趕超GPT-4,中文能力“地表最強”,通義千問2.5來了!國產大模型邁入核心競技場?
AI競賽場上,海外巨頭“廝殺”甚是激烈,國內大模型的進化也上演加速度。
5月9日,在北京舉辦的阿裏雲AI智領者峰會上,通義千問2.5正式發布。
此次,大模型能力實現大升級,性能全面趕超GPT-4 Turbo,成爲“地表最強”的中文大模型。
趕超GPT-4
阿裏雲表示,相較於通義千問2.1版本,通義千問2.5的理解能力、邏輯推理、指令遵循、代碼能力分別提升9%、16%、19%、10%。
對比GPT-4,在中文語境下,通義千問2.5在文本理解、文本生成、知識問答&生活建議、闲聊對話,以及安全風險等多項能力上均全面趕超。
在這輪競爭激烈的AI大模型浪潮裏,這是國產大模型首次取得這樣的成績。

在長文本處理方面,通義千問2.5支持單次最長1000萬字文檔的處理,並且同時能夠處理多達100個文檔。
通義千問還支持對PDF、Word、圖表等多種不同格式的文檔進行處理,滿足了用戶多樣化的需求。

除了通義千問2.5之外,阿裏雲還發布了一組新“成績”。
阿裏雲首席技術官(CTO)周靖人在會上表示,通義大模型已經通過阿裏雲服務企業超過9萬家,通過釘釘服務企業超過220萬。
通義千問API日調用量已破億,通義开源模型的累計下載量突破700萬次。
另外,通義落地應用的進程也在加速,目前已經涉足PC、手機、汽車、航空、天文、礦業、教育、醫療、餐飲、遊戲、文旅等多個領域。
其中,小米旗下的“小愛同學”也與阿裏雲通義大模型達成合作,並將在小米汽車、手機等多類設備落地。

另外,通義靈碼宣布推出企業版。通義靈碼是國內用戶規模第一的智能編碼助手,基於SOTA水准的通義千問代碼模型CodeQwen1.5研發,插件下載量已超350萬。
通義千問最新开源的1100億參數模型——Qwen1.5-110B也收獲了最佳成績。
在MMLU、TheoremQA、GPQA等基准測評中,該模型超越了Meta的Llama-3-70B,成爲开源領域最強大模型。
峰會上,阿裏雲強調要成爲“AI時代最开放的雲”,通過开放的算力平台、开源的自研模型、優質的模型服務,幫助客戶抓住大模型時代的機遇。
國產大模型邁入核心競技場?
去年4月,通義千問正式亮相。
當時,阿裏雲就曾表示,要讓中國整體的AI能力有全方位的提升。
“未來所有軟件都值得接入大模型升級改造,我們將开放通義千問的能力,爲每一家企業打造自己的專屬GPT(一種預訓練的語言模型)。”
恰逢一周年之際,通義千問大模型的進階,也意味着國產大模型再上一層樓。
自2022年ChatGPT發布以來,AI大模型在全球範圍內掀起了有史以來最大規模的人工智能浪潮。
可以說,過去的一年,這個圈子是“要多卷有多卷”。
當下,OpenAI、谷歌、微軟等猛“砸錢”不斷革新着自家產品。除了海外巨頭“你追我趕”之外,國內大模型也是“渾身使勁”緊追其後。
據SuperCLUE團隊研究數據,國內大模型的進展大致分爲三個階段,即准備期、成長期、爆發期。
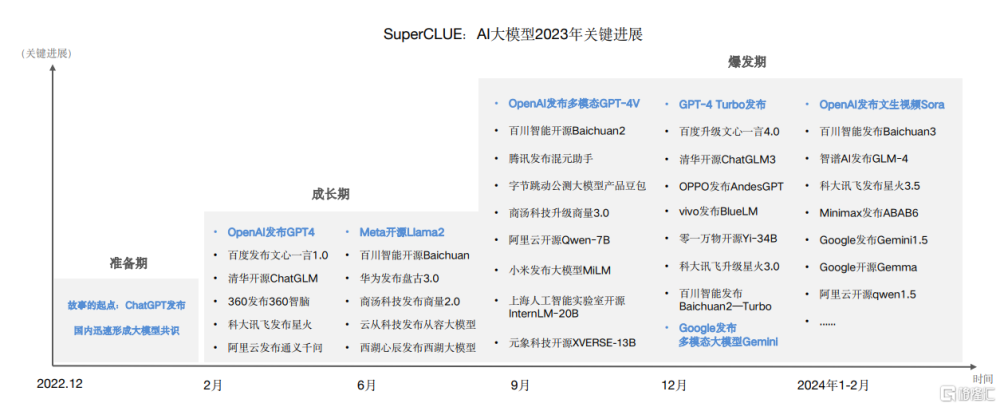
目前,除了阿裏通義千問、百度文心一言、華爲盤古等科技大廠“馬不停蹄”加緊研發國產大模型外,還有復旦MOSS、中科院紫東太初、初創黑馬-月之暗面的Kimi等陸續脫穎而出。
從行業發展來看,銀河證券表示,未來通用AI大模型領域可能會更加集中在頭部廠商,更多廠商需要向行業專業化轉型,垂直類AI大模型、端側AI大模型將是未來主战場,市場空間廣闊。建議關注上遊算力基礎設施相關機會,國產算力產業鏈及生態夥伴相關機會,以及下遊應用端領域。
華泰證券此前也表示,國產優質大模型能力持續進階,有望推動應用快速發展,投資關注三條邏輯线。
1)視頻/語料素材庫邏輯,大模型需優質訓練素材投喂,素材價值有望放大;
2)應用接入Kimi及其他優質大模型,其長文本理解及處理能力,有望充分賦能在线閱讀、教育、營銷、電商等領域應用場景;
3)與其他優質國產大模型合作的公司,有望通過優質大模型提升主業。
標題:趕超GPT-4,中文能力“地表最強”,通義千問2.5來了!國產大模型邁入核心競技場?
地址:https://www.iknowplus.com/post/106111.html







