AI智道:DeepSeek Infra开源周總結,及算力測算一覽
摘要
2025年2月24-28日,DeepSeek進行爲期一周的Infra开源周,Infra工程優化能力國內領先。我們就开源周內容進行梳理,並對推理算力及毛利率水平進行測算。
DeepSeek开源周深度適配GPU特性,通過五大Infra核心技術構建大模型-算力全棧協同體系,FP8精度與通信優化爲核心。計算層,FlashMLA實現可變長序列解碼加速,配合DeepGEMM的FP8動態精度矩陣運算突破算力瓶頸。通信層,DeepEP通過FP8壓縮與RDMA(Remote Direct Memory Access)技術打通MoE模型跨節點傳輸,DualPipe/EPLB則以計算-通信流水线重疊消除分布式訓練間隙並實現負載均衡;存儲層通過3FS文件系統以SSD(Solid State Drive)+RDMA架構保障數據高效存取。DeepSeek以“單卡算力提升-核心計算加速-通信延遲降低-多卡協作優化-數據流高速供給”爲技術脈絡,形成軟硬協同的優化閉環,最終將千億參數模型的訓練、推理效率推向硬件極限,實現大模型开發成本的大幅壓縮。
DeepSeek成本及算力測算:毛利率水平國內領先。DeepSeek在3月1日公开了模型推理效率和成本,我們以模型API定價測算收入、GPU hours租賃成本作爲考慮的核心成本項,來測算綜合毛利率:倘若這些輸入/輸出Token全按照R1的定價,收費是56萬美元;而按照V3的定價,收費是30萬美元左右,則對應毛利率分別爲84.5%/71%,因此綜合毛利率應在71-84.5%,這一毛利率在行業中處於領先的水平。
Infra優化能力進一步推動大模型平權,Agent等應用有望帶來AI應用百花齊放、推理算力需求樂觀。1)推理算力側,我們認爲AI infra的進步將會提升算力利用效率,推動整個行業的繁榮,這對於未來的推理算力需求影響爲正面;此外,我們認爲多模態、Manus等Agent應用有望驅動更大規模的推理算力需求。2)應用側,我們認爲隨着模型推理成本的持續降低,推理成本已進入“不敏感”區間,更多AI應用的規模商業化取決於模型能力、工程優化。其中2C應用,我們更看好互聯網公司在產品化的沉澱;2B應用,我們則更爲關注垂類卡位的企業服務廠商的客戶、場景沉澱。
風險
技術進展不及預期,商業化落地不及預期。
DeepSeek开源周:
Infra層優化能力行業領先
DeepSeek开源周深度適配GPU特性,通過五大Infra核心技術構建大模型-算力全棧協同體系。計算層,FlashMLA實現可變長序列解碼加速,配合DeepGEMM的FP8動態精度矩陣運算突破算力瓶頸。通信層,DeepEP通過FP8壓縮與RDMA(Remote Direct Memory Access)技術打通MoE模型跨節點傳輸,DualPipe/EPLB則以計算-通信流水线重疊消除分布式訓練間隙並實現負載均衡;存儲層通過3FS文件系統以SSD(Solid State Drive)+RDMA架構保障數據高效存取。DeepSeek以“單卡算力提升-核心計算加速-通信延遲降低-多卡協作優化-數據流高速供給”爲技術脈絡,形成軟硬協同的優化閉環,最終將千億參數模型的訓練、推理效率推向硬件極限,實現大模型开發成本的大幅壓縮。
圖表1:DeepSeek开源周成果匯總
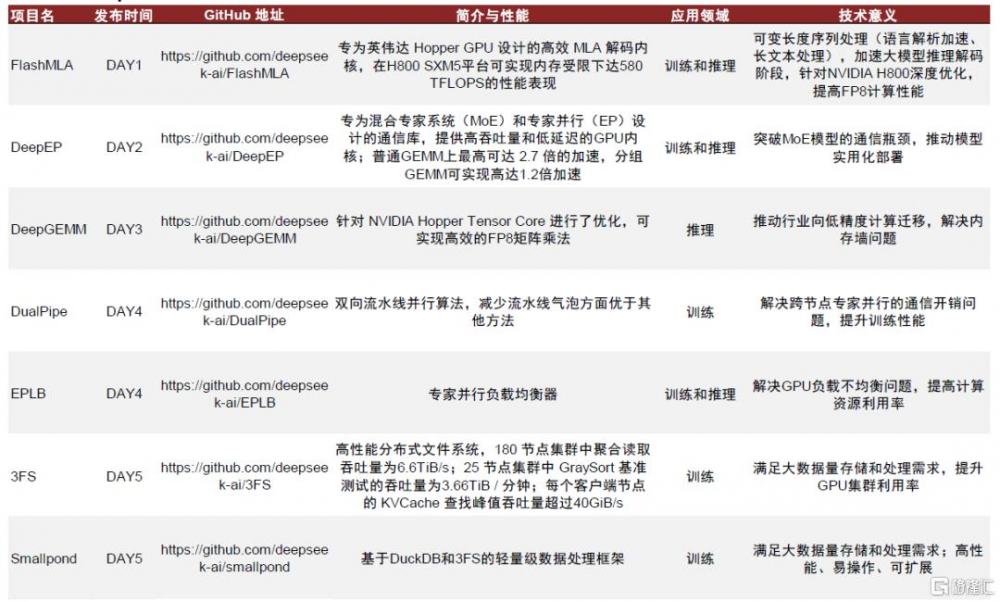
注:开源周爲2025年2月24-28日,3月1日發布收入成本估算,技術側不單獨列示,測算詳見正文 資料來源:deepseek-ai/open-infra-index: Production-tested AI infrastructure tools for efficient AGI development and community-driven innovation,中金公司研究部
Day1:DeepSeek發布爲英偉達Hopper GPU設計的MLA解碼內核FlashMLA,旨在實現MoE模型推理加速。FlashMLA針對變長序列處理、對話系統等場景深度優化並已投入實際應用。其核心創新包括三大模塊:1)分頁KV緩存(Paged KV Cache),採用分塊管理(塊大小64)分配顯存,減少每次查詢的KV緩存量(約93.3%);2)分塊調度與內存優化,融合FlashAttention 2&3和Cutlass設計理念,優化內存訪問模式,減少數據搬運开銷,使BF16精度下計算峰值達580 TFLOPS;3)原生稀疏注意力(Native Sparse Attention),通過算法裁剪冗余計算,在降低顯存佔用的同時增強長上下文處理能力。此外,系統支持動態調度與並行計算和BF16精度計算,兼顧硬件資源利用效率與高吞吐需求。實測顯示,在H800 SXM5平台(CUDA 12.6)中,FlashMLA可實現內存受限配置下3000GB/s帶寬、計算受限配置下580 TFLOPS的頂尖性能表現(較傳統方法提升30%以上)。
Day2:發布DeepEP,爲MoE模型和專家並行(EP)設計的專用通信庫,支持FP8的低精度通信,實現訓練和推理環節的高吞吐、低延遲性能。主要特點包括:1)高效優化的all-to-all通信,提供高吞吐量和低延遲的GPU全互聯內核,用於MoE的調度和組合操作,且內核吞吐量高,適用於模型訓練和推理預填充任務;2)內部節點和節點間均支持NVLink和RDMA(Remote Direct Memory Access)技術,借助NVLink的高速帶寬和RDMA的遠程直接內存訪問能力,加速數據傳輸;3)爲推理解碼提供低延遲內核,針對對延遲敏感的推理解碼任務,包含一組純RDMA實現的低延遲內核,可最小化延遲;4)原生支持FP8低精度運算,配合BF16格式進行組合運算,在保證模型精度的同時,減少計算量;5)靈活的GPU資源控制,實現計算與通信的並行處理。
Day3:發布了DeepGEMM,是專門針對FP8通用矩陣乘法打造的庫,支持密集GEMM和MoE GEMM。DeepGEMM採用CUDA 核心的兩級累加(提升)機制,解決FP8張量核心累加不精確的問題,爲V3/R1訓練和推理提供支持,在H800上最高可以實現2.7倍加速。核心優化包括:1)线程束優化,通過操作重疊優化、寄存器計數控制和持久线程專用化,減少計算時間、提高寄存器利用率並解決FP8張量核心累加不精確問題;2)利用Hopper TMA 具有快速異步數據移動等特點,在數據加載存儲、多播和描述符預取等方面更加充分運用,提升計算連貫性和效率;3)特殊優化上,包括GPU計算時支持非對齊塊大小,讓更多的流式多處理器(SM)參與工作以提升硬件資源利用率,採用FFMA(Fused Multiply-Add)和SASS(Shader Assembly)交錯提升性能,以及使用柵格化提高L2緩存重用。
圖表2:普通GEMM(非分組)在H800上性能最高可以實現2.7倍加速
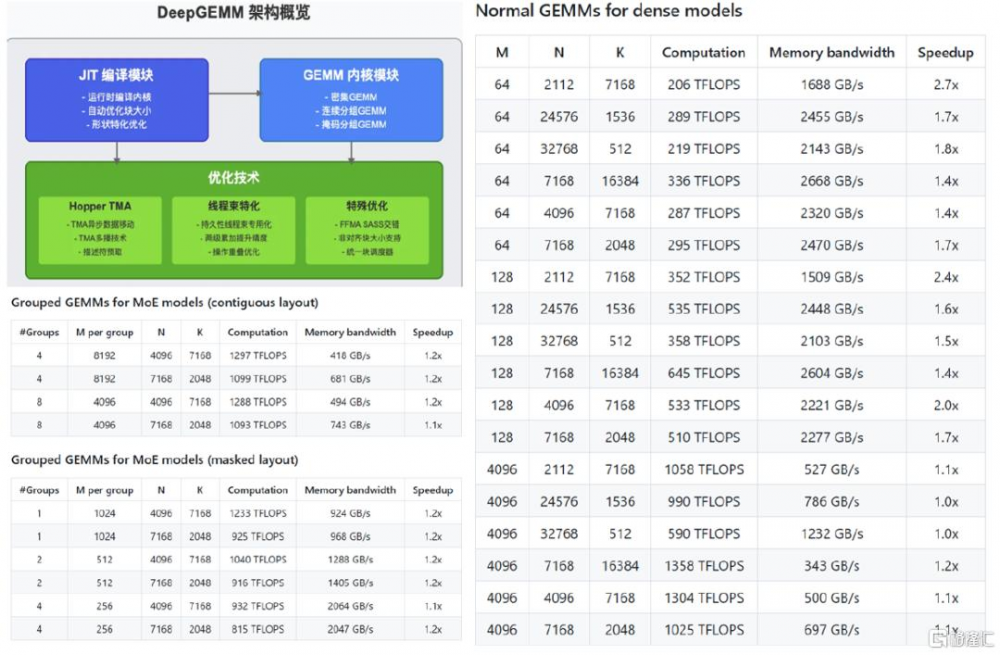
資料來源:deepseek-ai/DeepGEMM: DeepGEMM: clean and efficient FP8 GEMM kernels with fine-grained scaling,AGI Hunt,中金公司研究部
Day4:DeepSeek 开源三個代碼庫,分別是DualPipe,一種雙向流水线並行算法,用於V3/R1訓練中的計算-通信重疊;EPLB,專家並行負載均衡器;Profile-data,公开分享來自訓練和推理框架的分析數據。
DualPipe算法:旨在通過重疊計算與通信階段、減少流水线氣泡來提升整體訓練性能。DeepSeek-V3訓練裏,跨節點專家並行引發較高通信开銷,使計算與通信比例約爲1:1,嚴重影響訓練效率。爲解決該問題,DualPipe重疊計算與通信階段,提升整體訓練性能。具體而言,將每個計算塊細分爲四個組件,即注意力、全對全分發、MLP、全對全組合,其中對於反向計算塊中的注意力和MLP進一步拆分爲用於輸入和用於權重的反向計算。通過精心重新排列這些組件,並手動調整GPU的流式多處理器(SMs)分配給通信和計算的比例,實現計算與通信在前後向塊中的重疊執行。DualPipe採用雙向流水线調度策略,讓微批次從流水线的兩端同時輸入,使得大部分通信操作能在計算過程中完成,從而減少通信开銷和流水线氣泡。
圖表3:DualPipe採用雙向流水线調度,使得大部分通信操作都能被完全重疊

資料來源:deepseek-ai/DualPipe: A bidirectional pipeline parallelism algorithm for computation-communication overlap in V3/R1 training.,中金公司研究部
專家並行負載均衡器(EPLB):解決不同專家負載不均衡的問題。在使用專家並行(EP)技術時,不同專家被分配到不同GPU,由於各專家的負載會因當前工作量不同而產生差異,容易造成GPU負載不均衡,影響計算資源的有效利用和整體計算效率,因此需要EPLB來進行負載均衡。冗余專家策略和組限制專家路由是EPLB解決負載不均衡問題的基本思路。冗余專家策略通過復制高負載專家,爲平衡GPU負載提供了更多可調配的資源;組限制專家路由則從數據傳輸優化的角度,減少節點間通信开銷,提升整體性能。層負載均衡和全局負載均衡這兩種算法策略,是基於核心策略在不同條件下的具體實現方式。在分層負載均衡策略中,當服務器節點數能被專家組數整除時,先依據組限制專家路由,將專家組均勻分配到節點,確保節點間負載平衡,接着在節點內復制專家,並將復制後的專家分配到GPU,通過專家復制和重新分配來平衡GPU負載;全局負載均衡策略在其他情況下使用,不考慮專家分組,直接在全局復制專家並分配到GPU,同樣是利用冗余專家策略,通過大規模的專家復制和分配來應對較大規模的專家並行場景,以實現負載均衡。
圖表4:大規模跨節點專家並行(EP)並實現最佳負載平衡
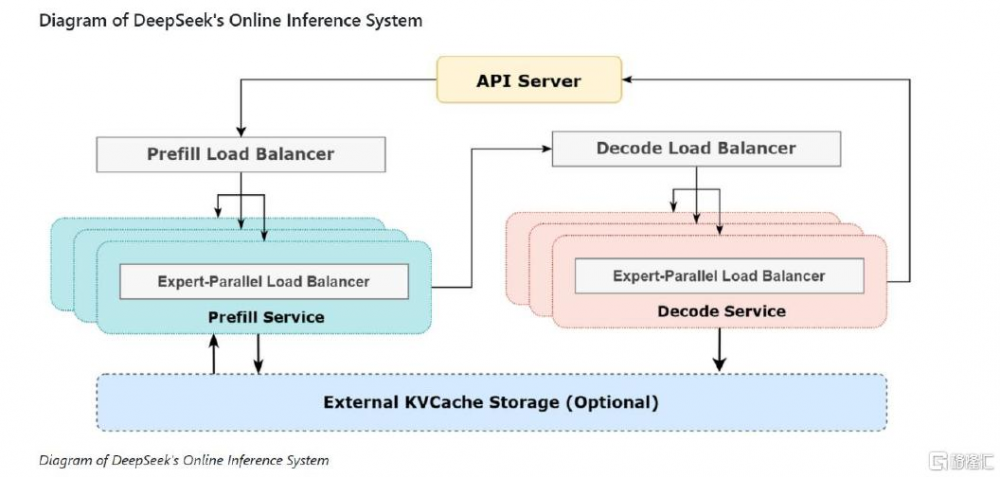
資料來源:知乎DeepSeek官方账號https://zhuanlan.zhihu.com/p/27181462601?utm_medium=social&utm_psn=1879148347039937082&utm_source=wechat_session&s_r=0,中金公司研究部
圖表5:層次負載均衡策略生成的專家復制和分配計劃
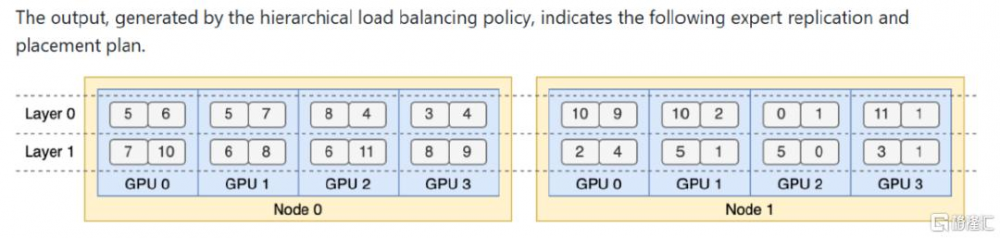
資料來源:deepseek-ai/EPLB: Expert Parallelism Load Balancer,中金公司研究部
Profile-data,訓練和推理框架的分析數據:展示通信計算重疊策略和低級實現細節。1)訓練階段,訓練配置文件數據演示了DualPipe中對一對單獨的向前和向後數據塊的重疊策略。每個數據塊包含4個MoE層。並行配置與DeepSeek-V3預訓練設置一致,包括EP64、具有4K序列長度的TP1。2)在預填充階段,利用兩個微批次來重疊計算和多對多通信,同時確保注意力計算負載在兩個微批次之間平衡。3)解碼階段,與預填充類似,解碼還利用兩個微批處理進行重疊計算和多對多通信。但是,與預填充不同的是,解碼期間的all-to-all通信不會佔用GPU SM,發出RDMA消息後,所有GPU SM都會被釋放,系統在計算完成後等待all-to-all通信完成。
圖表6:分別展示訓練、預填充和解碼階段中計算通信重疊策略。
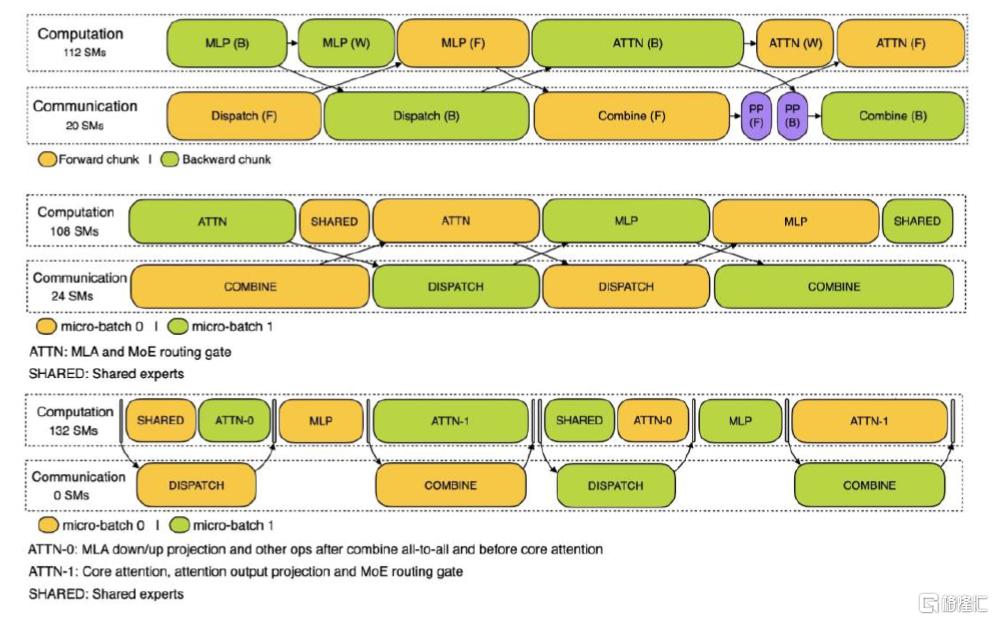
注:預填充(Prefill)階段,兩個batch計算和通信交錯進行,以計算時間來抵銷通信开銷;解碼(Decode)階段,attention拆成兩個階段,總計五個階段的流水线實現計算和通信的重疊 資料來源:profile-data/README.md at main · deepseek-ai/profile-data,中金公司研究部
Day5:开源了3FS(Fire-Flyer File System),應對AI訓練和推理工作的負載問題的高性能分布式文件系統。它利用現代固態硬盤(SSD)和遠程直接內存訪問(RDMA)網絡,提供共享存儲層以簡化分布式應用开發。在性能和可用性方面,3FS:1)採用解耦架構,結合數千個SSD的吞吐量和數百個存儲節點的網絡帶寬,實現應用程序以位置無關的方式訪問存儲資源;2)通過分片查詢鏈式復制協議(CRAQ)實現強一致性,使應用代碼邏輯簡單且易於驗證;3)文件接口具有兼容性,开發了由事務性鍵值存儲(如FoundationDB)支持的無狀態元數據服務,無需學習新的存儲API。在多樣化工作負載方面,1)能將數據分析管道的輸出組織成層次目錄結構,高效管理數據分析流水线的輸出;2)允許跨計算節點隨機訪問訓練樣本,無需預取或打亂數據集的需求;3)支持大規模訓練的高吞吐量並行檢查點;4)提供基於KV Cache的推理,作爲基於DRAM緩存的經濟高效替代方案,具有高吞吐量和更大容量。
除此之外,DeepSeek還开源了基於DuckDB和3FS的輕量級數據處理框架——Smallpond,具備高性能、易操作、可擴展的特點,它採用無服務架構,部署簡單,提供高效SQL查詢和數據處理能力,支持分布式數據處理,在多節點集群環境下能更加充分利用資源,可輕松應對 PB 級數據處理場景,滿足大數據量存儲和處理需求。
圖表7:3FS可以實現在180節點集群中的聚合讀取吞吐量爲6.6 TiB/s;25節點集群中GraySort基准測試的吞吐量爲3.66 TiB/分鐘;每個客戶端節點的 KVCache 查找峰值吞吐量超過40 GiB/s

資料來源:deepseek-ai/3FS: A high-performance distributed file system designed to address the challenges of AI training and inference workloads.,中金公司研究部
DeepSeek成本及算力測算:
毛利率水平領先
DeepSeek公开了推理成本框架,Infra優化實現高性價比。DeepSeek在3月1日公开了模型推理效率和成本,其說明在過去24小時中DeepSeek V3和R1推理服務佔用節點總和,峰值佔用爲278個節點(單節點爲單台8卡H800服務器),平均佔用226.75個節點;實現了608B輸入Token處理,以及168B輸出Token(包含APP+網頁+API)。基於這些計算節點,假設H800服務器2美元/小時的平均租賃價格,總體GPU hours成本是固定的8.7萬美元。我們以模型API定價測算收入、GPU hours租賃成本作爲考慮的核心成本項,來測算綜合毛利率:倘若這些輸入/輸出Token如果全按照R1的定價,收費是56萬美元;而按照V3的定價,收費是30萬美元左右,則對應毛利率分別爲84.5%/71%,因此綜合毛利率應在71-84.5%,這一毛利率在行業中處於領先的水平。
圖表8:DeepSeek推理成本框架與算力需求測算(細化測算版)
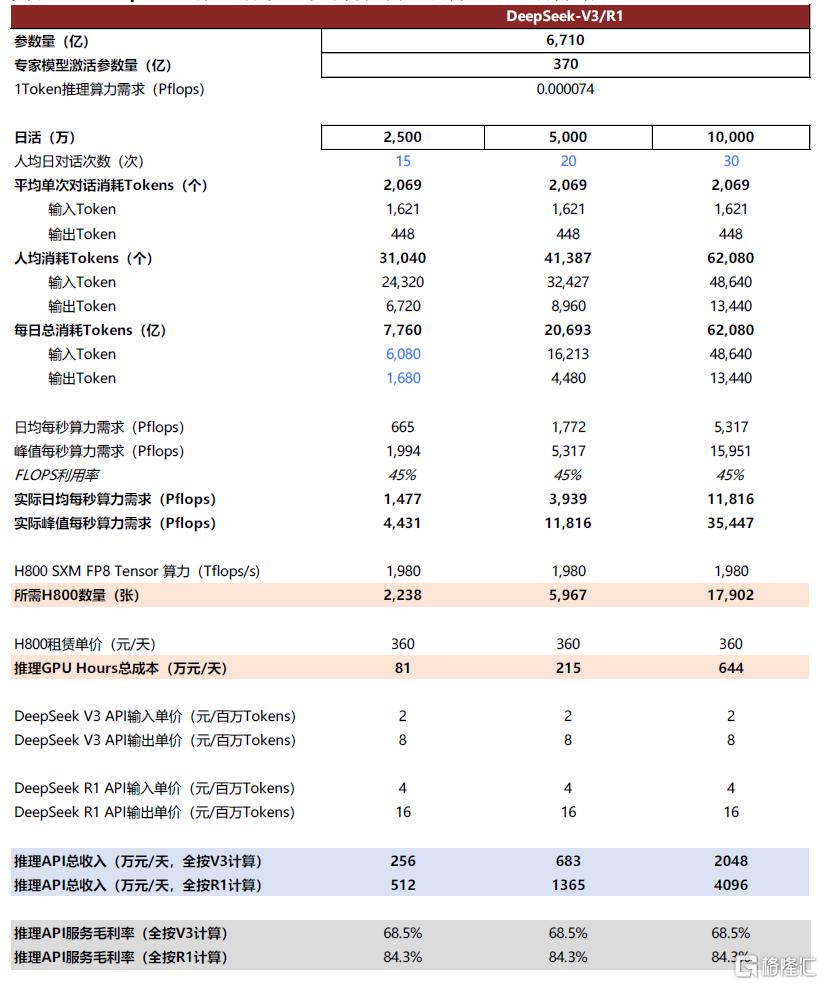
資料來源:DeepSeek知乎官方文章《DeepSeek-V3 / R1 推理系統概覽》https://zhuanlan.zhihu.com/p/27181462601,中金公司研究部
如何評價DeepSeek與其他廠商MaaS服務的利潤率對比?上述計算的DeepSeek的毛利率是在理想情況下,所有Token都實現定價並且僅扣除GPU hours成本後的結構,實際情況下這其中很多Token是C端APP和網頁消耗,現實中並不收費,因此DeepSeek整體的毛利率會低於這個水平。海外來看,如果也是按照DeepSeek公布的僅扣去GPU Hours的口徑來計算毛利率,我們預期OpenAI和Anthropic的API服務在毛利率層面也處於明顯的領先水平(也是因爲高定價,例如目前o3-mini的定價爲R1的2-3倍);而對於其他雲廠商,爲了達到相比DeepSeek原廠服務更強的穩定性來吸引客戶,我們認爲其會偏向於提供更多的冗余算力來提供服務,但由於需求的分散其集群負載率也很難達到DeepSeek原廠服務的水平,同時可能底層的優化也不如DeepSeek,進而損失部分毛利率。
如何看待DeepSeek高效推理成本對於AI算力和應用產業的影響?對於推理算力,我們認爲AI infra的進步將會提升算力利用效率,推動整個行業的繁榮,這對於未來的推理算力需求影響爲正面。我們認爲對於未來算力需求計算需要更多關注分子端AI應用Token的持續增長,其來源包括多模態應用、Manus等Agent應用,其相對更高Token消耗量的場景也會激發出更大規模的推理算力需求。對於AI應用,我們認爲隨着模型推理成本的持續降低,成本對於AI應用的商業化落地已不是瓶頸,更多AI應用的規模商業化還是要看模型能力的進一步迭代以及合適場景的持續打磨,其中2C應用方面我們更看好互聯網大廠在產品化方面的進展,2B應用方面我們則更爲關注企業服務廠商面向客戶具體場景的磨合,2025年我們也期待全球市場更多“爆款”AI應用的出現。
本文摘自中金公司2025年3月15日已經發布的《AI智道(7):DeepSeek Infra开源周總結,及算力測算一覽》
於鐘海 分析員 SAC 執證編號:S0080518070011 SFC CE Ref:BOP246魏鸛霏 分析員 SAC 執證編號:S0080523060019 SFC CE Ref:BSX734王之昊 分析員 SAC 執證編號:S0080522050001 SFC CE Ref:BSS168王倩蕾 分析員 SAC 執證編號:S0080524100004
標題:AI智道:DeepSeek Infra开源周總結,及算力測算一覽
地址:https://www.iknowplus.com/post/202787.html







