清華大學團隊刷屏的芯片和論文,對AI意味着什么?
編者按
早陣子,國內清華大學研究團隊發布了一篇論文,裏面談及了一款領先的芯片和設計。這個新聞在朋友圈引起了廣泛討論。那么這是個什么芯片?對AI又意味着什么?讓我們在本文解讀一下。
以下爲文章正文:
人工智能是目前半導體芯片行業最重要的市場驅動力之一,同時也是當下最有潛力深刻改變整個人類社會的技術。當前,最主流的人工智能算法加速芯片是GPU,但是GPU加速人工智能有着自己的瓶頸,就是能效比較低。GPU的功耗通常要幾百瓦,這就使得大規模部署人工智能充滿了挑战:一方面大規模數據中心需要確保散熱足夠好,不至於讓GPU過熱而無法工作;另一方面,GPU很高的功耗又爲數據中心帶來了很高的供電成本和需求。
GPU,以及其他絕大多數人工智能加速芯片,都屬於常規的數字邏輯的計算範式。使用數字邏輯計算存在幾個重要的局限性:
首先,信號必須要做數字化,而很多人工智能任務處理的輸入(例如機器視覺任務)實際上並非人工的數字信息而是物理信號。這樣的物理信號數字化就會帶來能量的浪費。
其次,在數字邏輯中,有一個全局的時鐘,而時鐘頻率則決定了整個系統的處理速度。數字邏輯的時鐘頻率往往決定於芯片工藝實現的邏輯門的速度(延遲),而並非由處理任務的復雜程度決定,因此這樣的數字時鐘事實上也限制了整體芯片處理任務能實現的速度。
最後,數字邏輯的設計中,尤其是對於處理人工智能相關的任務,通常都需要配合一個存儲單元(尤其是像GPU需要配合DRAM使用),這樣的數據存取和讀取事實上會消耗相當大的能量。
與傳統的數字邏輯計算範式相比,新模態計算則是使用了非常規的信號處理和計算方法(例如光學處理以及模擬信號處理),從而可以很大程度上避免數字邏輯計算中的幾大局限,並且有望爲人工智能的高能效比計算帶來新的希望。
10月底,來自中國清華大學的研究組在頂級期刊《自然》上發表了使用新模態計算加速人工智能的論文《All-analog photoelectronic chip for high-speed vision tasks》。在該論文中,清華大學的研究團隊提出了使用光學和模擬計算來加速人工智能計算的技術,即all-analog chip combining electronic and light computing (全模擬電子和光子計算芯片,ACCEL),並且實現了相當高的計算性能和能效比(等效算力4600TOP/s,能效比74800TOP/s/W),相當於Nvidia A100 GPU的3000倍以上。

ACCEL技術詳解
ACCEL的結構如下圖所示。
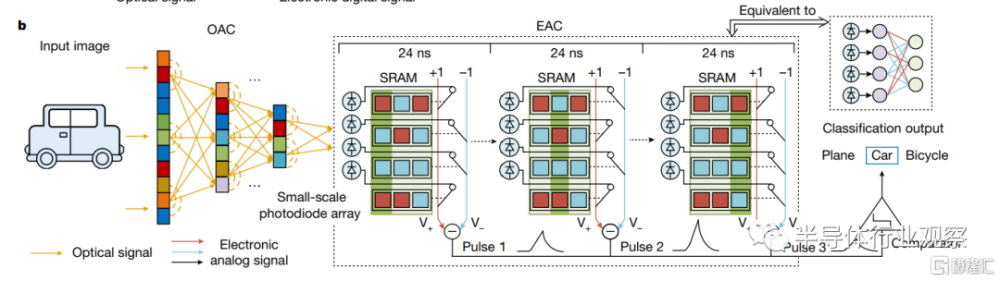
首先,如論文標題所說的,ACCEL針對的是機器視覺任務(vision task),因此輸入是一個圖像。值得注意的是,這裏的圖像並不是一個存儲於二進制格式的圖像文件,而是一個確確實實的圖像物理信號(即光場信號)。我們會看到的是,整個論文中的芯片都是直接處理物理模擬信號,而不會做任何模擬-數字信號轉換,這裏的輸入也因此是一個模擬物理信號。
輸入圖像光場信號首先進入光學處理部分,即optical analog computing,OAC。OAC的主要任務是把圖像信號進行降維處理。例如,在ImageNet數據集上,圖像輸入是224x224,相當於數據維度高達50000以上,因此首先需要進行降維(和傳統的卷積神經網絡的降採樣層是同一原理和目的)。OAC從物理上是利用光學衍射讓圖像中的不同像素之間互相交互,從而等價地實現一個矩陣相乘的過程,從實現上來說,OAC可以根據矩陣的權重而使用二氧化硅蝕刻出相應的圖形來完成,換句話說OAC的實現是無需任何功耗的,僅僅就是把光透射過一層掩模版就完成了計算。在論文中,作者提到通過OAC可以實現高達98%的降維而不影響計算精度——換句話說OAC可以實現50倍的數據壓縮,因此這個無需功耗的OAC實際上在整體系統中起到了相當重要的作用。
光信號經過OAC掩模版之後,照射到ACCEL芯片上的光電二極管陣列上(論文中稱爲電子模擬計算electronic analog computing,EAC),因此光電二極管陣列中的每一個光電二極管都會根據OAC的輸出產生相應的光電流。此外,這些光電二極管陣列中的每一個光電二極管的正極都通過开關連接到差分信號线的正極或者負極上(該連接可以根據存儲在SRAM中的內容來配置),因此每一個光電二極管都會爲差分线的正極或者負極放電。最後差分线的正極和負極經過模擬比較器獲得最終的0或者1的輸出,同時也完成了模擬信號到數字信號的轉換。整個ACCEL芯片使用成熟的180nm工藝實現,可以在約2ns的時間內完成一次計算,而一次計算耗費的能量爲4.4nJ。
如果我們把OAC和EAC的部分結合到一起,事實上ACCEL從數學的角度是實現了一個等效的神經網絡,其中OAC是一個矩陣相乘運算,而EAC則是實現了神經網絡中的非线性激活部分。根據論文中的數據,使用ACCEL可以在分類(MNIST,KMNIST,Fashion-MNIST)等機器視覺任務中實現和傳統數字卷積神經網絡類似的精度,但是使用ACCEL可以在處理速度和處理能效比上實現幾個數量級的提升:這裏的原因其實也很簡單,卷積神經網絡使用傳統數字邏輯計算時,最耗費計算時間和能量的矩陣計算在這裏直接使用光學計算完成了,而光學計算耗費的時間是0(光速),能量也是0;另一方面,ACCEL中決定任務處理速度的事實上是模擬電路部分,比較器的積分和开關時間決定了總體的任務處理時間。
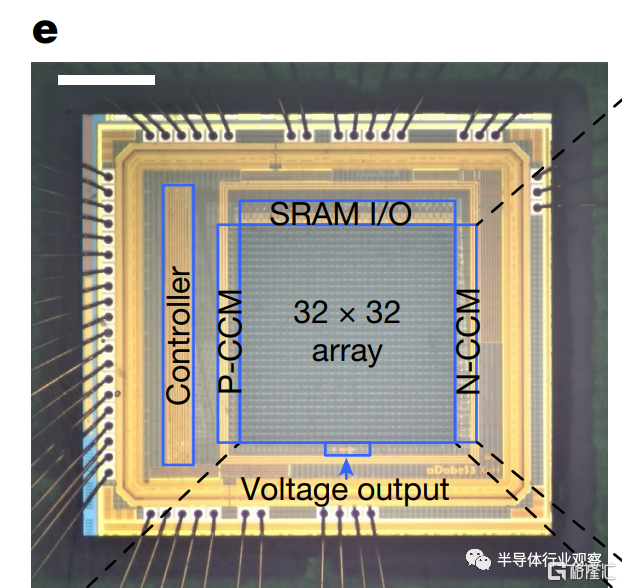
值得注意的是,目前的ACCEL芯片是一個小型的芯片(使用了32x32陣列)並且使用了20多年前的180nm工藝,主要用於概念驗證。如果使用更先進的工藝實現更大的陣列,則首先可以支持更大的神經網絡以支持更復雜的任務,其次可以實現更高的處理速度(模擬電路處理速度即使是使用28nm這樣的成熟工藝也會數倍於180nm)。因此,本次報道的ACCEL的性能數字還遠遠沒有達到該技術可能實現的上限。
對於未來人工智能和芯片的潛在影響
清華大學的ACCEL可謂是非常優秀的科研工作,其實現的高性能也爲未來應用提供了新希望。我們看到,ACCEL可以實現非常高的處理速度和非常好的能效比;同時,該技術的局限性在於(1)由於使用光學計算,因此最適合機器視覺任務,而對於目前最火熱的語言類模型則難以支持;(2)對於算法和算符的支持,主要對於機器視覺任務中經典的卷積神經網絡支持最好,對於Transformer等模型的支持還需要進一步的研究。
基於該研究的優勢(計算速度和低能耗)和局限(對於算法類型的支持),我們認爲,ACCEL以及相關的研究對於未來人工智能最主要的影響可能在於對於一些特定的任務提供極致的性能,而不是取代通用的GPU。這事實上也和目前的領域專用計算(domain-specific computing)來提供更好的性能及能效比的思路一致。具體來說,以下領域有可能成爲ACCEL的應用場景:
首先,是需要超低延遲的應用場景,例如汽車或其他高速行駛的場景。在這樣的場景中,ACCEL搭配超高幀率的攝像頭(例如目前正在興起的DVS攝像頭芯片,峰值幀率可達1000fps以上),ACCEL的超低延遲可以滿足在超高幀率的兩幀之間完成人工智能算法的推理,從而滿足整體系統的需求。
此外,ACCEL還可望在觸發式人工智能系統中得到應用。這裏的觸發式人工智能系統是指人工智能系統有多個模型組成,在大多數時候運行常开(always-on)的部分,而其他更復雜的人工智能模型僅僅在常开的模塊發現有需要的時候才會觸發打开。由於ACCEL的延遲和能效比都非常優秀,因此非常適合在這樣的觸發式人工智能中擔任常开的模組。
未來如果ACCEL以及相關的研究需要進入更廣泛的應用,還需要研究人員進一步努力以支持更復雜的算法和模型結構,但是我們認爲,前景是光明的,讓我們拭目以待。
標題:清華大學團隊刷屏的芯片和論文,對AI意味着什么?
地址:https://www.iknowplus.com/post/50034.html







