GPU,巨變前夜
3D圖像一直是芯片發展的推動力之一,從上世紀九十年代直到今天,以遊戲、電影等爲代表的高性能圖像渲染應用的蓬勃發展直接讓GPU芯片成爲了一個新的芯片品類,並且快速發展至今。從這個角度,我們認爲高性能3D圖像渲染以及3D圖像學的發展一直在驅動着GPU芯片品類的發展。
在3D圖像學中,對於真實場景和物體的高精度建模/渲染一直是整個學界夢寐以求的目標之一。在過去幾十年中,3D場景和物體建模的主流方式是基於多邊形(ploygon mesh)的建模,即把一個3D建模的物體表面近似爲由大量多邊形組成,而多邊形數量越多,則3D建模和真實物體/場景越接近。在具體3D模型創建方面,則是由3D建模人員創建模型。在這樣的情況下,多邊形數量一方面限制了渲染的性能(即主流設備難以渲染多邊形足以表現全部真實場景細節的模型),另一方面從建模方面,3D建模人員也難以完成含有真實物體或者場景所有細節的3D模型。因此,我們目前看到的主流3D模型都和現實的真實場景有顯著區別。
最近幾年,隨着人工智能的發展,以輻射場爲代表的新的3D圖像學正在挑战多邊形建模的傳統3D範式,而今年下半年3D圖像學界更是由於幾篇重磅研究的發表而進入了一個快速發展階段,真實場景建模正在以前所未有的速度接近我們。
在這幾個裏程碑式的研究中,第一個是由法國INRIA和德國馬克思普朗克研究所完成的3D Gaussian Splatting(3D GS)。3D Gaussian Splatting是輻射場建模的一種,它和傳統的多邊形建模的區別在於,第一其3D場景的建模單位不再是多邊形,而是形狀和顏色可變的Gaussian Splatting (GS),通過大量GS的疊加,可以高精度還原3D場景中的細節。第二,其建模過程不再是由3D建模人員完成,而是用了人工智能的方式,具體來說建模過程是對需要具體的場景拍攝不同視角的圖片,然後這些圖片通過人工智能的優化方法可以完成整個場景的3D GS建模,這樣就避免了建模過程對於最終場景精度的限制。最後,3D GS的渲染速度可以很快,在現有的桌面GPU上,可以實現100 fps的渲染。當然,由於目前的GPU還沒有針對3D GS做優化,這個速度和效率肯定還有很大的提升空間,但是這樣的渲染速度和精度已經足以讓3D GS進入實用。

使用3D GS實現的超高精度3D場景建模和渲染
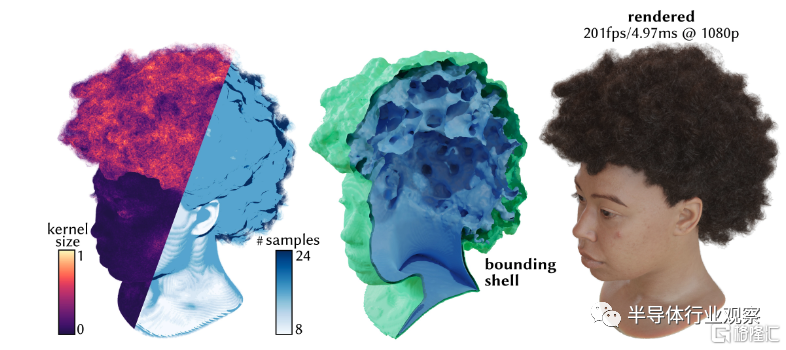
第二個重要研究是由Nvidia發表的Adaptive Shells for Efficient Neural Radiance Field Rendering。神經輻射場(Neural Radiance Field,NeRF)和3D GS類似,都是可以通過場景的多角度圖片來完成場景的超高精度建模,並且其建模方式也是通過人工智能模型訓練的方法來完成。NeRF和3D GS的主要不同在於,其建模方法是通過神經網絡來完成,因此其渲染過程就是等價於神經網絡的推理過程。NeRF出現已經有了數年,但是直到今年Nvidia的研究發表,才真正實現了GPU上高幀率(100-200fps)的高質量NeRF渲染,因此今年可望是NeRF渲染真正進入實用的开始。
人工智能圖像學對於GPU的需求
我們認爲,人工智能圖像學對於GPU提出了新的需求。
首先,在基本的NeRF或者3D GS的渲染中,傳統的GPU中的多邊形渲染流水线已經無法高效支持,因爲NeRF和3D GS的渲染需要一些重要的新計算。對於NeRF來說,其場景建模信息都包含在訓練過的神經網絡中,神經網絡的輸入就是用戶當前的視角,輸出則是場景在視角下的2D圖像。因此,其渲染過程其實就是根據用戶的視角來完成神經網絡的推理計算。而在3D GS中,具體的渲染過程則是把整個場景分成多個塊(tile),每個塊中根據當前視角首先排序選出對於視覺影響最大的N個GS,之後再僅僅針對這些GS做渲染,從而可以實現高效率。我們可以看到這些都和當前的多邊形渲染流水线有較大不同,爲了能高效支持這些3D圖像學的新範式,GPU需要能高效支持這些新計算。
另外,在新的3D圖像學是由人工智能驅動的這一潮流下,我們勢必會看到3D圖像渲染和人工智能的進一步結合,例如在NeRF和3D GS的場景建模中加入基於神經網絡計算的動畫或者編輯(光影變化等),這些又進一步說明目前的GPU上的多邊形渲染流水线對着這類新圖像渲染範式已經無法高效支持。
GPU新架構呼之欲出
我們認爲,這些新的超高精度3D圖像學會推動新的GPU架構發展。
從桌面和服務器GPU芯片角度,我們認爲GPGPU架構會得到進一步的推廣。Nvidia主導的GPGPU在人工智能浪潮的前幾年(2012-2017)是Nvidia能夠佔據人工智能霸主地位的核心,因爲GPGPU的开放接口可以讓GPU去做人工智能計算。在這之後,隨着人工智能應用進入主流地位,Nvidia开始給人工智能做專用優化,引入了包括Tensor Core等重要新架構,換句話說人工智能在Nvidia的GPU上已經不再主要依賴其GPGPU思路,而是更多依賴Nvidia的人工智能架構設計。然而,隨着新的3D圖形學的發展,GPGPU又會重新進入聚光燈下。
從芯片架構角度來說,從宏觀上這意味着GPGPU的進一步進化,以及和人工智能的融合。之前,GPGPU允許用戶去調用3D圖形計算的單元去做其他非圖形的計算;而隨着新的3D圖形學的發展,需要GPGPU能進一步开放圖形渲染單元,讓圖形渲染單元更加靈活,從而能支持新的3D建模範式的高效渲染。我們認爲,芯片架構層面,對於這樣新3D圖形學範式的支持,有三方面的需求。
第一個方面是打通渲染流水线和人工智能引擎由於神經網絡的計算在新的3D圖形學中起了極其重要的角色,如何把圖形渲染單元和GPU中的人工智能引擎打通,將是支持這類新3D圖形學渲染的核心需求。例如,在芯片架構設計中,需要能夠讓圖形渲染單元和人工智能引擎之間實現有效通信以及互相高效調用,從而能充分支持這樣的渲染需求——像NeRF這樣的建模方法中,每一幀計算都需要去運行一次神經網絡推理,在高分辨率的時候神經網絡會非常復雜,而高幀率則需要神經網絡延遲有很高的需求,在這種情況下需要圖像渲染和人工智能引擎充分打通。
第二個方面是對於這些新的範式,如何實現硬件優化。對於基於多邊形傳統3D圖形學的渲染加速,GPU已經有了數十年的積累,因此從硬件上幾乎已經把優化做到了極致,然而對於NeRF或者3D GS這樣的新範式,硬件優化目前仍然不存在。第一步,我們可以把目前已有的針對多邊形渲染的優化應用到這類新3D圖形範式上,例如分塊(tile)渲染以實現並行處理,以及流水线計算以降低延遲,等等。更進一步,未來會出現針對這些新3D圖形學範式的專門優化,從而可以將渲染效率進一步提高。
第三個方面是如何提供靈活的用戶接口。3D新圖形學方興未艾,在可預計的未來仍然會高速發展,因此如何能給用戶提供接口,從而可以讓用戶靈活利用和配置GPU上的計算單元,從而用戶可以根據自己獨特的設計來配置GPU上的渲染流水线以實現高效率。這樣的可配置性對於培養新3D圖形學的生態將會是至關重要,如果想要重復Nvidia在人工智能浪潮中的成功,那么就需要在新3D圖形學算法尚未最終塵埃落定的時候就提供足夠支持以培養用戶生態;如果想要等到算法技術已經足夠成熟後再开始提供支持,那么生態角度就會站在非常不利的位置。
比較桌面和服務器GPU的兩大巨頭Nvidia和AMD在這方面的狀態,我們認爲Nvidia由於其在人工智能和GPGPU領域的前期投入,目前毫無疑問站在非常領先的位置——例如,NeRF和3D GS絕大多數的渲染代碼和benchmark都是跑在Nvidia的GPU上,這也是Nvidia生態強大的一個例子。當然,也並不是說目前Nvidia都已經把一切做到盡善盡美;3D GS中,研究人員就提到了CUDA的GPGPU計算庫雖然能實現高效計算,但是在做渲染的時候存在一定的兼容性問題。這也對應於我們上面提到的GPGPU需要更進一步,能和人工智能引擎打通並且提供靈活的用戶接口。
對於AMD來說,在過去一直處於追趕者的地位,目前來說,由於其軟件生態的相對不完整,預計在新3D圖形學逐漸變成主流的前幾年,AMD仍然將處於追趕的地位。但是,如果AMD不想錯過這一波新的3D圖形學的機會的話,一方面需要在軟件生態上做更快速的追趕,另一方面則需要在硬件架構上做相比於Nvidia更加果斷的優化來支持這類新的3D圖形學。
除了桌面/服務器GPU之外,事實上移動端GPU對於這類新3D圖形學也很重要,因爲未來ARVR這類使用移動GPU的應用也預計是應用這樣的新3D圖形學的最關鍵的場景。從移動端GPU來說,最關鍵是如何實現高效率支持,確保在電池和散熱允許的情況下實現最佳質量和幀率。從芯片架構角度,一方面,我們預計也會看到GPU和人工智能引擎在移動SoC上的更高效通信以滿足圖形學上的需求——這將是一個很有趣的架構設計,因爲在不少SoC中GPU和人工智能引擎都是完全分離的IP,有些SoC上的GPU和人工智能引擎甚至可能會由不同的公司設計,因此如何確保兩者之間能互相通信將是重要的課題,甚至可能會有專用的通用接口協議出現。另一方面,移動GPU上對於效率對靈活度的取舍一般都會更偏向於效率,因此在如何在算法上提供高效支持和優化將會是移動GPU優化的重點。
標題:GPU,巨變前夜
地址:https://www.iknowplus.com/post/58699.html