AI浪潮之巔系列:HBM成爲存儲战略要地
AGI時代來臨之際,算力和存儲的需求同步提升,在存算一體模式成爲主流之前,HBM(高帶寬存儲)對於克服“存儲牆”、提升帶寬等方面有較強優勢,主要應用在AI芯片片上存儲。根據SK海力士測算,HBM的需求在2022至2025年之間的CAGR增速將達到109%。HBM的快速增長對於IDM、晶圓制造、封裝、設備材料等產業鏈環節帶來了增量空間,目前已成爲存儲器鏈條各環節必爭之地。
摘要
AI算力追求高性能動態存儲,HBM成當前較佳方案。隨着數據量越發龐大加之AI芯片的加速發展,馮氏計算架構問題凸顯:“存”“算”之間性能失配,使得計算機的計算能力增長遇到瓶頸,雖然多核並行加速技術可以提高算力,但存儲帶寬的限制仍對計算系統的算力提升產生了制約。GDDR是目前應用較爲廣泛的顯存技術。但在AI計算領域GDDR也難堪重任,於是制造商將目光投向HBM技術。
HBM需求由AI芯片帶動,主流廠商競爭白熱化。根據我們測算,HBM的綜合需求與AI芯片的存儲容量需求、帶寬需求、HBM堆疊層數等多個參數有明顯關系。SK海力士、三星電子、美光科技三大家競爭進入白熱化,目前已各自發力HBM3E產品。
HBM制造復雜度提升,不同產業鏈環節均有參與機會。AI芯片制造步驟相對於傳統計算芯片復雜度大幅提升,同時考慮到不同的連接方式對於精度的要求和工藝要求不同,制造過程分布在IDM、晶圓廠和封裝廠。GPU、HBM是Chiplet中的主要有源器件,由IDM、晶圓廠、存儲廠進行制造;無源器件中,Interposer、RDL可由晶圓廠、IDM、封裝廠制造;基板和PCB則由對應的廠商供應。
HBM堆疊技術對於前後道設備要求大幅提升,鍵合方式路徑變化是市場關注熱點。HBM堆疊環節主要圍繞凸塊制造、表面布线、TSV、鍵合、解鍵合,光刻、塗膠顯影、濺射機、刻蝕、電鍍等前道工具參與其中。隨着堆疊結構增多,晶圓厚度降低,對減薄、切割、模塑等設備需求提升。較爲關鍵的鍵合中,當前市場主流鍵合方式依然是TCB壓合以及MR方案,我們認爲未來混合鍵合或將成爲主流方案。
風險
AI芯片主流路徑變化,AI芯片需求不達預期,DRAM和HBM路徑變化。
AI算力追求高性能動態存儲
HBM成爲當前較佳方案
人工智能、雲計算和深度學習可以總結爲3大算力階段,目前處於第三階段。雲端AI處理需求多用戶、高吞吐、低延遲、高密度部署。計算單元劇增使IO瓶頸愈加嚴重,需增加DDR接口通道數量、片內緩存容量和多芯片互聯。傳統的馮·諾伊曼架構以計算爲中心,由於處理器以提升速度爲主,存儲器更注重容量提升和成本優化,導致“存”“算”之間性能失配。
HBM具備高帶寬、小體積等優勢。隨着GPGPU的出現,GPU越來越多地被應用於高性能計算,在AI計算領域GDDR也難堪重任,於是制造商將目光投向HBM技術。通過多層堆疊,HBM能達到更高的I/O數量,使得顯存位寬達到1,024位,幾乎是GDDR的32倍,顯存帶寬顯著提升,此外還具有更低功耗、更小外形等優勢。顯存帶寬顯著提升解決了過去AI計算“內存牆”的問題,HBM逐步提高在中高端數據中心GPU中的滲透比率。
受構造影響,GDDR的總帶寬上限低於HBM。總帶寬=I/O數據速率(Gb/s)*位寬/8。爲解決DDR帶寬較低的問題,本質上需要對單I/O的數據速率和位寬(I/O數*單I/O位寬)進行提升,可分爲GDDR單體式方案和HBM堆疊式方案。單體式GDDR採取大幅提升單I/O數據速率的手段來改善總帶寬,GDDR5和GDDR6的單I/O數據速率已達到7 Gb/s到16Gb/s,超過HBM3的6.4 Gb/s。HBM利用TSV技術提升I/O數和單I/O位寬,從而大幅提升位寬,雖然維持較低的單I/O數據速率,但總帶寬遠優於GDDR。
HBM的綜合功耗低於GDDR。HBM通過增加I/O引腳數量來降低總线頻率,從而實現更低的功耗。盡管片上分布的大量緩存能提供足夠的計算帶寬,但由於存儲結構和工藝制約,片上緩存佔用了大部分的芯片面積(通常爲1/3至2/3),限制了算力提升。
HBM通過3D封裝工藝實現DRAM die的垂直方向堆疊封裝,可以較大程度節約存儲芯片在片上佔據的面積。HBM芯片的尺寸比傳統的DDR4芯片小20%,比GDDR5芯片節省了94%的表面積。根據三星電子的統計,3D TSV工藝較傳統POP封裝形式節省了35%的封裝尺寸。
目前主流的GDDR標准爲GDDR6,主流的HBM標准爲HBM3,HBM3的顯存帶寬約爲GDDR6的8-9倍。GDDR7的官方標准於3月5日由JEDEC發布,一個大的技術變化是內存總线上的兩位不歸零 (NRZ) 編碼轉換爲三位脈衝幅度調制 (PAM3) 編碼,JEDEC預計第一代GDDR7的數據傳輸速率預計約爲32 Gbps/pin。我們預計未來中短期HBM3E和GDDR7將成爲主流標准,而HBM3E在顯存帶寬方面有望達到GDDR7的6倍。
圖表1:市場上不同品牌和型號的GPU和存儲類型
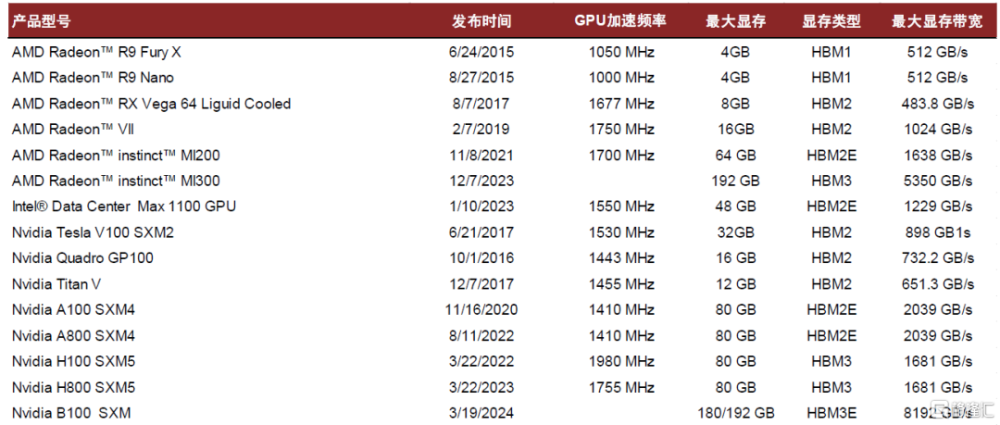
資料來源:各公司官網,Yole,中金公司研究部
HBM供需測算和技術路徑討論
需求:通過增量GPU需求測算HBM需求。根據我們測算,全球HBM晶圓2024、2025年總需求分別爲6萬片/每月、15萬片/每月。基礎假設爲2024、2025年攜帶HBM的GPU總量分別爲647萬顆和810萬顆,單顆GPU攜帶6、8顆Cube(堆疊之後的HBM),隨着平均堆疊層數的提升,總晶圓數量也隨之上升。我們然後假設每片晶圓上可切割的顆數爲400顆不變。得到2025年總晶圓需求爲16萬片/月,根據Yole,2024年全球產能預計將達到15萬片,在我們的假設下HBM仍有一定缺口。
圖表2:HBM需求總量的計算

資料來源:英偉達官網,AMD官網,Yole,中金公司研究部
圖表3:HBM晶圓產量測算
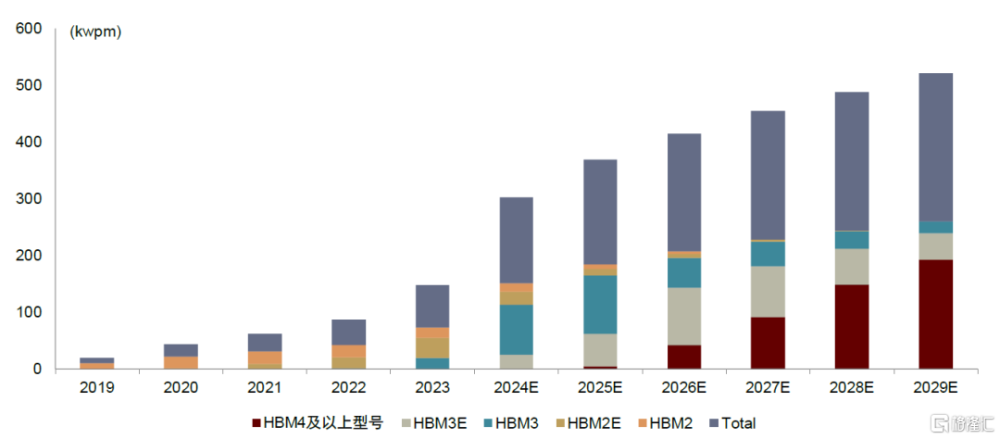
資料來源:Yole,中金公司研究部
供給:SK海力士、三星電子、美光科技三大家競爭進入白熱化,各自發力HBM3E產品。在近期英偉達GTC期間,三大家均展出了各自的最新HBM3E產品,在堆疊層數、單顆cube容量、帶寬上逐步對齊。SK海力士HBM3E在芯片密度、IO速率、帶寬、最大容量方面有明顯提升。
圖表4:各家存儲廠廠商在HBM上的路线圖
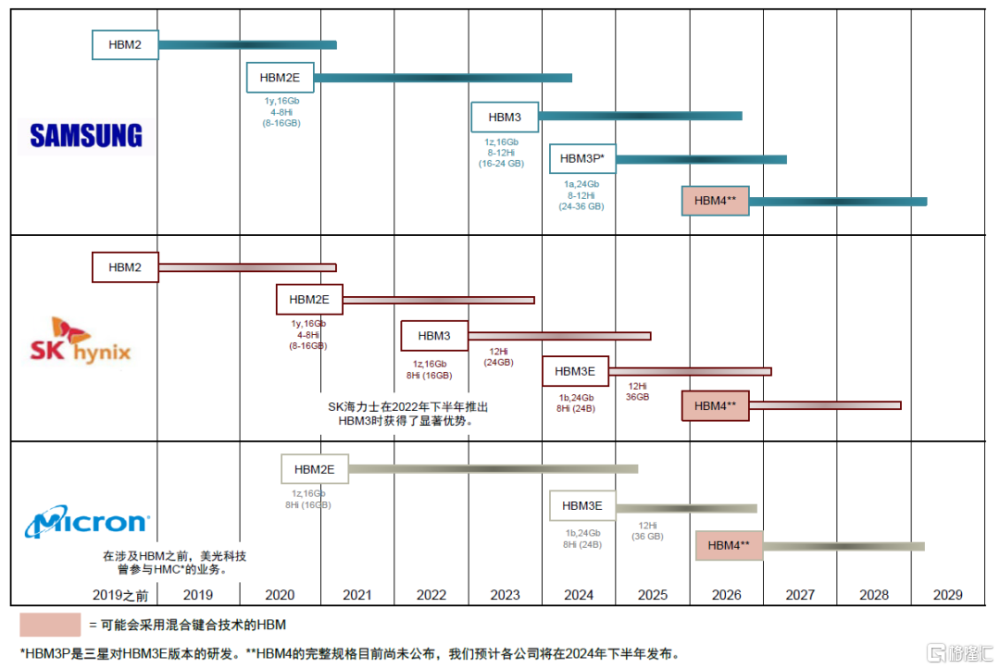
資料來源:Yole,各公司官網,中金公司研究部
HBM供應鏈拆解:制造商、設備商、材料商
HBM制造仍然以IDM爲主,但國內發展了出前後道分工的模式。GPU芯片的制造過程分布在IDM、晶圓廠和封裝廠。一般而言,xPU(CPU、GPU等)、HBM是片上的主要有源器件,由IDM、晶圓廠、存儲廠進行制造;無源器件中,Interposer、RDL可由晶圓廠、IDM、封裝廠制造;基板和PCB則由對應的廠商供應。最終的合封通常在封裝廠制造並進行測試。
我們認爲,OSATs對於HBM封裝工藝在堆疊技術和封裝處理工藝上有一定積累,但是對於晶圓處理上與晶圓廠和IDM有一定差距。目前來看,考慮到全球採用HBM和Chiplet堆疊技術的HPC設計公司並不多,從總量上看還是沒有做消費電子和PC鏈條上的芯片更大,因此單純的做HBM封裝或Chiplet封裝對於超大型封測廠來說並不是當前最優經濟選擇,但是隨着未來AI芯片尤其是服務器的總量需求增加,我們認爲一些成熟制程晶圓廠、大型OSATs也會逐步开始對高端先進封裝進行投資。
圖表5:存儲行業封裝參與者

資料來源:各公司官網,中金公司研究部
EUV光刻機已廣泛使用在DRAM制造中。三星電子於2020年首次將EUV應用於1z DRAM的生產中,SK海力士宣布在2021年2月完成了首條配備EUV工具的生產线,用於在2021年下半年生產1a DRAM。在未來幾年,SK海力士和三星預計將生產出採用高數值孔徑EUV的DRAM樣品,爲2026年之後大規模生產針對節點尺寸≤10納米的產品做准備。美光科技一直在使用自對准多重圖案化方法如SAQP,但在小於1β節點的情況下,多重圖案化方法和沉浸式光刻的工藝控制和生產穩定性變得越來越困難,故美光或將從1γ節點开始引入EUV技術。
刻蝕設備佔比在DRAM制造產线中不斷提升。根據Yole估算,DRAM制造的設備支出中,超過70%可能會集中在沉積和蝕刻系統上。光刻的支出可能會降至20%以下。全球市場來看,Lam,TEL和AMAT幾乎壟斷全球幹法刻蝕設備市場,2020年三者幹法刻蝕設備的全球市佔率分別爲46.71%,26.57%和16.96%,合計佔比超90%。其中,硅基刻蝕主要被Lam和AMAT壟斷,介質刻蝕主要被TEL和Lam壟斷。
圖表6:HBM前道設備主要供應商

資料來源:各公司官網,中金公司研究部
HBM的中後道制造環節主要圍繞凸塊、芯片表面布线、基板布线、不同層之間的鍵合貼裝展开。所用設備和材料與前道基本一致,其中鍵合是較關鍵步驟之一。
Bumping(凸塊):倒裝是先進封裝中的核心工藝,而Bumping又是倒裝流程中重要的工藝,是Chiplet的第一步。Bumping指的是在晶圓表面預留的位置(通常是Pad)生長焊球,通過焊球實現與基板、PCB的連接。Bumping的材料一般有錫、銅、金,其制造過程與前道晶圓制造步驟基本相似,主要涉及PI塗敷、光刻、濺鍍、電鍍、清洗、回流焊等工藝。Bumping的參數主要分爲直徑、高度和密度,隨着芯片復雜度提升,引腳數相應提升,導致Bumping直徑更小、高度更低、密度更高,對應難度更高。
TSV(Through silicon via, 硅通孔):主要用於立體封裝,在硅片中進行垂直方向上的打孔,爲芯片起到電氣延伸和互連的作用。按照集成類型的不同,TSV分爲2.5D和3D,2.5D TSV位於中介層中,而3DTSV貫穿芯片本身,直接連接上下層芯片。TSV連接方式大量應用於高端存儲器堆疊、Interposer中。
全球來看,涉及中道制造設備的公司與前道制造設備供應商類似,其中在光刻工藝步驟中,AMAT、TEL、SUSS、Veeco、PSK、DNS等公司均有涉及,鍵合/解鍵合、TSV、CMP和檢測過程的國產廠商已經佔據一定份額。國內前道設備制造商如北方華創、盛美上海、芯源微、芯碁微裝、中科飛測、華卓精科、上海微電子均已在中道制造設備中有大量產品出貨,並且在上述公司發展初期爲收入增長提供了較大的支撐。且我們認爲在先進封裝的快速發展趨勢下,中道制造的重要性逐步凸顯,對於中道設備的需求將持續提升,我們認爲未來仍將是半導體裝用設備和零部件廠商的重要業績來源。
HBM多層堆疊結構提升工序步驟,帶動封裝設備需求持續提升。HBM堆疊結構增多,要求晶圓厚度不斷降低,這意味着對減薄、鍵合等設備的需求提升;HBM多層堆疊結構依靠超薄晶圓和銅—銅混合鍵合工藝增加了對臨時鍵合/解鍵合等設備的需求;各層DRAM Die的保護材料也非常關鍵,對注塑或壓塑設備提出了較高要求。
圖表7:HBM中道制造產業鏈
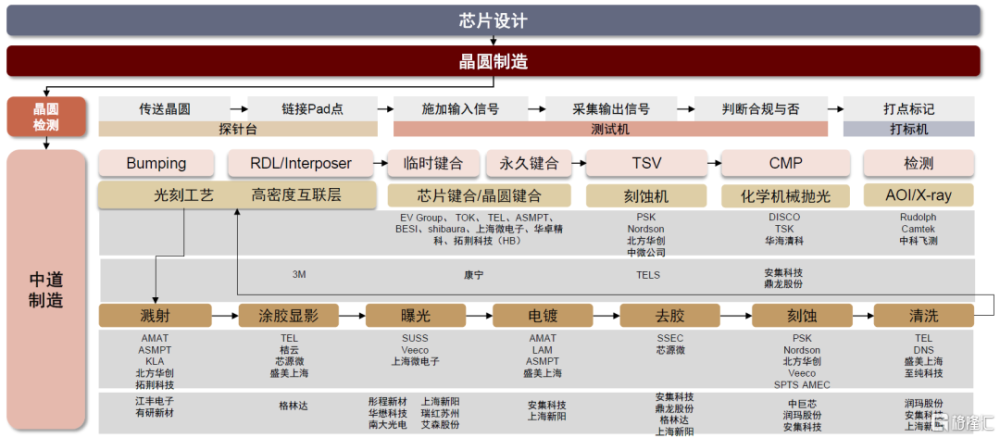
資料來源:Wind,各公司公告,中金公司研究部
圖表8:HBM後道制造產業鏈
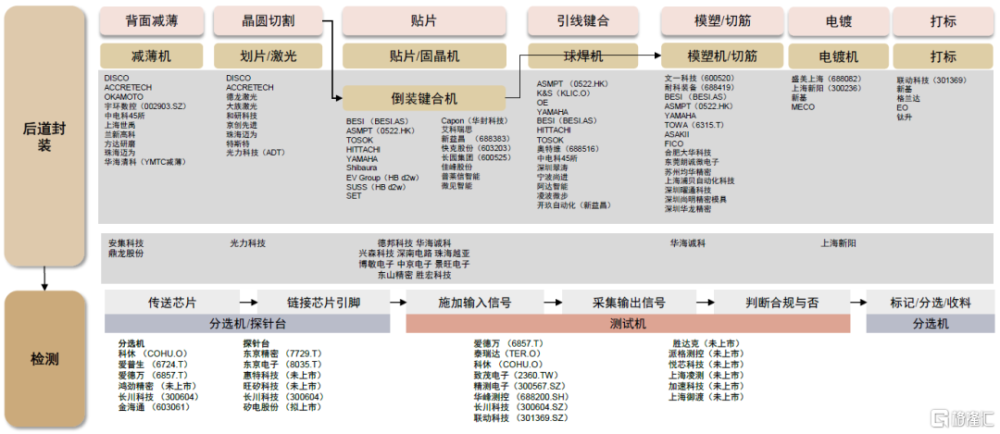
注:統計截至2024年4月1日 資料來源:Wind,各公司公告,中金公司研究部
HBM對堆疊高度、散熱有明確要求,當前市場主流鍵合方式依然是TCB壓合以及MR方案,我們認爲未來混合鍵合或將成爲主流方案,但其成本和時間仍相對模糊。對於HBM而言,以下幾個方面是堆疊所追求的:1)更短互連和更大單cube容量;2)更好的散熱;3)維持單cube高度不變。
MR- MUF(Mass reflow,批量回流焊)
MR-MUF是海力士的高端封裝工藝,通過將芯片貼附在電路上,在堆疊時,在芯片和芯片之間注入液態環氧樹脂塑封(Liquid epoxy Molding Compound,LMC)液態保護材料並硬化。與傳統的每個芯片堆疊後鋪設薄膜材料的方法相比,MR技術在熱散布效率、生產效率和成本效益方面具有一定優勢。SK海力士已將MR技術應用於其HBM3E產品中。
圖表9:SK海力士 Mass reflow 制造流程
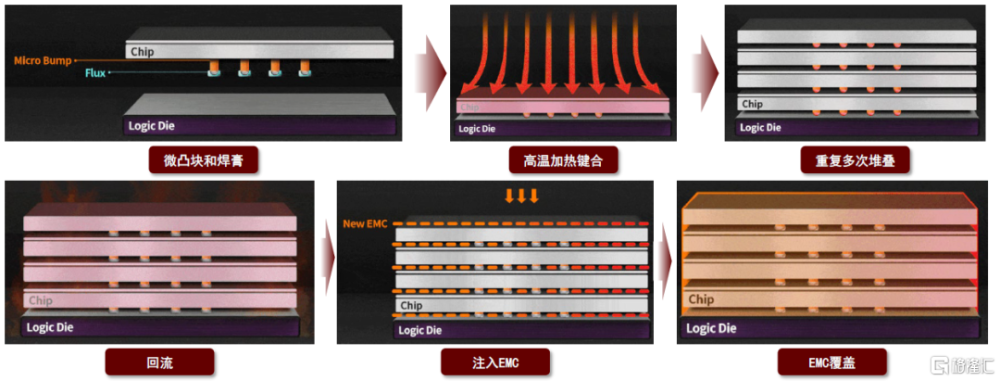
資料來源:SK海力士官網,中金公司研究部
TCB(Thermo-Compression Bonding,熱壓鍵合)
TCB的核心是通過熱壓鍵合技術將芯片與基板固定在一起,從而實現高密度的芯片封裝。隨着焊接凸點間距不斷減小、基板和晶片厚度不斷下降,傳統的回流焊工藝出現了翹起、局部橋接、芯片偏移等缺陷,TCB工藝能很好地解決這些問題。
圖表10:TCB工藝流程
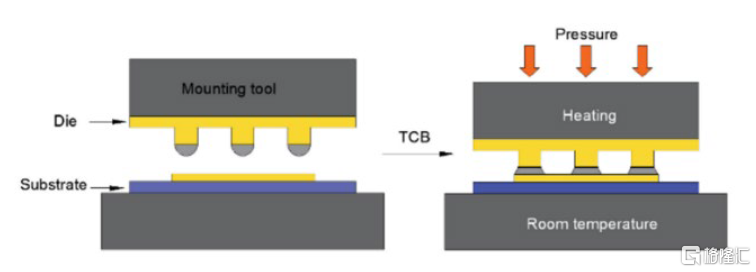
資料來源:Li, J. H. et al.《The thermal cycling reliability of copper pillar solder bump in flip chip via thermal compression bonding》(2020),中金公司研究部
圖表11:ASMPT的LPC TCB工藝流程
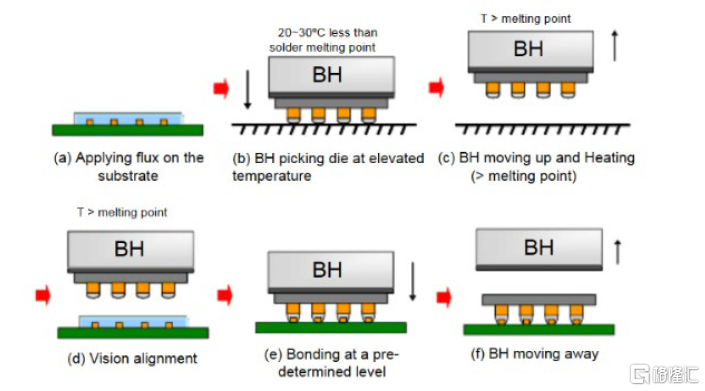
資料來源:Li, Ming et al.《A high throughput and reliable thermal compression bonding process for advanced interconnections》(2015),中金公司研究部
HB(Hybrid bonding,混合鍵合)
HB工藝能提供更高的互連密度,因此對於15μm以下的凸點間距,HB工藝正逐漸取代傳統的die-to-die焊接工藝。傳統焊接工藝的凸點使用覆蓋了焊料的銅柱,而HB工藝使用和表面平行的金屬片,提高了互連密度和效率。HB工藝主要包含die-to-wafer和wafer-to-wafer兩類鍵合,wafer-to-wafer的工藝更加成熟,但需要每個芯片尺寸相同,且整體良率較低,因此和die-to-wafer工藝相比缺乏一定靈活性。根據ZDNET,JEDEC(國際半導體標准化組織)可能放寬第六代HBM4的堆疊高度,在對應厚度上MR和TC方案仍可以繼續使用,雖然HB方案可提供更窄的pitch間距和更薄的高度,考慮到其普及率不高,以目前較高的價格,大規模應用可能有所推遲。
圖表12:Hybrid Boding工藝

資料來源:A. Elsherbini et al.《Enabling Hybrid Bonding on Intel Process》(2021),中金公司研究部
圖表13:Hybrid Bonding工藝在3D封裝中的應用
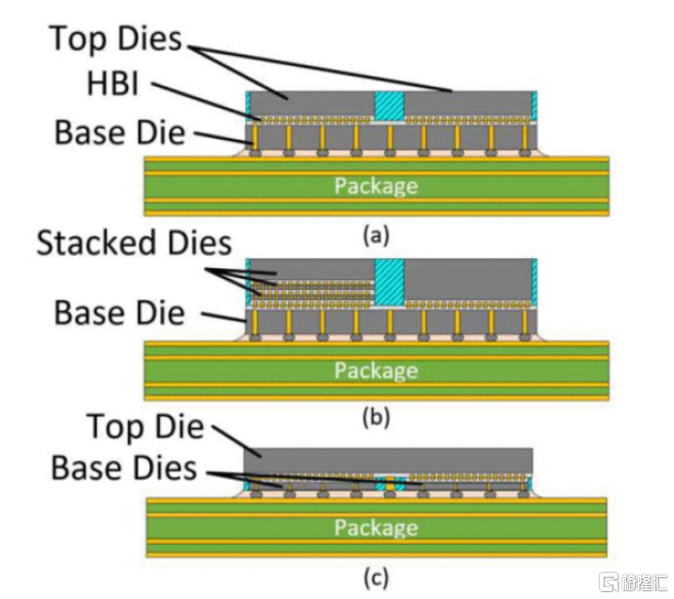
資料來源:A. Elsherbini et al.《Enabling Hybrid Bonding on Intel Process》(2021),中金公司研究部
DRAM的Scaling(縮放)挑战和堆疊方式
DRAM廠商和研究機構迫切地想突破新工藝和尋找DRAM更高極限的新工藝。平面DRAM的scaling在隨着摩爾定律放緩和物理極限的限制也有所放緩,隨着EUV的應用,平面DRAM仍有一定scaling空間。但爲了持續的提高密度並降低每bit價格,各類研究如調整晶體管的制造方式、採用單體3D-DRAM結構等正在進行。
延續Scaling方向:Planer DRAM採用EUV和HKMG制造技術。我們觀察到,DRAM的Scaling本預計在幾年前停止,但新的技術解決方案使其延續到1β節點,目前1β正進入早期生產階段。規模化成本的增加和基礎物理的限制使得DRAM制造商在平面方向上的Scaling變得越來越具有挑战性。我們認爲,新材料、新設備、新器件架構(如單體3D DRAM)以及新工藝技術將是長期延續DRAM Scaling所必需的。
延續Scaling方向:4F2單元結構。4F²單元結構被看作是減少芯片面積的主要選擇之一,與現有的6F²結構相比,可以減少大約30%的面積,而無需使用更小的光刻節點。2023年5月,三星成立研發團隊开發10納米節點(如1d)及更小節點的DRAM的4F²結構。4F² DRAM很可能會採用垂直電容和垂直晶體管。
圖表14:同等线寬下,4F2相較於6F2可節省約30%晶圓面積
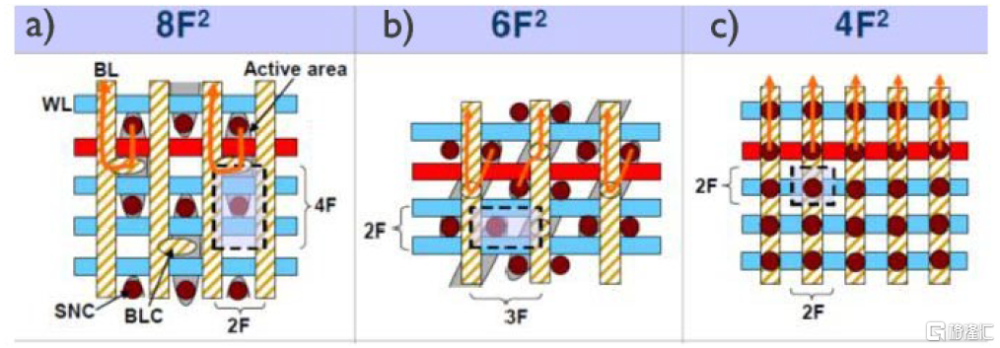
資料來源:Spessot, A., & Oh, H. (2020). 1T-1C Dynamic Random Access Memory Status, Challenges, and Prospects. IEEE Transactions on Electron Devices, 67, 1382-1393.,中金公司研究部
延續Scaling:從平面結構走向3D DRAM。平面DRAM的Scaling能力受限,隨着晶體管尺寸的不斷減小,電容器的尺寸也必須相應縮小,導致存儲電荷能力下降,所以需要發展3D DRAM,通過垂直堆疊存儲單元層來顯著提高存儲密度和性能。
另一種3D DRAM結構與3D NAND 非常相似,即互補金屬氧化物半導體鍵合陣列(CMOS-Bonded Array,簡稱CBA)。DRAM架構的外圍電路和存儲器陣列先在不同的晶圓上進行加工,然後結合在一起。該DRAM架構很可能會在4F²單元引入時(Yole預計2025年後)被採用。目前來看,將CBA與6F²單元結合使用並不方便。
圖表15:電容爲橫向排布的DRAM
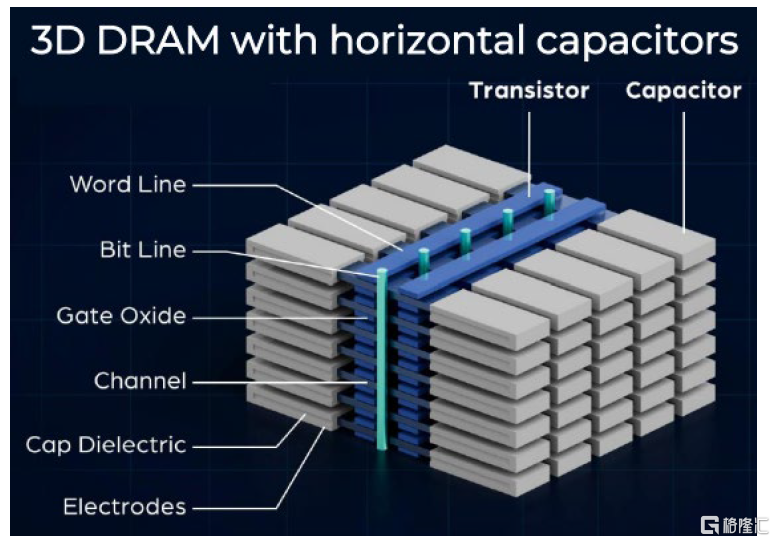
資料來源:NEO半導體,中金公司研究部
圖表16:CBA(CMOS bonded array)結構與3D-stacking NAND 結構類似
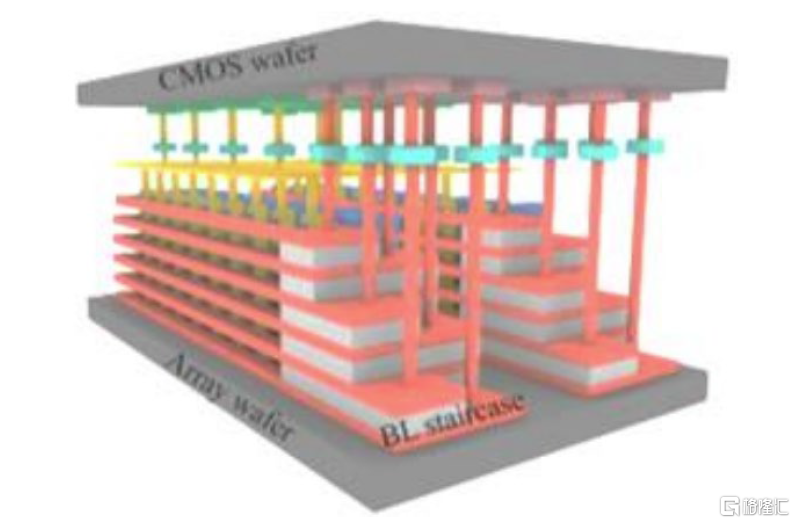
資料來源:Yole,中金公司研究部
HBM與GPU上下堆疊方式。AMD曾經展出過的存儲器與GPU上下堆疊的構造方式。在2023年ISSCC的演講中,AMD詳細介紹了提高數據中心的能效,並在半導體制造節點進步放緩的情況下,設法跟上摩爾定律的步伐的方法,即用多芯片模塊(MCMs)的形式將HBM與GPU上下堆疊,其中邏輯芯片和HBM堆棧位於硅中介層的上方。
圖表17:AMD展示不同的存儲器與計算芯片的組合方式
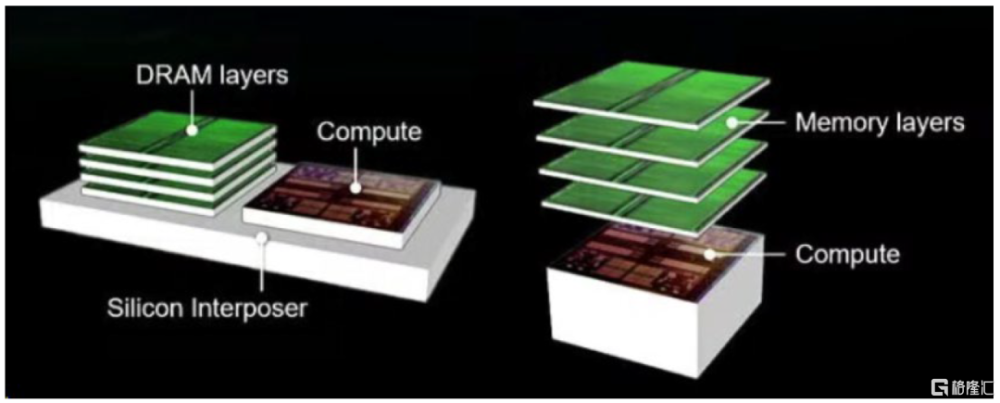
資料來源:AMD在2023年ISSCC的演講,中金公司研究部
本文摘自:2024年4月5日已經發布的《AI浪潮之巔系列:HBM成爲存儲战略要地》
張怡康 分析員 SAC 執證編號:S0080522110007 SFC CE Ref:BTO172
胡炯益 分析員 SAC 執證編號:S0080522080012
唐宗其 分析員 SAC 執證編號:S0080521050014 SFC CE Ref:BRQ161
江磊 分析員 SAC 執證編號:S0080523070007 SFC CE Ref:BTT278
彭虎 分析員 SAC 執證編號:S0080521020001 SFC CE Ref:BRE806
石曉彬 分析員 SAC 執證編號:S0080521030001
標題:AI浪潮之巔系列:HBM成爲存儲战略要地
地址:https://www.iknowplus.com/post/96819.html







