挑战英偉達,需要另闢蹊徑
Groq是近期AI芯片界的一個明星。原因是其號稱比英偉達的GPU更快。3月2日,據報道,Groq收購了一家人工智能解決方案公司Definitive Intelligence。這是 Groq 在 2022 年收購高性能計算和人工智能基礎設施解決方案公司 Maxeler Technologies 後的第二次收購。Groq來勢很兇。
自從ChatGPT爆火以來,英偉達憑借GPU在市場上獨孤求敗,雖然也出現了不少挑战者,但都沒有像Groq這般引人注意。
成立於2016 年的Groq,其創始人是被稱爲“TPU之父”的前谷歌員工喬納森·羅斯,團隊中成員不乏有谷歌、亞馬遜、蘋果的前員工。這幫人通過簡單的設計开發了一款LPU(語言處理單元)推理引擎。就是這個LPU芯片讓Groq在AI市場上異軍突起,引得大家刷屏。據悉,LPU可在當今大火的LLM(大語言模型)中展現出非常快速的推理速度,比GPU有顯著提升。不要小看AI推理的市場,2023年第四季度,英偉達有4成收入來源於此。因此,衆多英偉達的挑战者是從推理切入的。

那么,它是如何做到速度快的?爲何能夠叫板英偉達?在芯片架構和技術路徑上有哪些可圈可點之處?。。。。對於這款引發廣泛關注的芯片,很多人也希望能夠了解其背後究竟有哪些玄妙?近日,半導體行業觀察有幸採訪到了北京大學集成電路學院,長聘副教授孫廣宇,孫教授爲我們提供了一些專業見解,至於網上對Groq價格的各種推測,其比性能等估算更復雜,本文在此將不作過多探討,而是側重於技術層面的解析,以期爲讀者帶來一些啓發。
最快的推理速度?
我們處於一個快節奏的世界中,人們習慣於快速獲取信息和滿足需求。研究表明,當網站頁面延遲300 - 500毫秒(ms)時,用戶粘性會下降20%左右。這在AI的時代下更爲明顯。速度是大多數人工智能應用程序的首要任務。類似ChatGPT這樣的大語言模型(LLM)和其他生成式人工智能應用具有改變市場和解決重大挑战的潛力,但前提是它們足夠快,還要有質量,也就是結果要准確。
要想快,就要計算和處理數據的能力強大。據Groq的白皮書【Inference Speed Is the Key To Unleashing AI’s Potential】【1】指出,在衡量人工智能工作負載的速度時,需要考慮兩個指標:
輸出Tokens吞吐量(tokens/s):即每秒返回的平均輸出令牌數,這一指標對於需要高吞吐量的應用(如摘要和翻譯)尤爲重要,且便於跨不同模型和提供商進行比較。
首個Token返回時間(TTFT):LLM返回首個令牌所需的時間,對於需要低延遲的流式應用(如聊天機器人)尤其重要。
2)影響模型質量的兩個最大因素是模型大小(參數數量)和序列長度(輸入查詢的最大大小)。模型大小可以被認爲是一個搜索空間:空間越大,效果越好。例如,70B參數模型通常會比7B參數模型產生更好的答案。序列長度類似於上下文。更大的序列長度意味着更多的信息——更多的上下文——可以輸入到模型中,從而導致更相關和相關的響應。
在Anyscale的LLMPerf排行榜上(這是一個針對大型語言模型(LLM)推理提供商的性能、可靠性和效率評估的基准測試),Groq LPU在其首次公开基准測試中就取得了巨大成功。使用Groq LPU推理引擎運行的Meta AI的Llama2 70B,在輸出tokens吞吐量上,實現了平均185 tokens/s的結果,比其他基於雲的推理提供商快了3到18倍。對於首個Token返回時間(TTFT),Groq達到了0.22秒。所有Llama 2的計算都在FP16上完成。
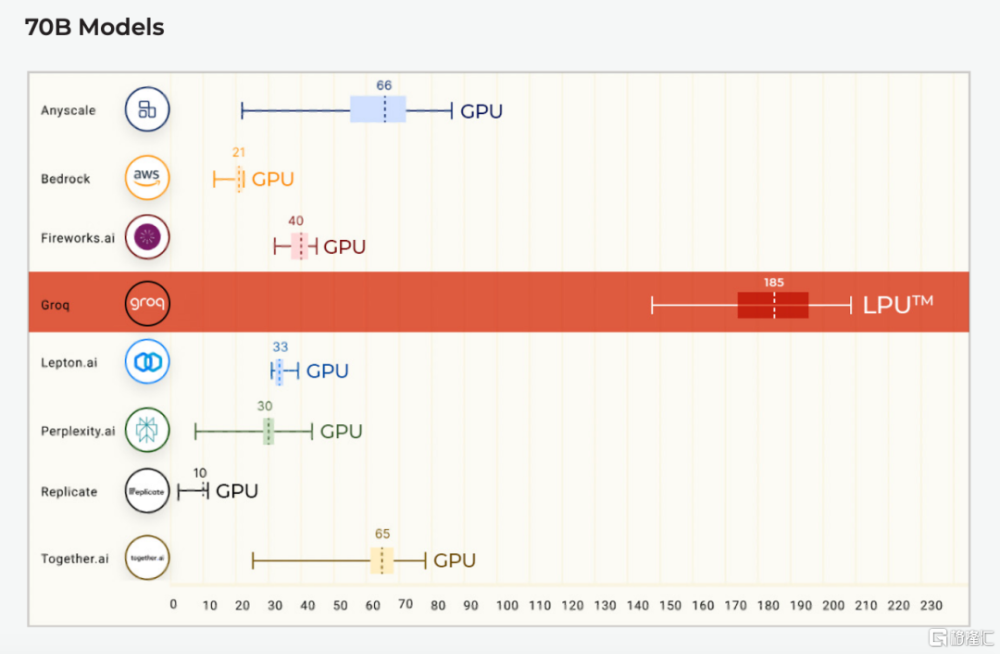
輸出tokens吞吐量(tokens/s)
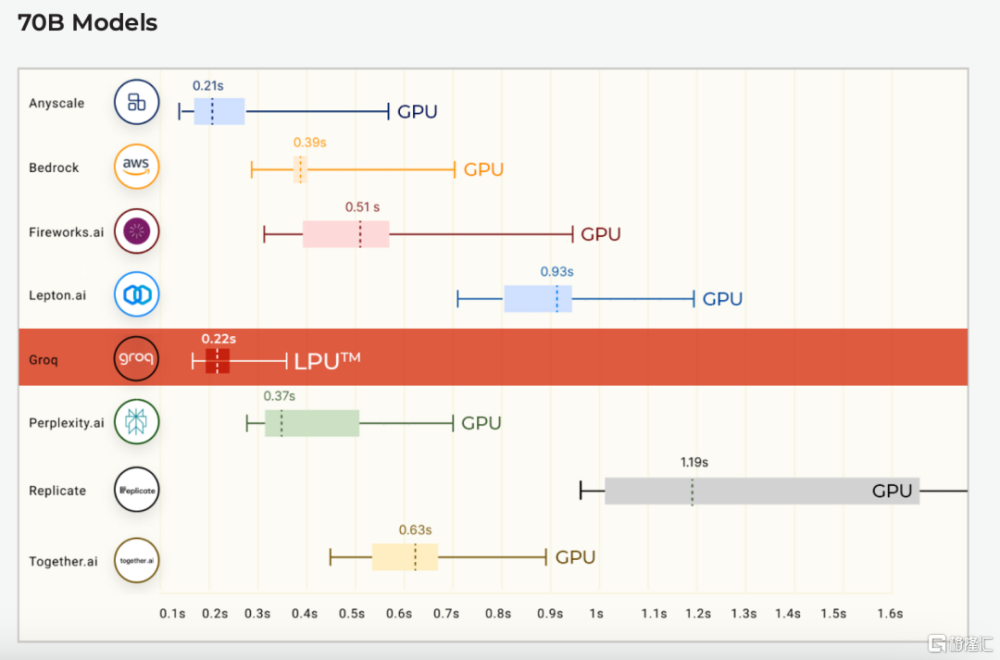
首個tokens的返回時間
這是如何實現的呢?
挖掘深度學習應用處理過程中的“確定性”
如今行業不少人的共識認爲,英偉達的成功不僅僅歸功於其GPU硬件,還在於其CUDA軟件生態系統。CUDA也被業界稱爲是其“護城河”。那么,其他AI芯片玩家該如何與英偉達競爭?
孫教授表示,誠然,CUDA爲GPU开發者提供了一個高效的編程框架,方便編程人員快速實現各種算子。不過,僅靠編程框架並不能實現高性能的算子處理。因此,英偉達有大量的軟件开發團隊和算子優化團隊,通過仔細優化底層代碼並提供相應的計算庫,提升深度學習等應用計算效率。由於CUDA有較好的生態,這部分开源社區也有相當大的貢獻。
然而,CUDA框架和GPU硬件架構的緊密耦合同時也帶來了挑战,比如在GPU之間的數據交互通常需要通過全局內存(Global Memory),這可能導致大量的內存訪問,從而影響性能。如果需要減少這類訪存,需要利用Kernel的Fusion等技術。實際上,英偉達在H100裏增加SM-SM的片上傳輸通路來實現SM間數據的復用、減少訪存數量,但是這通常需要程序員手工完成,同樣增加了性能優化的難度。另外,GPU的整個軟件棧最早並不是專爲深度學習設計的,它在提供通用性的同時,也引入了不小的开銷,這在學術界也有不少相關的研究。
因此,這就給AI芯片的新挑战者如Groq,這提供了機會。例如Groq就是挖掘深度學習應用處理過程中的“確定性”來減少硬件开銷、處理延時等。這也是Groq芯片的特色之處。
孫教授告訴筆者,實現這么一款芯片的挑战是多方面的。其中關鍵之一是如何實現軟硬件方面協同設計與優化,極大的挖掘“確定性”實現系統層面的Strong Scaling 。爲了達到這個目標,Groq設計了基於“確定性調度”的數據流架構,硬件上爲了消除“不確定性” 在計算、訪存和互聯架構上都進行了定制,並且把一些硬件上不好處理的問題通過特定的接口暴露給軟件解決。軟件上需要利用硬件的特性,結合上層應用做優化,還需要考慮易用性、兼容性和可擴展性等,這些需求都對配套工具鏈和系統層面提出很多新的挑战。如果完全依賴人工調優的工作是很大的,需要在編譯器等工具層面實現更多的創新,這也是新興的AI芯片公司(包括Tenstorrent、Graphcore、Cerebras等)面臨的共同問題。
HBM是唯一解?純SRAM來挑战
LPU 推理引擎主要攻克 LLM的兩個瓶頸——計算量和內存帶寬。Groq LPU能夠與英偉達叫板,其純SRAM的方案起到了很大的作用。

簡化的LPU架構
不同於英偉達GPU所使用的HBM方案,Groq舍棄了傳統的復雜儲存器層級,將數據全部放置在片上SRAM中,利用SRAM的高帶寬(單芯片80TB/s),可以顯著提升LLM推理中帶寬受限的(Memory Bound)部分,比如Decode Stage計算和KV cache的訪存。SRAM本身是計算芯片必須的存儲單元,GPU 和CPU等利用SRAM來搭建片上的高速緩存,在計算過程中盡可能減少較慢的DRAM訪問。但由於單個芯片的SRAM容量有限,所以涉及到數百個芯片協同處理,這也涉及芯片間的互連設計,以及系統層面的算法部署等。
Groq提到,由於沒有外部內存帶寬瓶頸,LPU推理引擎提供了比圖形處理器更好的數量級性能。
這種純SRAM的架構在最近幾年一直被學術界和工業界所討論,比如華盛頓大學在文章【Chiplet Cloud: Building AI Supercomputers for Serving Large Generative Language Models】【2】中提到,與DDR4和HBM2e相比,SRAM在帶寬和讀取能耗上具有數量級的優勢,從而獲得更好的TCO/Token設計,如下圖所示。市面上,包括Groq以及其他公司如Tenstorrent、Graphcore、Cerebras和國內的平頭哥半導體(含光800)、後摩智能(H30)等,都在嘗試通過增加片上SRAM的容量和片上互連的能力來提升數據交互的效率,從而在AI處理芯片領域尋求與英偉達不同的競爭優勢。
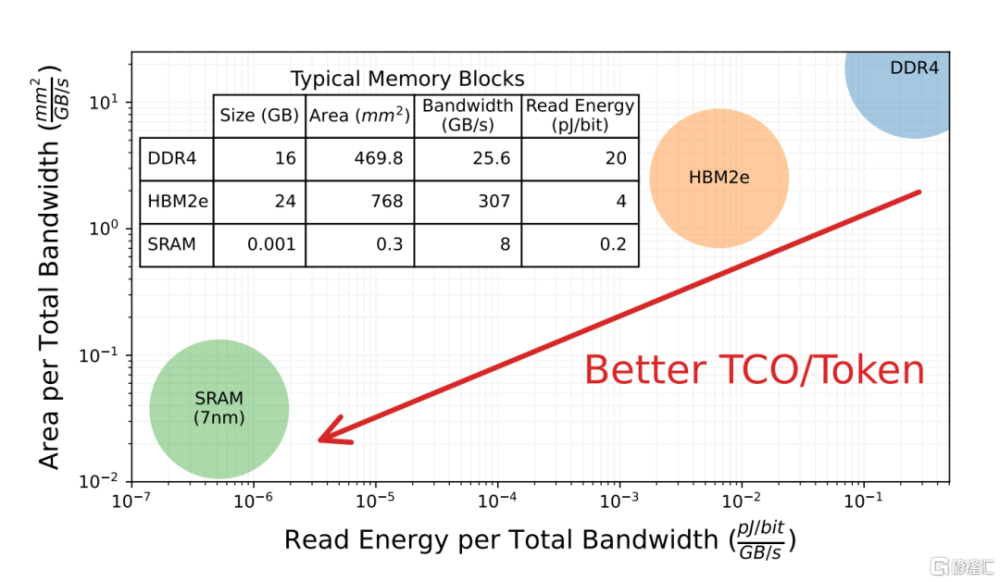
與DDR4和HBM2e相比,SRAM在帶寬和讀取能耗上具有數量級的優勢,從而獲得更好的TCO/Token設計(來源:【2】)
純SRAM架構的優勢在哪裏?孫教授指出主要涵蓋兩方面:第一個方面是SRAM本身有着高帶寬和低延遲優勢,可以顯著提升系統在處理訪存受限算子的能力。另一方面,由於SRAM的讀寫相比DRAM具有確定性,純SRAM的架構給軟件提供了確定性調度的基礎。編譯器可以細粒度地排布計算和訪存操作,最大化系統的性能。對於GPU來說,由於HBM訪問延遲會有波動,Cache層級的存在也提升了訪存延遲的不確定性,增加了編譯器做細粒度優化的難度。
衆所周知,英偉達GPU所使用的HBM方案面臨着成本高、散熱、產能不足的難題。那么,這種純SRAM架構又有哪些挑战呢?
孫教授分析到:“純SRAM架構的挑战也很明顯,主要來自於容量的限制。Groq等芯片基本上都是在CNN時代進行的立項和設計,對於這個階段的模型,單芯片百兆SRAM來作爲存儲是夠用的。但是在大模型時代,由於模型大小通常可以達到上百GB,而且KV-Cache(一種關鍵數據結構)的存儲也非常佔用內存,單芯片SRAM的容量在大模型場景下顯得捉襟見肘。”
他以Groq的方案爲例來說,爲了滿足70B模型的推理需求,它集成了576個獨立的芯片,而集成如此多的芯片,對芯片間、節點間互聯的帶寬和延遲要求也非常的高。576芯片的集群只有100GB的SRAM容量。模型需要通過細粒度的流水线並行(PP)和張量並行(TP)的方式進行切分,來保證每個芯片分到的模型分塊在200MB以內。細粒度切分的代價是芯片間通信的數據量和开銷顯著上升,雖然Groq在互聯方面也進行了定制優化來降低延遲,但是通過簡單估算可以發現,目前芯片間數據傳輸同樣可能成爲性能瓶頸。”
另一方面,由於容量的限制,其留給推理時的激活值的存儲空間十分受限。特別是目前LLM推理需要保存KV-Cache,這是隨着輸入輸出長度线性增長的數據。通常對於70B模型,即使用了特殊技術進行KV-Cache壓縮(GQA),32K的上下文長度需要爲每個請求保留10GB左右的KV-Cache,這意味着在32K場景下同時處理的請求數最大僅爲3。對於Groq來說,由於依賴流水线並行(TP),需要至少流水线級數這么多的請求來保證系統有較高利用率,較低的並發數會顯著降低系統的資源利用率。所以,如果未來長上下文(Long-Context)的應用場景,在100K甚至更長的上下文下,純SRAM架構能支持的並發數會非常受限。換一個角度看,對於邊緣場景,如果採用更激進的MQA、更低的量化比特,可能會使SRAM架構更爲適用。
如果Groq 這類芯片確實能夠找到合適的應用場景,應該會讓算法從業者更積極挖掘模型壓縮、KV-Cache壓縮等算法,來緩解純SRAM架構的容量瓶頸。一些對推理延遲有強需求的算法和應用,如AutoGPT, 各種Agent算法等,整個算法流程需要鏈式處理推理請求的,會更有可能做到實時處理,滿足人與真實世界交互的需求。
因此,在孫教授看來,採用純SRAM還是HBM與未來模型發展和應用的場景非常相關。對於數據中心這類採用較大的batch數、較長的sequence length、追求吞吐的場景,HBM這類大容量存儲應該更加合適。對於機器人、自動駕駛等邊緣側,batch通常爲1,sequence length有限,追求延時的場景,尤其考慮到模型有機會繼續壓縮,純SRAM的場景應該有更大的機會。另外,還可以同時期待一些新的存儲介質的發展,能否將片上存儲容量從百MB突破到GB的規模。
應對“存儲牆”挑战:芯片架構創新勢在必行
實際上,除了前述的純SRAM解決方案外,爲了應對當前馮諾依曼架構面臨的“存儲牆”問題,業界正在探索多種新型架構,包括存算一體和近存計算等。這些探索涵蓋了基於傳統的SRAM、DRAM以及新興的非易失性存儲技術,如RRAM、STTRAM等,都有廣泛的研究正在進行中。在處理大型模型的場景中,也有相關的創新嘗試,例如三星、海力士等企業正積極研發的DRAM近存計算架構,可以很好的在帶寬和容量之間提供權衡,對於訪存密集KV cache和小batch的Decode處理部分也提供了不錯的機會。(對這部分有興趣,可以參考“Unleashing the Potential of PIM: Accelerating Large Batched Inference of Transformer-Based Generative Models”【3】這篇文章關於KV cache的處理,孫教授團隊比較關注的研究方向。)
另外,從更廣義的角度分析,無論採用哪種存儲介質、無論採用存算還是近存架構,其本質目的和Groq出發點是類似的,都是挖掘存儲架構的內部高帶寬來緩解訪存瓶頸。如果同時考慮大容量的需求,都需要將存儲分塊,然後在存儲陣列附近(近存)或陣列內(存內)配備一定的算力單元。當這種分塊的數量達到一定數量,甚至會突破單個芯片的邊界,就需要考慮芯片間的互連等問題。對於這類計算和存儲從集中式走向分布式的架構,孫教授團隊在研究時也習慣稱爲空間型計算(Spatial Computing)架構。簡言之,每個計算或者存儲單元的位置都對它承擔的任務有影響。一方面,在芯片層面,這種分布式計算架構和GPU提供抽象是不同的;另一方面,當規模擴大到多芯片/多卡這個級別,面臨的問題又是類似的。
總之,大模型確實給傳統的芯片架構帶來了極大的挑战,迫使芯片從業者發揮主觀能動性,通過“另闢蹊徑”的方式來尋求突破。值得關注的是,國內也已經有一批架構創新型的芯片企業,陸續推出了存算一體或近存計算的產品,例如、知存科技、後摩智能、靈汐科技等。
考慮到芯片的研發周期通常長達數年,孫教授認爲在嘗試新技術的時候需要對未來的應用(如LLM技術)的發展趨勢有一個合理的預判。分析好應用的發展趨勢,通過軟硬件的設計預留一定的靈活性和通用性,更能夠保證技術長期適用性。
標題:挑战英偉達,需要另闢蹊徑
地址:https://www.iknowplus.com/post/85991.html







