中金 :AI Agent是連接大模型和現實世界的“最後一公裏”
近期UI交互等多模態大模型持續迭代,有望加速AI Agent落地節奏。在本篇報告中,中金研究從能力升級和場景創新兩個維度探索AI Agent落地方式和形態,中金研究認爲AI Agent是連接大模型和現實世界的“最後一公裏”。
摘要
能力升級:UI識別和操作模型推動垂直場景生產力提效。Ferret-UI:蘋果首個手機端UI多模態大模型,得益於使用了大量UI數據集訓練和引入了“任意分辨率”技術,擅長理解屏幕微小元素,在大多數移動端基礎UI任務中超越GPT-4V。Adept:推出Fuyu系列多模態模型,Fuyu-8B架構簡潔,低延時、靈活性高,Fuyu-Heavy具備出色的UI理解和數學推理能力,專爲Digital Agent設計。OpenAI GPT-4o:原生多模態賦能,多模態交互和情緒理解能力出色,可有效提高人機交互體驗。
能力升級的意義:加速AI Agent落地節奏,賦能AI終端推動換機潮。軟件維度:UI及其他專有大模型的推出能夠增強或補齊AI Agent能力,使得Agent離我們日常工作生活越來越近,ToB和ToC傳統軟件均有望迎來新一輪的生產力提效;相較於傳統軟件工具,AI Agent具有更強的適應性,有望將API和軟件工具串聯起來,成爲連接大模型和現實世界的“最後一公裏”。終端維度:面向智能交互的多模態大模型是端側Agent落地的基石,有望賦能AI PC和AI手機等終端,加速端側設備換新潮。
場景創新:AI Agent有望开拓更豐富落地場景,Automation、IPA、TRPG初露曙光。依托於AI Agent的感知環境、自主決策和行動等功能,兼具工具和情感屬性的特點,AI Agent有望开拓出更多更豐富甚至全新的應用場景。Automation(業務流程自動化):Adept Experiment助力企業實現跨平台工作流,降低軟件使用門檻。IPA(智能個人助理):Google Astra具有理解、推理和記憶的功能,通過攝像頭廣泛吸收信息和識別場景;Dola.AI能夠便捷高效地幫助用戶安排個人日程,產品形態簡潔。TRPG(桌上角色扮演遊戲):盜夢筆記以AI Agent爲主持人,提供更有趣和個性化的玩家遊戲體驗。
風險
技術發展不及預期;商業化落地進展不及預期;行業競爭加劇。
正文
能力升級:UI識別和操作模型推動垂直場景生產力提效
Ferret-UI:蘋果首個手機端UI多模態大模型,擅長理解屏幕微小元素
2024年4月8日,蘋果的端側AI論文提出多模態大語言模型Ferret-UI[1],能夠更有效地理解手機屏幕信息並與之進行交互,具備引用(referring)、定位(grounding)和推理功能[2],不僅超越大多數开源UI(User Interface,用戶界面)多模態模型,並且在大多數移動端基礎UI任務(elementary UI tasks)中超越GPT-4V。中金研究認爲,Ferret-UI模型的推出有望爲蘋果在端側部署AI建立一定先發優勢,同時進一步驗證了在特定場景進行針對性優化(例如技術架構、數據集等方面)的垂類模型(例如UI多模態大模型)的能力表現或優於通用大模型。
功能維度:Ferret-UI採用大量UI數據集,更擅長理解細節和微小元素
Ferret-UI基於2023年蘋果與哥倫比亞大學研究團隊聯合發布的多模態大模型Ferret構建,更聚焦移動端用戶的交互體驗,並根據移動端UI屏幕的特點進行了以下針對性優化:1)引入“任意分辨率”(any resolution,簡稱anyres)技術,能夠識別和處理任意寬高比的屏幕,並識別圖標、按鈕、文本等小尺寸圖像/微小元素;2)在理解屏幕整體功能的基礎上,能夠基於人機對話自主推斷任務並提出相應的可行操作,從而幫助用戶完成界面導航等开放式任務,中金研究認爲這是AI Agent在手機端感知環境、進行決策並提出建議的初步呈現。
圖表1:Ferret-UI能夠有效識別圖標、按鈕等微小元素和理解細節
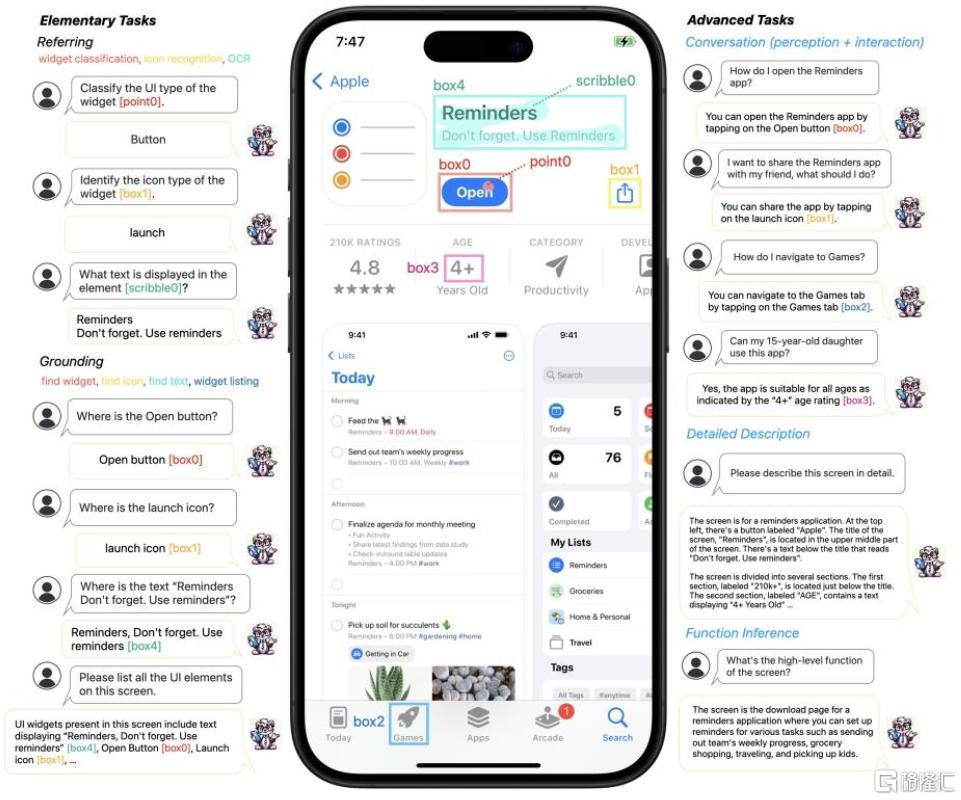
資料來源:You, Keen et al. “Ferret-UI: Grounded Mobile UI Understanding with Multimodal LLMs.” (2024),中金公司研究部
技術維度:Ferret-UI引入“任意分辨率”技術以適應UI場景任務
Ferret的技術架構包含經預訓練的圖像編碼器、空間感知視覺採樣器和純解碼器語言模型三個組成部分:圖像編碼器用於提取圖像嵌入,即將圖像轉化爲模型能夠理解的向量空間;空間感知視覺採樣器專爲實現“混合區域表示”技術而構建,能夠處理不同形狀之間的稀疏性差異,用於提取區域連續特徵;語言模型用於聯合圖像、文本和區域特徵進行信息的匯總分析。其中,“混合區域表示”(Hybrid Region Representation)技術是在LLM範式下提升Ferret模型引用、定位能力以及二者間緊密程度的新式有效手段,其“離散坐標+連續視覺特徵”的區域表示方式能夠更靈活地將點、框或復雜多邊形等不同形狀的指定區域轉換爲適合語言模型處理的格式,從而有效提高模型理解和描述圖像元素的准確性。
圖表2:Ferret模型的技術架構
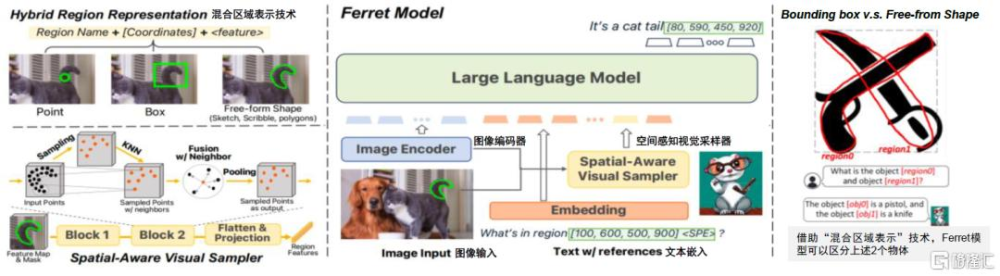
資料來源:You, Haoxuan et al. “Ferret: Refer and Ground Anything Anywhere at Any Granularity.” ArXivabs/2310.07704 (2023): n. pag.,中金公司研究部
Ferret-UI共有base和anyres兩個版本,其中,Ferret-UI-base直接沿襲Ferret的架構,Ferret-UI-anyres則進一步融入細粒度圖像功能,實現“任意分辨率”技術以處理不同寬高比的屏幕。細粒度圖像功能通過放大細節來解決UI屏幕中識別較小對象的問題,從而提升模型對UI元素的理解精度。Ferret-UI-anyres工作流程主要包含以下步驟:1)獲取屏幕圖片,分別將其轉換爲低分辨率完整圖像和分割成Sub0、Sub1兩個子圖,從而更好地捕捉UI細節;2)將上述三張圖輸入圖像編碼器中獲得三個單獨的特徵編碼,並利用映射層對其執行特徵變換;3)將文本信息輸入文本嵌入器和視覺採樣器,後者會將含有區域信息的文本生成區域連續特徵;4)將圖片編碼、文本嵌入和區域連續特徵全部輸入LLM並生成最終結果。
圖表3:Ferret-UI-anyres用“放大鏡”觀察並識別UI界面,類似於自動駕駛的前融合技術
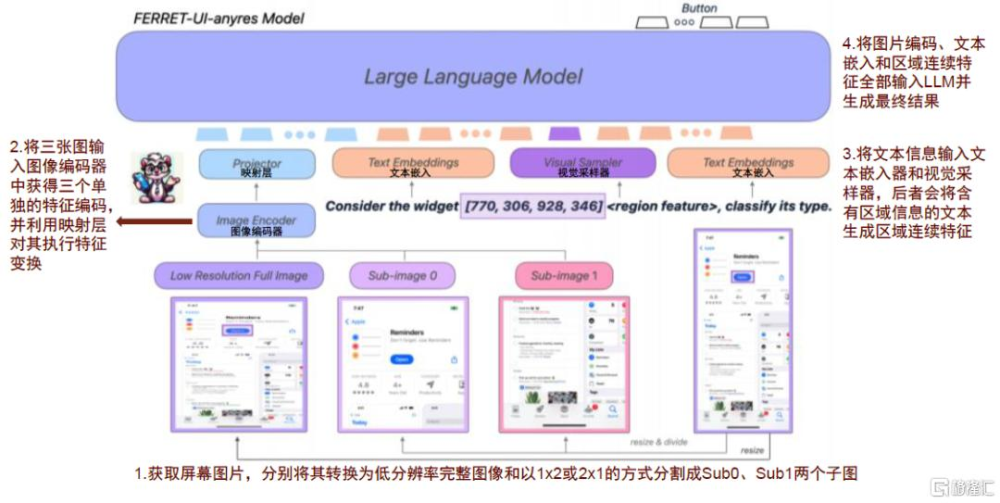
資料來源:You, Keen et al. “Ferret-UI: Grounded Mobile UI Understanding with Multimodal LLMs.” (2024),中金公司研究部
Adept:推出Fuyu系列多模態模型,加速Digital Agent落地
Adept自創立以來便一直廣受大衆關注,近期Adept在Fuyu-8B模型的基礎上,進一步發布專爲Digital Agent設計的多模態模型Fuyu-Heavy。中金研究認爲,此番Adept升級其旗下模型的多模態理解和推理能力,或意味着Adept向Agent落地更進一步。
Adept:致力於开發能夠實現軟件自動化操作的AI Agent
Adept由David Luan聯合Ashish Vaswani和Niki Parmar於2022年4月正式創立。聯合創始人Ashish Vaswani和Niki Parmar[3]曾就職於谷歌AI研究部,並於2017年合作提出Transformer架構,是AI大模型時代技術基石的重要奠基人。而David Luan曾先後擔任OpenAI工程副總裁和Google Brain主管,並基於Transformer架構構建了GPT-2和GPT-3模型,同樣具備深厚的技術背景。
Adept的目標是基於生成式AI建立全新的通用操作工具,使其充當AI Teammate來幫助人類完成工作,實現軟件自動化操作。2022年以來,Adept先後發布Action Transformer(ACT-1,2022)、Fuyu-8B(2023)和Fuyu Heavy(2024)大模型,其中ACT-1具備UI圖形理解和執行任務的能力,並可連接瀏覽器執行點擊、輸入、滾動等具體操作,可視作基礎模型(須學會使用各種軟件工具、API和網頁應用)的雛形,而Fuyu系列大模型專爲Digital Agent設計,支持任意圖像分辨率、回答圖形圖表相關問題和對屏幕圖像進行細粒度定位。此外,Adept於2023年9月正式發布由ACT-2模型驅動的Adept Experiments[4],其上线的首個實驗可以支持企業用戶創建用於Web的小型工作流構建器,從而幫助用戶簡化任務流程、提高工作效率,中金研究將在後文對其做更深入的探討。
截至目前,Adept共獲得兩筆投資,總融資金額達4.15億美元[5]。2022年成立之初,Adept即得到包括LinkedIn創始人Reid Hoffman、特斯拉前AI總監Andrej Karpathy在內的多名業界名人6500萬美元的注資。2023年3月,Adept再獲來自由頂級風投機構General Catalyst和Spark Capital領投[6],微軟、英偉達等業界大廠跟投的總計3.5億美元融資,公司估值突破10億美元[7]。
圖表4:Adept產品和融資發展歷程

資料來源:Adept官網,中金公司研究部
Fuyu-8B:簡潔而強大的多模態开源模型,具備多種圖文任務處理能力
Fuyu-8B具備強大的復雜圖像理解能力和高可拓展性。2023年10月,Adept正式發布並开源了80億參數多模態大模型Fuyu-8B[8]。Fuyu-8B不僅具備圖表、圖形和文本理解能力,還能夠釐清復雜圖像中元素的相互關系,並可根據用戶指令正確歸納所需的圖表信息。此外,Adept在Fuyu模型基礎上進一步开發了具備OCR、UI元素細粒度識別與問答等功能的內部模型,展現出Fuyu系列模型強大的可拓展性,爲未來Adept在UI識別和操作領域發展奠定基礎。
Fuyu-8B架構簡潔,具備低延時和高靈活性的特點。Fuyu-8B採用decoder-only架構,無圖像編碼器,並支持處理任意分辨率的圖像。工作流程上,Fuyu-8B首先將輸入圖像分割成若幹補丁(patches),然後將其直接线性投影到Transformer第一層,省略了嵌入查找(Embedding Lookup)步驟,同時利用圖像轉換行符號告知模型何時斷行,最後由Transformer解碼器輸出最終結果(或類似於ViT架構)。這一工作流程簡化了Fuyu-8B的訓練和推理過程,大幅提高了模型的運行速度,使其能夠在100毫秒內即可反饋大尺寸圖像的處理結果。
圖表5:Fuyu-8B採用decoder-only架構,可支持處理任意分辨率的圖像
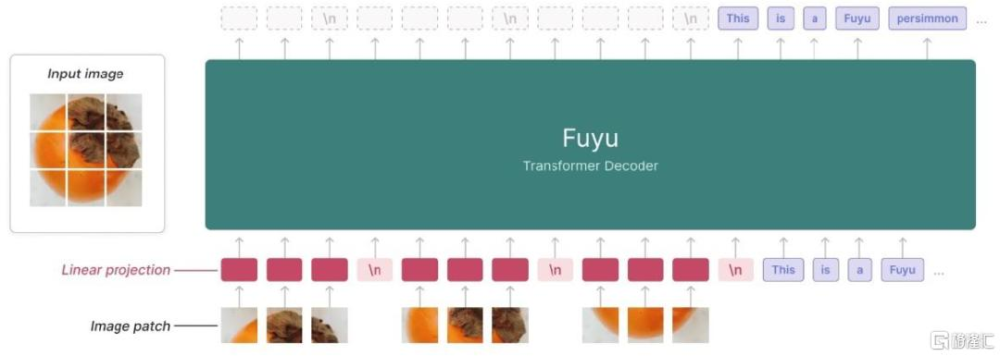
資料來源:Adept官網,中金公司研究部
Fuyu-Heavy:專爲數字Agent設計,UI理解能力出衆
Fuyu-Heavy基於Fuyu-8B打造,是未來Agent產品的基礎模型。2024年1月,Adept正式發布Fuyu-Heavy多模態模型[9],其研究團隊花費4個月時間在Fuyu-8B的基礎上着力解決多模態模型在文本和圖像數據方面的諸多問題:1)大規模圖像數據輸入造成的內存使用量激增和雲存儲輸入輸出限制;2)圖像模型的不穩定性;3)高質量圖像數據的稀缺性;4)圖像文本任務比例的平衡性。中金研究認爲,一方面,Fuyu-Heavy驗證了Fuyu系列模型的可拓展性,未來可以scale up;另一方面,Fuyu-Heavy作爲“小而精”[10]垂類模型能夠適配更多平台,有望爲Adept發布Agent產品奠定模型基礎。
Fuyu-Heavy具備出衆的UI界面理解和數學推理能力。根據公司官網,截至2024年1月,Adept宣稱Fuyu-Heavy爲全球僅次於GPT-4V和Gemini Ultra的第三強多模態模型,而Fuyu-Heavy的規模僅爲後者的5%-10%[11]。模型能力方面,Fuyu-Heavy不僅具備強大的多模態推理能力,尤其是UI界面的理解能力,還能夠求解較爲復雜的數學問題,表現出較強的數學推理能力。此外,在傳統多模態基准測試和標准文本基准測試中,Fuyu-Heavy與Gemini Pro、Inflection-2表現相當。
圖表6:Fuyu-Heavy具備出衆的UI理解能力和數學推理能力
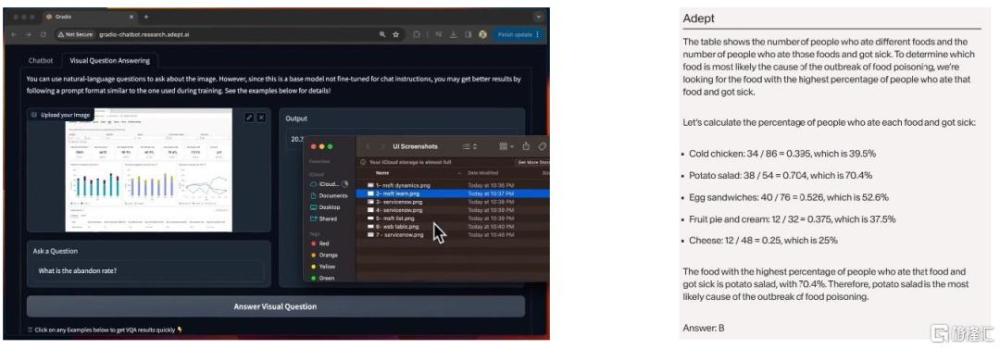
資料來源:Adept官網,中金公司研究部
場景創新:AI Agent有望开拓更豐富落地場景,Automation、IPA和TRPG初露曙光
盡管AI技術潛力巨大、AI應用長期有望百花齊放,但海內外普遍認爲目前尚未找到能夠實現爆發式增長和規模化收入增量的AI場景,AI原生/殺手級應用尚未出現,缺少應用方向或已成爲AI板塊繼續上行的重要擔憂。目前關於AI應用落地相對較快的方向的市場共識是知識庫、個人助理、代碼編寫和情感陪護等,中金研究認爲依托AI Agent的環境感知與交互、自主規劃和行動等功能,兼具工具和情感屬性的特點,AI Agent有望开拓出更豐富甚至全新的應用場景。下文中金研究將以Adept Experiment、Google Astra、Dola.AI和盜夢筆記爲例,介紹業務流程自動化(Automation)、智能個人助理(IPA)和桌上角色扮演遊戲(TRPG)三大創新場景。
Adept Experiments:Workflows助力企業實現跨平台工作流
Adept Experiment基於ACT-2模型,幫助企業完整執行軟件工作流(Workflows),實現軟件側的泛化能力。Workflows由ACT-2(基於Fuyu-Heavy模型微調得到)提供支持,對於UI理解、數據理解和執行指令進行進一步優化,實現端到端的AI agent功能。Workflows依托於軟件使用的感知維度,直接通過像素感知屏幕,通過坐標和點擊進行軟件維度流程操作。其功能主要致力於快速學習流程性或復雜任務,過程中需要前期的詳細提示。據Adept官網,與Adept合作的企業客戶體驗到超95%的可靠性[12]。
Adept Workflows具備跨平台執行工作流的能力,可以快速學習和執行工作流,降低軟件使用門檻。Workflows具備跨平台延展性,能夠理解屏幕上下文,嫁接不同軟件的工作流程,可實現跨軟件操作,在文本簡潔、HTML難以編程運作的場景也可實現工作流執行。例如,招聘者可以基於Adept定義工作流程,自動對接候選人的郵件申請,一鍵獲取候選人郵件及空闲時間,並轉移到面試輪次。
圖表7:Adept能夠處理重復性工作任務,例如在Excel表格中檢查招聘候選人郵箱是否有效
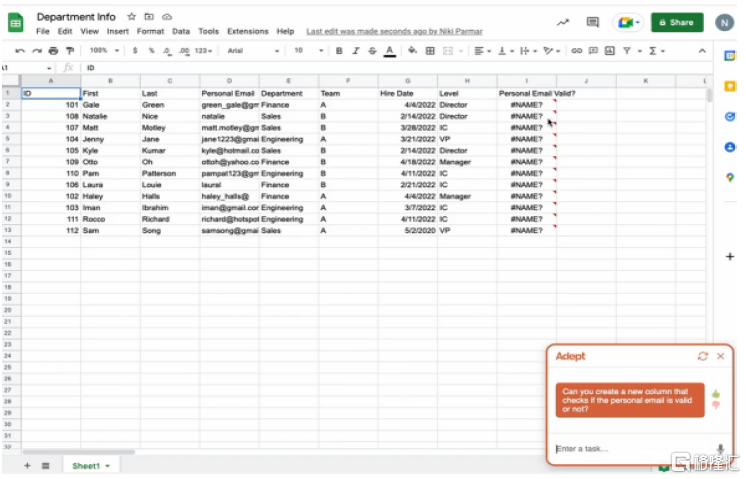
資料來源:Adept官網,中金公司研究部
圖表8:Adept能夠跨平台執行工作流,例如幫助保險代理人從郵件提取理賠信息,並填入其他軟件的表單中
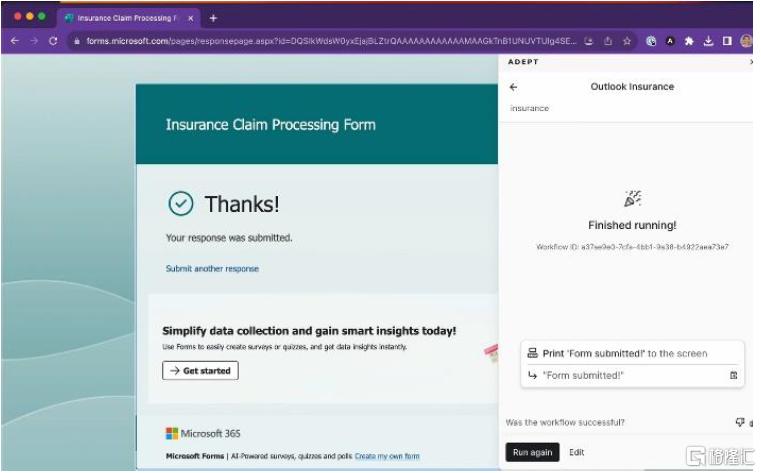
資料來源:Adept官網,中金公司研究部
Google Astra:多模態交互助手,布局端側模型和終端設備
Project Astra以Gemini模型爲基礎,能對多模態信息實時推理,感知用戶所處環境,是Google探索AI Agent應用的重要裏程碑。爲了使Astra在日常生活中真正實用,DeepMind採用了視頻連續編碼、視頻和語音嵌入事件時間軸、緩存信息的技術,以突破原有Agent存在的滯後或延遲問題。
Astra具有理解、推理和記憶的功能,通過攝像頭廣泛吸收信息和識別場景,從而更好滿足用戶需要。以領先的Gemini模型作爲底層支撐,Astra交互更加迅速、擬人化和自然化。例如,工作場景中,舉起手機對准代碼,Astra可迅速解釋代碼的構成和功能,提高工作效率;生活場景中,通過建築物的外觀,Astra可定位並介紹所在的地理位置,改善出行體驗。Astra視覺識別和記憶性能強大,可高效記憶上下文和空間物體,例如能尋找一晃而過的眼鏡位置。中金研究認爲,Astra能多場景即刻響應用戶需求,有望爲Google進一步打造跨軟件和系統的AI Agent應用賦能和積累經驗。
模型側,雲端模型側重長文本、端側模型能夠實現離线交互,拓展Agent的端側生態。Google發布Gemini 1.5 Flash和Pro模型,分別支持100萬/200萬token長文本,改善記憶問題,此外,即將在API層面更新視頻輸入拆幀能力、實現並行執行請求和已上傳文本緩存功能。Gemini Nano端側模型則定位手機端小模型,無需聯網、在系統層面集成交互性能,即可在電話交互、調用手機應用過程中低延時實現。
圖表9:Astra記憶能力突出,例如能迅速報出之前攝像頭一晃而過的眼鏡位置

資料來源:Google官網,中金公司研究部
圖表10:用戶可佩戴智能眼鏡使用Astra,例如其能識別草圖並建議用戶添加高速緩衝存儲器以提升方案速度
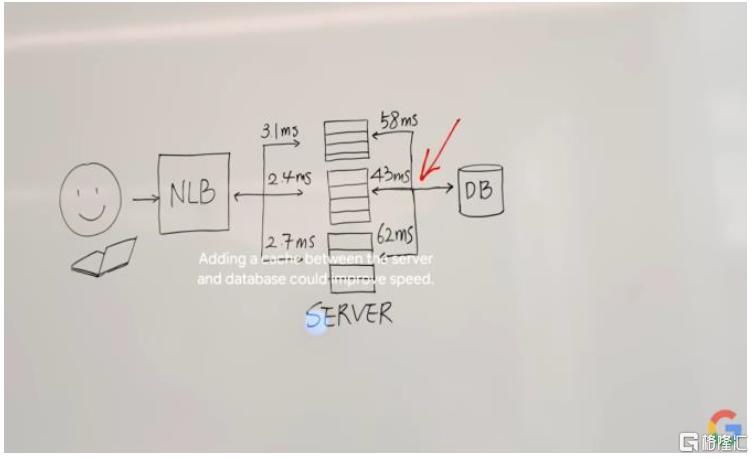
資料來源:Google官網,中金公司研究部
Google完成端側設備拓展,Google智能眼鏡也能對其支持,意味着未來脫離手機和電腦使用AI Agent成爲可能。從演示效果看,智能眼鏡上使用Astra同樣流暢,可提供工作改進方案建議、識別物體、數學問題輔導、與寵物互動,使AI融入了日常生活的方方面面。中金研究認爲,眼鏡等終端設備推出有望推動AI Agent擴展更多應用場景快速滲透,夯實Google生態。
Dola.AI:個人日程助手,助力釋放更多時間價值
Dola.AI是由Orion Arm公司开發的最新個人AI日程助手。Dola.AI的主要功能是以較小的時間成本幫助用戶高效地安排各類個人日程,從而爲他們釋放更多的時間用於工作和生活。Dola.AI的研發團隊來自美國麻省理工學院、復旦大學等多所海內外頂尖高校,並在3個月內迭代了百余個版本,目前支持在Apple Messages、WhatsApp、Telegram、Line和微信等多個平台使用,並已在全球範圍內積累了超15萬用戶[13]。中金研究推測,Dola.AI的技術實現路徑可能是“多模態模型+工程化”,更多是工程能力上的進一步積累。
與傳統日歷軟件相比,Dola.AI具有以下優勢:1)支持用戶通過自然語言交互設置日程安排,並可根據用戶時間規劃偏好自動設置預期用時,極大程度地提升了用戶制定、修改和取消日程的便捷程度;2)支持語音、圖像、文本等多模態信息的輸入,能夠將人們從會議紀要、提取圖片信息等瑣碎任務中解放出來;3)具備上下文記憶和多設備日程同步能力,支持用戶隨時隨地更新日程;4)可無縫集成至現有社交軟件,無實體應用或小程序,產品架構簡潔,是現有的最小可行產品(Minimum Valuable Product,MVP)。
圖表11:Dola.AI能夠識別文本、語音、圖像等多模態信息並自動導入iPhone日歷
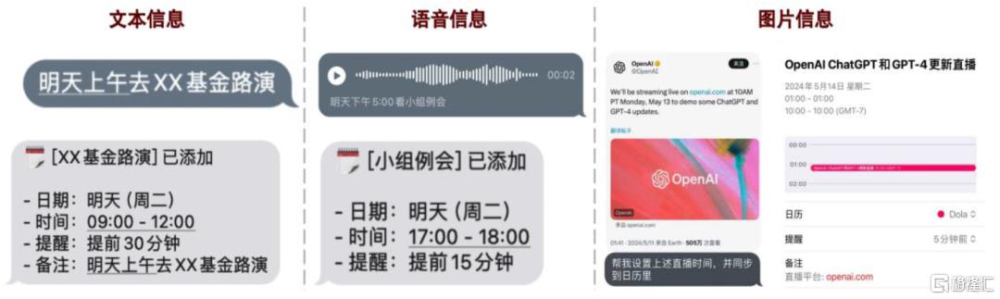
資料來源:Dola.AI,中金公司研究部
圖表12:Dola.AI能夠與用戶通過自然語言交互並設置、修改和刪除相應日程
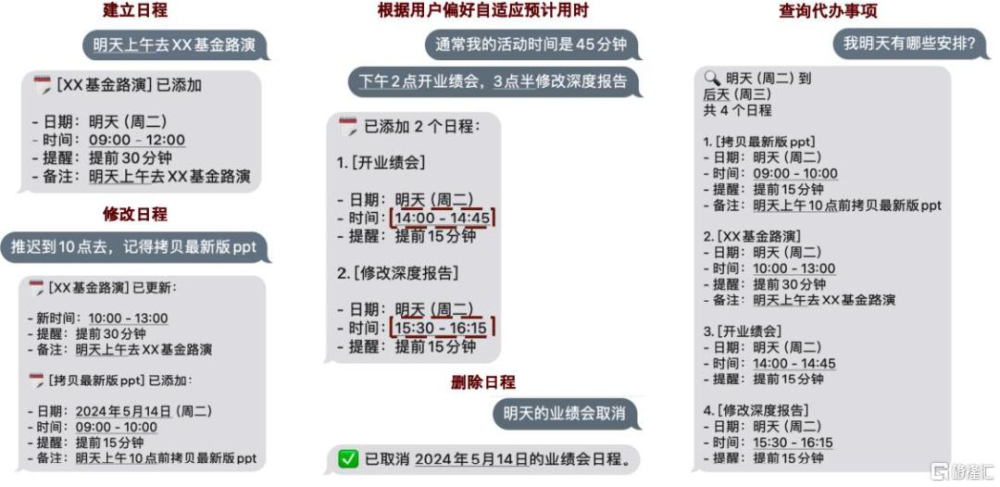
資料來源:Dola.AI,中金公司研究部
盜夢筆記:以AI Agent爲主持人,提供更有趣玩家遊戲體驗
桌上角色扮演遊戲(Tabletop Role-Playing Game,TRPG)是一種基於故事和角色扮演的遊戲,玩家會在一個設定好的虛擬世界中扮演虛構角色並展开冒險和互動。TRPG遊戲的參與者通常爲一名主持人(COC遊戲中稱爲KP,Keeper of ArcaneLore,奧祕守密人;DND遊戲中稱爲DM,Dungeon Master,地下城城主)和多名玩家,其中主持人負責創造遊戲世界、設定情節、扮演非玩家角色(NPC)並引導遊戲進程,玩家則自由控制自己所扮演的角色,通過角色行動和對話的方式推動故事發展。與電腦角色扮演遊戲(Computer Role-Playing Game,CRPG)不同,TRPG無需電子軟件輔助,而是通過面對面語言交互的方式進行。而與劇本殺相比,TRPG各個模組之間具有一定連續性和可養成性,每個模組針對玩家也會有些許變化,因此TRPG具有更強的可玩性與玩家粘性。
較爲出名的TRPG遊戲包括克蘇魯的呼喚(Call of Cthulhu, COC)和龍與地下城(Dungeons& Dragons, DND),它們也代表了兩種不同類型的TRPG。其中COC側重角色的技能和屬性,DND側重自由冒險和探索。雖然COC和DND的背景設置各異,例如COC納入了瘋狂值(Sanity)等特殊元素,而DND內置了豐富的劇情和任務,規則復雜度也有所不同,但是二者都強調玩家之間的互動和決策。近期拾象科技开發了一款以AI Agent爲主持人的“盜夢筆記”遊戲,目前處於內測階段。盜夢筆記遊戲共有自由幻想區、萌新區、阿卡姆和DND四個模塊,其中自由幻想區和DND仍在开發中。
盜夢筆記萌新區接近傳統TRPG遊戲,玩家需要扮演偵探,在與AI Agent的交互中尋找故事真相。與COC類似,萌新區遊戲擁有復雜而完善的角色設置體系,玩家在正式進入模組前需要先行設定自身角色的職業、技能等基本屬性。以模組《追書人》爲例,玩家在正式开啓遊戲後將扮演私家偵探探索托馬斯·金博爾書房午夜響動的真相,而AI Agent則會扮演主持人設置遊戲基本場景並引導玩家展开探索,並會在玩家偏離遊戲主线時及時提醒。同時,AI Agent能夠根據玩家技能釋放成功與否自動生成不同回復,對遊戲進程具有較充分的把握,也提高了玩家的遊戲體驗。
圖表13:AI Agent能夠作爲主持人引導遊戲進程
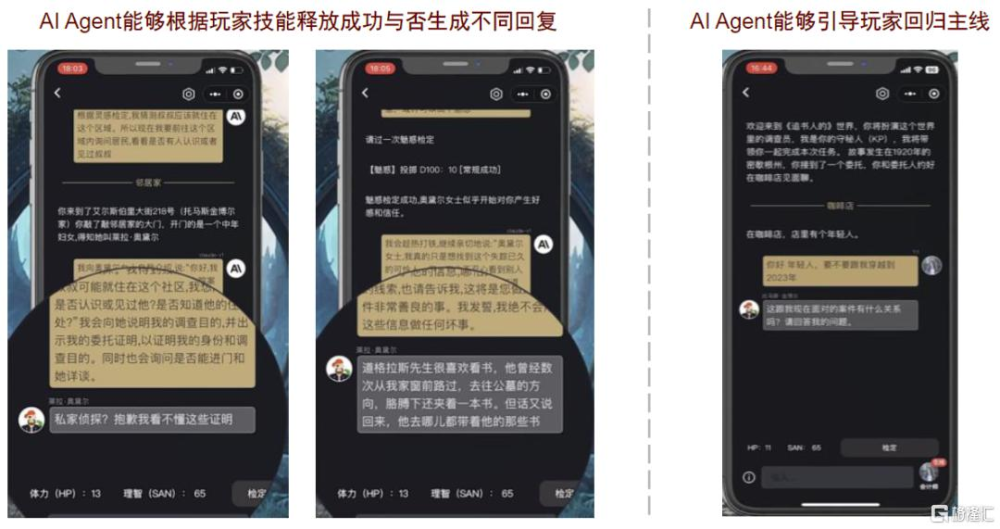
資料來源:海外獨角獸公衆號,中金公司研究部
而在阿卡姆小鎮遊戲中,200個由AI Agent扮演的角色需在同一虛擬城鎮中共同生活十年,是多Agent協同的範本之一。阿卡姆小鎮是克蘇魯神話系列小說中的一座虛構城市,遊戲設定中其發生超自然事件的頻率較高。在阿卡姆小鎮生活的角色除額外擁有瘋狂值屬性外,其他特徵均與常人類似,這意味着他們不僅會自主決策、彼此交互、做出行動並產生相關記憶,還會在目睹某些特定事件後喪失理智、陷入瘋狂。遊戲實驗發現,若無外界介入,幾乎所有AI Agent扮演的角色都會在十年後陷入瘋狂,在對話時Agent也會輸出一些渾渾噩噩的回復。而當玩家扮演的角色進入小鎮並與Agent交互後,他們可能觸發隱藏探索任務、阻止特定事件發生並改變Agent的記憶和行爲,從而大幅改變前述“世人皆瘋”的實驗結局。
圖表14:阿卡姆小鎮:AI Agent能夠彼此交互,並根據所扮演角色的狀態生成相應對話

資料來源:bilibili平台盜夢筆記遊戲官方账號,中金公司研究部
爲給玩家帶來更好的遊戲體驗,拾象科技主要採取了以下技術細節:1)選用多個大模型(例如OpenAI的GPT-4和Anthropic的Claude3)測試遊戲效果,採用中等尺寸模型並利用阿卡姆小鎮遊戲數據和ChatGPT、Claude等外部大模型生成的語料對其進行微調(Finetune)[14],盡量避免大模型出現幻覺問題;2)減少上下文調用頻率以降低上下文語義衝突的概率並節約成本;3)調用多個AI Agent兼任主持人,例如分別負責整體遊戲規則理解、故事线生成、NPC情感、技能判定等,從而避免上下文遺忘和穿模;4)具備多Agent協作和記憶模塊,在阿卡姆小鎮中提取關鍵信息,並在每天12時同步;5)具備Function Calling模塊,战鬥場景中較好地融合了BUFF、武器和門禁系統等。
中金研究認爲,AI Agent具備出色的記憶和語言交互能力,能夠勝任主持人角色。TRPG的遊戲劇本和規則設定動輒多達400余頁,因此熟悉劇本對主持人而言是一項重大挑战。而AI Agent出色的記憶和語言交互能力能夠使其在充分熟悉遊戲劇本的基礎上,根據玩家的反饋有序推進遊戲進程,天然滿足遊戲主持人的要求。
風險提示
技術發展不及預期。目前UI多模態大模型仍處於相對早期的發展階段,其技術進展存在一定不確定性;隨着通用大模型持續迭代、垂直場景專有大模型不斷湧現、Agent復雜程度不斷增加,AI Agent或出現新的構建方式和落地形態。
商業化落地進展不及預期。目前融入UI交互模型的端側Agent正處於產業探索的初步階段,如何在終端設備釋放AI Agent能力有待進一步研究,是否需要以及如何打破原有封閉生態也需要更多資源和利益角度的衡量。此外,若搭載UI模型的相關終端硬件能力升級和操作系統的迭代速度不及預期,也可能影響Agent落地節奏。
行業競爭加劇。面向智能交互的多模態大模型是端側Agent落地的基石,近期海內外科技巨頭和AI初創公司陸續推出UI識別和操作模型、類Agent產品,未來模型層和應用層的行業競爭可能會進一步加劇。
主:本文摘自中金研究於2024年5月26日已經發布的《人工智能十年展望(十九):漸行漸近的AI Agent:能力升級,場景創新》,分析師:於鐘海 S0080518070011;魏鸛霏 S0080523060019;遊航 S0080523010001;王倩蕾 S0080122090111;王之昊 S0080522050001
標題:中金 :AI Agent是連接大模型和現實世界的“最後一公裏”
地址:https://www.iknowplus.com/post/111760.html







