900億美元超級獨角獸,陷入生存煩惱

近期OpenAI動作頻頻,而且個個驚雷貫耳,接連爆出要自研芯片、要與蘋果前首席設計師一同打造AI硬件設備。
同時ChatGPT的更新接踵而至:接入Windows、重新聯網,實現多模態交互,甚至做到了既能看圖、又能聽聲音、還能說話...
也就是說,OpenAI的進化速度,越來越快了。
模型越牛,估值越高。在過去一年時間,OpenAI的估值也從260億美元翻到了最高900億美元,在還沒上市的超級獨角獸裏僅次於字節跳動和SpaceX,據稱OpenAI今年收入預計將達到13億美元,市銷率接近70倍!公司正在和投資者討論用這個估值出售股份。
然而,這個全球關注的超級明星,現在卻有不小的煩惱。
說白了,就是雖然作爲一個超級估值獨角獸,但本身也是一個超級燒錢吞金獸,在13億美元的營收相對龐大的开支簡直就是杯水車薪,它如今不僅加緊要考慮未來商業化變現的路徑問題,還要應對來自後來者越來越步步逼近的圍堵競爭。
在波譎雲詭的商業世界裏,產品化節奏和資金投入一出現問題,這場以底層模型爲支撐的平台遊戲都將舉步維艱。
隨着Meta、Google等玩家強勢覺醒,Anthropic+Amazon的組合加入攪局,被強敵林立環繞OpenAI下一步該怎么走?
01 代理人之战
OpenAI在模型層並不寂寞,即使站在塔尖,一統天下還言之尚早。
尤其在和微軟的聯盟讓科技大廠們意識到成熟的大模型技術將給雲計算帶來新的業務需求,一番新的混战隨着谷歌、亞馬遜的加速布局撕开了口子。
近期,Anthropic接受了亞馬遜40億美元的投資,兩家公司將在基礎模型商用方面進行更深入的合作。具體而言,Anthropic將使用AWS的雲服務,而AWS將把Anthropic作爲底層模型之一,接入剛剛推出的托管服務,用於構建生成式AI應用。
作爲开發者,可以從多個基礎模型中選擇,用自己的數據來訓練,然後將它們部署到自己的應用程序裏,就不再需要搭建服務器這么繁瑣。除了亞馬遜自己的大模型Titan,Bedrock服務裏已經加入了多個基礎模型。
亞馬遜不會找OpenAI,原因和谷歌是一樣的,微軟Azure-OpenAI的綁定讓三家在公有雲市場上又多了一番變數。明着看是對下遊的押注,其實都是在給自己業務拉活兒。
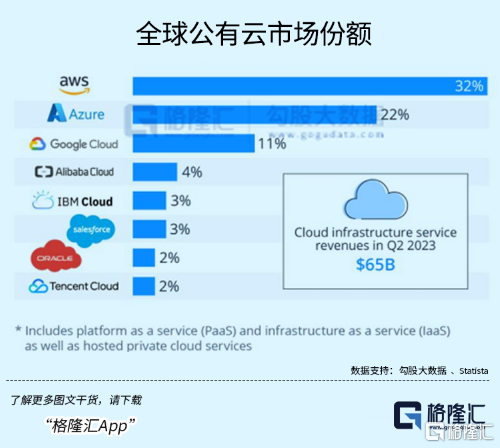
亞馬遜、微軟和谷歌三家對公有雲市場形成了寡頭壟斷的局面。根據 Statista 的數據,今年二季度,AWS 、Azure 、Google Cloud份額分別爲32%、22%、11%,三家合計穩定在65%的份額。
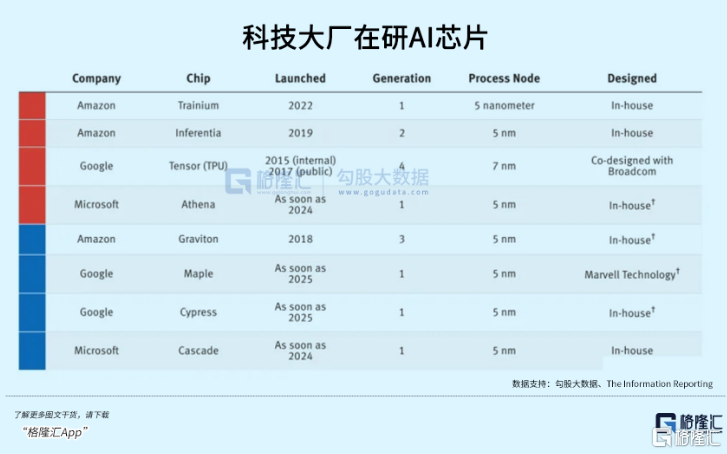
找大模型行家合作還不夠,爲了更好地給模型开發者提供服務,同時少受英偉達牽制,科技大廠還必須自己做芯片。
與OpenAI使用英偉達芯片訓練不同,Anthropic將採用亞馬遜自研的Trainium和Inferentia芯片來訓練。
大模型競賽從底層要求看,首先是算力競賽。
大廠自研芯片的努力逐漸在實現,既爲了降低成本,也想增厚自己出租服務器的利潤,多收獲像ChatGPT這樣的开發項目。
亞馬遜很早就开始把自研芯片往服務器堆;谷歌有TPU,並且已經給另一家圖像模型的創業明星——Midjourney使用;據外媒報道,微軟也可能於下個月發布自研的AI芯片。
其次,巨頭們對大模型的想法,其實都在財報上說得明明白白。
他們的半年報裏已經反映了客戶對於生成式AI需求激增的趨勢,ChatGPT掀起的大模型熱已經消化得差不多了,下半年科技巨頭开始圍繞自家應用層的生產力工具,完善增值服務。
比如微軟通過與OpenAI合作,率先將AI能力賦能到自己的應用全家桶。
Copilot是微軟將AI融入產品矩陣的平台,被定義爲“日常AI伴侶”,將作爲一個應用程序在微軟操作系統中使用,微軟從上個月起已經將其加入到Win 11的更新中。

面向B端的365 Copilot企業版也將於11月1日正式上线,正如我們上半年見到的,各類辦公軟件屆時將接入AI助手爲我們進行一些自動化操作來提高工作效率。
收費上幾乎完全對標了谷歌,這筆增值訂閱費用是除企業用戶已經支付的生產力套件訂閱費用外的額外費用。在今年8月谷歌Workspace推出的Duet AI同樣也向企業客戶收取30美元/月的費用。
Workspace收入屬於Alphabet的 Google Cloud類別,與 Google 的雲基礎設施一起今年二季度產生了80億美元的營收。在同一時期,微軟的Office產品和雲服務爲其帶來了135億美元的收入。
作爲Anthropic較早的投資者,谷歌雲搭建的AI平台讓用戶能夠部署和擴展機器學習模型。今年4-7月短短三個月的時間,谷歌雲的生成式AI項目數量增長了150多倍。
值得注意的是,和亞馬遜一樣,谷歌也選擇了多模型路线來擴充B端客戶的不同需求,包括引入Meta的Llama 2和Anthropic的 Claude 2來擴充。同樣的,Llama 2也將通過微軟雲服務進行分發。
兜裏不缺錢的大廠擁抱多模型並不稀奇,因爲暫時很難篤定哪一類模型將會有更好的應用前景,區別是他們並非站在模型創業者的立場思考,而是以战略合作者的身份想去擴大自己的雲服務生態,整合中間模型層給自己的產品賦能。
隨着訓練成本和調試模型的門檻進一步降低,模型—工具—應用各個層面應該會不約而同地湧進去一大批創業者,其中還包括大廠們現有的客戶,與其研發大模型去开發新的應用,還不如實實在在地收割這批新的需求來得經濟實惠。
另一方面,這有點像幾年前國內兩家互聯網大廠在各個領域掀起的代理人大战,利用新技術在搜索引擎以及生產力工具不同領域向彼此發起衝擊。
正如微軟總裁納德拉所說:“我們想讓谷歌跳舞。”有了OpenAI 的微軟,市值從2022年的 1.79 萬億漲至如今的2.5萬億,股價一度創下歷史新高。
02 Open AI的選擇
ChatGPT剛出來的時候,大家都驚覺這是科技界新的iPhone時刻,將目光聚焦在背後的OpenAI。
一個非盈利性,副线任務是與谷歌抗衡的人工智能研究機構,开發出了一款兼具實用性的AI聊天機器人,標志着一只腳邁出象牙塔,正式踏入了商業世界。
諸如AI工具解放生產力,將人類從重復性勞動解放,再到賦能千行萬業、第四次工業革命等等宏大的敘事,配合ChatGPT網頁井噴的流量,OpenAI的估值先坐上火箭躥升。
這時的Open AI已經形成流量入口,加上api模型工廠組成的商業模式,而谷歌還在驚愕中酝釀着反擊。
也因爲Killer Apps還不多,在ChatGPT向世人嶄露頭角的時候,大家都在猜想OpenAI未來是否將統治整個模型層,參考的是操作系統,搜索引擎這種幾乎壟斷的市場。
但其實連Open AI自己都不這么想。
在他們的CTO米拉·穆拉蒂看來,平台遊戲能夠玩下去的要求,就是讓盡可能多的人使用他們的模型,無論是to B還是to C,但人們並不總是需要使用最強大的型號來滿足自己的需求。
作爲勁敵的Anthropic由原來OpenAI的研究主管Dario Amodei等人出來自立門庭,他們的底層分歧只是對AI商用化和安全性存在不同見解,但同時有一點是同一批來自象牙塔裏的人共同篤信的,那就是規模法則(Scaling Law),在未來很長一段時間還會繼續發揮着魔力。
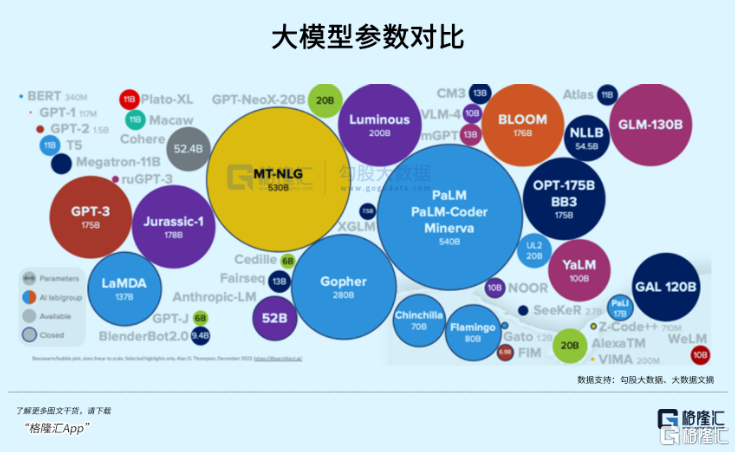
在Transformer架構成功融入模型訓練中後,數據規模超线性地增長驅動了模型性能的湧現。這就是說,模型參數規模越大,進步得越明顯,這是支撐GPT3.5、GPT4、GPT5甚至以後6789的信仰。
然而,开發頂級LLM模型的難度不小,代價不菲。GPT不斷迭代會讓模仿者望塵莫及,當訓練一個更高層級的GPT模型花費成倍級增長時,資本需求自行創造了一定的准入壁壘,在這一層面上沒有多少公司能夠參與競爭,模型迭代速度決定了Open AI和其他勢力的追趕差距,而規模法則助力了這一點。
正如台積電每一代制程升級的成本代代迭升,技術壁壘和花費跟上一代都拉开了巨大差距,但實際上大多數電子產品根本用不上最頂尖的芯片,也因爲廣泛的需求,落後好幾代的制程芯片能以更低的成本使用。
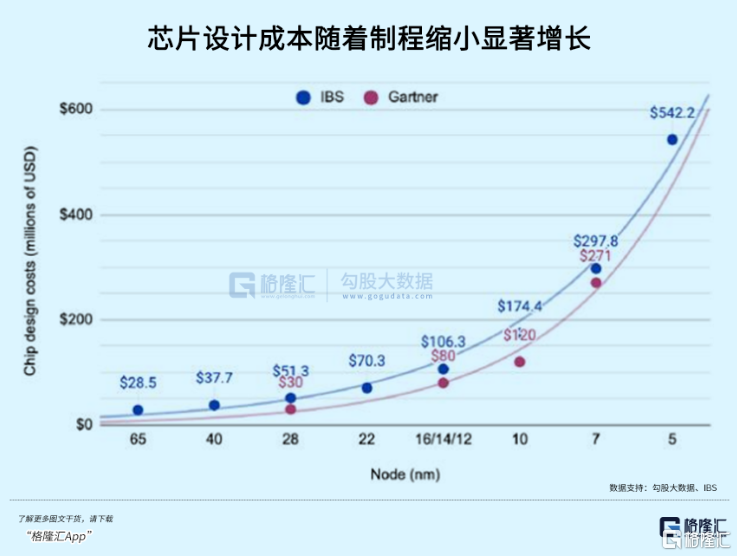
類似的,大模型領域將來可能也會出現這樣一種格局,Open AI或者Google作爲最頂尖的大模型是極度稀缺的,在某些功能上遙遙領先,而總是落後一代的模型,可能要跟實際使用需求融合得更貼近。
最終兩三個最通用的模型可能會站在塔尖,孕育出無數個定制化小模型和應用,這也是OpenAI不愿意錯過的商業機會。
幾天前,公司剛升級Fine-tuning用戶界面,不用寫代碼,上傳訓練數據就可以微調大模型, 通過額外的訓練,可以讓已經訓練過的大模型更好完成特定的任務,比如用你自己的風格寫文章的大模型。這就是要一步步把中遊工具層喫掉的意思。
成爲平台玩家之後,OpenAI同樣不可避免地要應對商業競爭和自身盈利的要求,經營大模型的成本花費不菲也曾令OpenAI變現的壓力驟增。
數月以前,Analytics India Magazine的一份報告中稱,OpenAI僅運行其人工智能服務ChatGPT每天就要花費約70萬美元,絕大部分花費主要來自高昂的GPU以及人才成本。
GPT3.5爆火後,OpenAI一步步开始構建商業化流程。先是推出ChatGPT Plus收費版,再有ChatGPT 商業版,爲了增加營收,OpenAI還多次調整了GPT-4的訪問限制。
同期meta和Google相繼發力給OpenAI帶來不小的壓力。其中針對了Google即將發布的Gemini,察覺到威脅的Open AI就已經搶先爲GPT4增加圖像能力。在接下來的11月6日,OpenAI开發者大會上還將公布“偉大的新工具”,外界紛紛猜測那會是GPT-5。

來源:ChatGPT APP
根據The Information爆料,OpenAI在2022年虧損達到5.4億美元,但今年營收就能達到13億美元。才短短10個月的時間,多套組合拳的配合讓OpenAI完成了由虧轉盈,10億美元,原是CEO奧特曼年初對2024年的目標。
截止7月份,ChatGPT Plus付費用戶達到了200萬;在B端市場,企業版ChatGPT已經被超過80%的財富500強公司團隊採用。
但處在金字塔尖的模型迭代所需要的算力估計每年都會上升一個數量級,隨着應用場景變得更廣,這會讓不同的專有模型數量倍增,進而大大提升模型部署所需要的算力。
根據機構分析,如果ChatGPT的訪問量達到谷歌搜索十分之一的水平,那么每年OpenAI的GPU开銷將達到160億美元,這樣的开銷未來可能是阻止OpenAI進一步規模化的重要瓶頸。
OpenAI自研芯片和特斯拉研制Dojo實際上很相似,針對性非常高,降本空間也很大。憑借公司對模型的積累,能夠根據模型的需求去明確芯片的設計指標,而且對於模型版本有着明確規劃,不至於出現芯片量產之後模型已經領先一代的局面。
正因在高性能計算芯片領域,算法和芯片架構協同才是主要的性能提升動力,OpenAI在這方面處於一個比較有利的地位,憑借對算法的深刻理解,公司有望充分利用Huang’s Law做出芯片。
OpenAI還有一項很重要的動作,可能來自應用端的延伸。ChatGPT是公司第一個Killer App,但聊天機器人的應用場景比較局限於文字交互。多模態的降臨再度豐富了應用落地的想象力,不過被meta搶先實現了。
Meta上月末公开發布的這款價值299美刀的AI智能眼鏡搭載了AI助手Meta AI,內置攝像頭,在功能上實現了多模態交互,能玩的事情就比較多了,比如,旅行時講解各種地標建築,翻譯多種語言菜單,指導維修水管,還支持第一視角的在线實時直播。

與蘋果前首席設計師喬納森一起研發的AI硬件,很可能就是一款支持GPT4甚至5的智能眼鏡,但對終端芯片的要求更高了,這次再次看到了OpenAI可能借由硬件布局從定義模型層到產品應用層的潛在路徑。
03 尾聲
總的來說,多模型的趨勢對於Open AI也許是壓力,也許是機會,技術迭代遠遠未至極限,如何突圍並引領市場規模增長將會是它面臨的主要挑战。
在ChatGPT誕生的大半年裏,也不乏像數據泄露安全,侵犯版權這樣負面事件影響人們對AI工具的信心,對這些彎彎繞繞,對人工智能的未來,OpenAI沒有明確的計劃來應對。
當初Sam Altman一批人集結起來的第一個問題就是“我們要做什么”。
如果大模型也有着類似自動駕駛等級的劃分,那我們現在或許還處在L1到L2的階段,而當初這批熱血科學家個個都想做出AGI,但究竟會不會有L5這個層級,沒人敢打包票。
OpenAI和它的競爭對手們都身處在同一片迷宮裏。
用Altman的話說,他們當前的狀態,就是每次走到拐角的地方,就拿手電筒照一照,最終到達終點。

標題:900億美元超級獨角獸,陷入生存煩惱
地址:https://www.iknowplus.com/post/42322.html







