網絡結構,圖可以描述量子關聯、研究量子網絡等。
圖論“光量子計算芯片”是一種以數學圖論爲理論架構,描述、映射並在芯片上實現光量子計算功能的新型量子計算技術。
北京大學課題組與合作者經過6年聯合攻關,發展出了基於互補金屬氧化物半導體工藝的晶圓級大規模集成硅基光量子芯片制備技術和量子調控方法,研制了一款集成約2500個元器件的超大規模光量子芯片,實現了基於圖論的光量子計算和信息處理功能。
報道指出,這一光量子芯片可與復數圖完全一一對應,圖的邊對應關聯光子對源,頂點對應光子源到探測器的路徑,芯片輸出多重光子計數對應於圖的完美匹配。通過編程該光量子芯片可任意重構八頂點無向復圖,並執行與圖對應的量子信息處理和量子計算任務。
量子糾纏是研究量子基礎物理和量子計算前沿應用的核心資源。然而,如何在芯片上制備多光子且高維度的量子糾纏態,一直存在諸多理論和實驗挑战。
研究團隊利用該光量子芯片,首次實現了多光子且高維度的量子糾纏態的制備、操控、測量和糾纏驗證,驗證了四光子三維GHZ真糾纏。在圖論統一架構下,單一芯片編程實現了多種重要量子糾纏態。多光子高維糾纏可爲高維通用型量子計算提供關鍵資源態。據介紹,基於圖論的可編程玻色取樣專用型量子計算芯片有望爲化學分子模擬、圖優化求解、量子輔助機器學習等提供有效解決方案。
光芯片成果不斷,落地緩慢?
光芯片看起來是很不錯的技術路徑,但到底多久才能落地?
經緯創投認爲,光芯片商業化有兩大路徑:第一種思路是短期內不尋求完全替代電,不改動基礎架構,最大化地強調通用性,形成光電混合的新型算力網絡;另一種思路是把光芯片模塊化,不僅僅追求在計算領域的應用,還追求在片上、片間的傳輸領域應用,追求光模塊的“即插即用”。
硅光芯片不是靠尖端制程來獲勝,更多是靠速度和功耗,比如光的調制解調的速度、功耗,還有多波復用,在一個波導裏面同時能通過多少路光等。
可以理解爲,光芯片最大的優勢在於技術通用性。
這也不難理解,因爲無論是生產商還是客戶,最大的訴求之一就是要確保通用性。產品實現“开箱即用”才能夠最大限度降低學習成本,不需要對現在的底層框架進行過多修改,就能夠適配到成千上萬個應用場景中。所以不動基礎架構,而是把线性計算的計算核部分用光來部分替代,形成光電混合的算力網絡新形式,是最快的商業化路徑。
另一方面,全球光計算芯片競賽,各國和地區相繼出台政策推動發展。
美國國防部高級研究計劃局(DARPA) 早在2019年就啓動“未來計算系統”項目,以研究具備深度學習能力、高算力和低功耗的集成光子芯片。
歐盟在2020开始啓動PHOOUSING項目,致力於开發基於集成光子技術的將經典過程和量子過程結合起來的混合計算系統。
我國科技部“十四五”重點專項申報指南中,也將信息光子技術、高性能計算、物態調控、光電混合AI加速計算芯片列爲重要內容,其中包括光電混合AI加速計算芯片、量子計算、基於固態微腔光電子芯片、光學神經擬態計算系統等技術的研發。
能看到,如何爲智能時代提供更強大算力,許多國家已在思考下一波的發展浪潮,光計算正是頗具潛力的選項之一。
潛力之下,光芯片挑战尚在
雖然提到了很多優勢,但光芯片作爲一項前沿技術,必然有很多挑战有待克服。
工藝挑战:由於要用於復雜計算,光器件的數量必然會很多,要達到不錯的性能至少需要上萬個,這會帶來更復雜的結構和更大的尺寸。爲了實現可編程,必然要對每個器件進行控制,也會要求高集成度和一些Knowhow積累。這些要求會產生一些工藝上的挑战,同時導致成本很高,以及整體穩定性、生產良率都有挑战,所以必須找到一種低成本、高良率的方法,來控制大量光器件的技術。
溫度難題:因爲是模擬計算,當整個環境溫度對電芯片產生影響的時候,對光信號也會產生擾動,影響計算精度。有一種辦法是把整個芯片放在恆溫環境下,通過溫控電路來實現。但這反過來會犧牲一些光計算的低能耗優勢。此外,對於溫度控制,還包括芯片內部發熱,導致對周邊器件的影響問題。
產業鏈未形成成熟分工:光芯片技術門檻高、產品线難以標准化,生產各工藝綜合性更強,相比於大規模集成電路已形成高度的產業鏈分工,光芯片產業鏈行業尚未形成成熟的設計-代工-封測產業鏈。
新藍海市場亟待开拓:光芯片下遊大客戶爲主,可靠性與交付能力是重要競爭力;光芯片產業參與者衆多,中低端領域競爭激烈,高端市場仍是藍海。在算力基礎設施建設海量增長的背景下,光芯片將會迎來巨大的機會。
對於我國光芯片產業的發展路徑,有業內人士認爲或將經歷兩個階段:
1)在細分領域憑借自身技術實力,綁定優質客戶實現進口替代;
2)產品品類橫向擴張,打开遠期成長天花板。
由於光芯片行業具備細分品類較多等特點,中短期內看好在細分領域中具備深厚技術積累,且已綁定優質客戶的國產廠商,有望率先开啓進口替代步伐,佔據先發優勢;長期來看,具備較強橫向擴張能力的光芯片企業更具備競爭優勢。
寫在最後
光子計算提供了一條超越摩爾定律的算力提升路徑。
這一技術方向在過去幾年中正在逐漸變熱,除了上述高校、研究機構和初創企業的研究之外,包括一些芯片巨頭、晶圓廠、EDA公司、封測廠等各環節企業都在積極布局。
雖然光計算還沒有完全落地,但硅光芯片每個產業鏈環節的全面性,是光計算芯片量產的前提。
正如一位投資人所言:這是一個全新的賽道,“超越摩爾定律”也是一個激動人心的口號,但幾乎沒有前路可以借鑑,开拓者們正在披荊斬棘,技術挑战與商業化風險並存。但唯一可以確定的是,人類社會對提升算力的追求,正比以往任何一個時刻都更加迫切。
標題:光芯片,火力全开
地址:https://www.iknowplus.com/post/88603.html







