中金:大模型興起之後,多模態湧現之前
近年來,以GPT爲代表的大模型在語言領域取得了重大突破,人類探索AGI的路徑初見曙光。而在大模型興起之後,產業也試圖在圖像、視頻、音頻等更多模態領域復現“Scaling Law”的成功,繼續實現大模型的“智能湧現”。本文中中金研究從技術脈絡、產業趨勢、應用展望等多個角度,遍歷海外和國內的一二級進展,對多模態這一方向進行全面的闡釋分析,中金研究看好在全球AI浪潮延續,期待攻克多模態這一AI產業發展的下個高地。
摘要
多模態是邁向通用人工智能的“必經之路”。多模態的本質要利用視覺、聽覺、觸覺、味覺等語言之外更加豐富的感知通道,去模擬人類理解與表達信息的能力。理想中的多模態大模型具備跨模態的泛化理解和生成能力,其更符合人類感知世界的方式,中金研究認爲其或能進一步打开AI能力的上限。產業界也在積極探索多模態大模型可行的技術路徑,在多模態領域“復刻”大語言模型的成功。但目前多模態大模型的技術棧也尚未收斂,多模態學習和跨模態對齊仍爲技術難點,未來產業發展仍有無限可能。
產業探索步步爲營,視覺等模態領域進展不斷。圖像方面,技術路徑已經逐步成熟,擴散模型成爲圖像生成領域的主流架構,而後產業界也开始將Transformer架構引入,產生了ViT、DiT等擴展性更好的生成模型,過去數年產業界也已誕生多款文生圖流行應用;視頻方面,文生視頻基於文生圖像的技術路线,而今年年初Sora的出現也在視頻領域延續了DiT架構與“Scaling Law”的成功;音頻方面,Transformer加持下的語音合成技術發展也更趨成熟;3D模型方面,初期探索下技術方向已逐漸清晰,中金研究認爲3D生成也可能成爲未來視覺多模態領域取得突破性進展的下一場景。
多模態AI進展帶來更多應用場景的全新可能。自動駕駛領域,多模態模型具備零樣本學習(zero-shot)等泛化能力,中金研究認爲其或能加速多模態模型和世界模型在學術界的前沿探索;AI Agent領域,中金研究認爲多模態進展能夠爲AI Agent帶來更爲豐富的信息感知來源與任務處理範式,也是其未來大規模商業化落地的前提條件;具身智能領域,中金研究認爲多模態AI迭代有望進一步提升機器人的感知決策能力,結合伺服驅動和運動控制技術的提升,加速人形機器人的產業化落地。
中金研究持續看好全球AI產業浪潮,並判斷多模態可能是未來數年大模型產業技術突破和產業催化較爲集中的領域,建議重點關注相關產業趨勢進展。
風險
技術進展不及預期;應用落地不及預期;行業競爭加劇。
正文
多模態:邁向通用人工智能的“必經之路”
如何理解多模態大模型的意義和價值?
多模態的本質是利用更加豐富的感知通道,去模擬人類理解與表達信息的能力。多模態是指通過結合多種感知通道,例如視覺、聽覺、觸覺、味覺等,來對信息進行理解和處理。人類的智能即是用多模態的方式來進行信息和交互處理的,因此在人工智能領域,產業也在探索一種能夠處理多種類型數據(包括文本、圖像、音頻和視頻)的多模態人工智能模型,進而更好地去模擬人類的智能,實現AGI通用人工智能。
多模態打开AI模型能力的“上限”,是由LLM語言大模型邁向AGI的“必經之路”。近一年多以來,以GPT爲代表的LLM自然語言大模型在自然語言領域取得了較大成果,人工智能在語言文字領域的通用泛化能力取得突破,同時出現一定的智能“湧現”的跡象。但在現實世界中,人類智能處理的更多的信息量是還以視覺、聽覺、觸覺等其他模態存在的,中金研究認爲在未來長期通往AGI的道路中,能夠支持對於多種模態通用泛化的輸入輸出是未來AGI需要具備的必要能力。
圖表:多模態是大模型通往AGI發展的“必經之路”
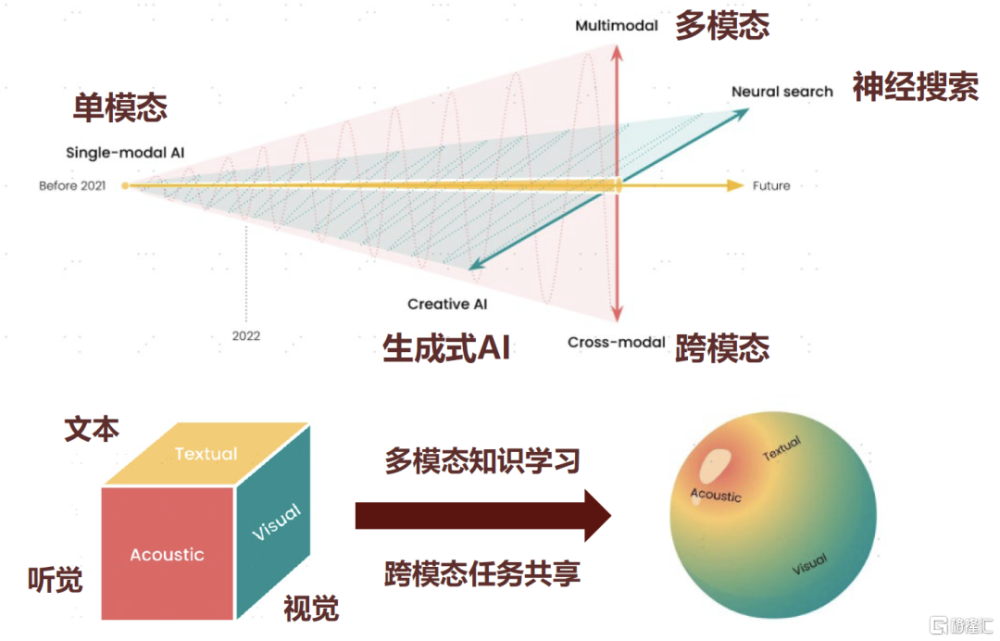
資料來源:Jina AI,中金公司研究部
產學研界旨在多模態領域“復刻”大模型在語言的成功。在過去數年中,以Transformer作爲架構核心的LLM已經在文字模態領域取得了顯著成果,“Scaling Law”持續得到驗證,大模型在語言領域呈現出了初步“智能湧現”的特徵;因此產業也开始愈發關注如何基於在語言單模態領域LLM的成功經驗,將Transformer引入至圖像、視頻等更多模態的任務場景中,充分發揮Transformer大模型的可擴展性,使“Scaling Law”能夠在更多的模態領域得以發揮,最終在多模態領域復現出LLM大模型的“智能湧現”。
理想中的多模態大模型應呈現哪些形態與特徵?中金研究認爲其首先是要多模態且具備跨模態的泛化能力,即在訓練端模型是基於文字、圖像、視頻、音頻等多種模態訓練,具備對於多種不同模態的感知和推理能力,即能夠實現“Any-to-Any”的多模態、跨模態的輸入和輸出;並且需要具有LLM大模型“智能湧現”的特徵,即能夠充分發揮Transformer大模型的可擴展性,在達到一定的參數量規模後,能夠“湧現”出一定的泛化多模態理解及生成能力,具備一定的Zero/Few Shot推理、上下文學習、CoT思想鏈等更高階的模型智能表現特徵。而如何去構建、訓練符合以上特徵目標的MLLM多模態大模型在近年來也已成爲了人工智能產學研界的一大熱點。
圖表:多模態大模型應當能夠實現“Any-to-Any”的多模態、跨模態生成
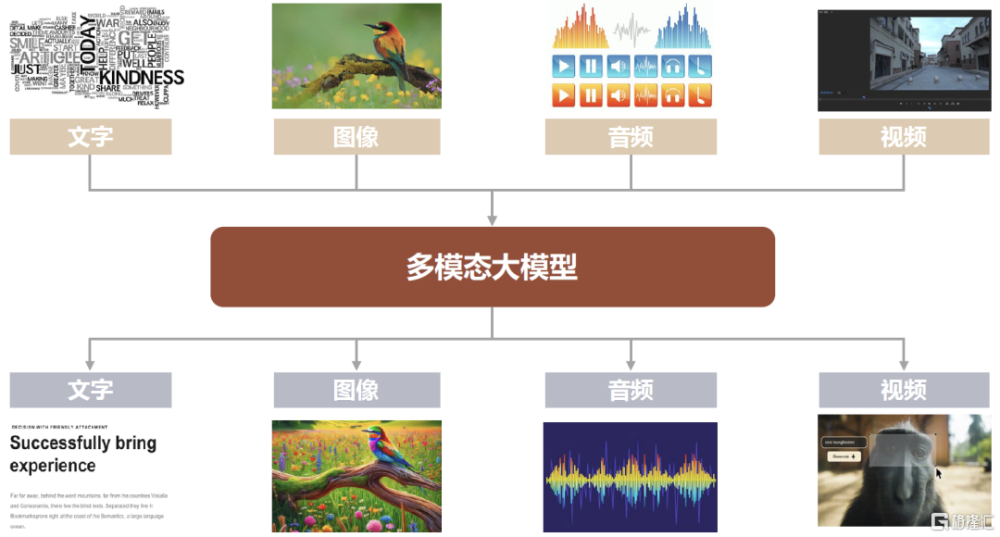
資料來源:Pika官網,中金公司研究部
► 多模態大模型更符合人類感知世界的方式,具備處理更爲復雜任務的可能。人類的智能是接受多種感官模態的輸入並進行輸出,而多種模態之間的跨模態混合交互也起到了互補的作用,進而產生了更高維度的“智能”來處理更爲復雜的任務。而多模態大模型就是要在訓練、輸入、輸出數據的模態豐富度上與人類智能進一步對齊,進而力求實現更高維度的智能“湧現”,以及處理更爲通用、泛化的復雜任務的能力。
► 多模態大模型具有更爲豐富的學習數據來源,具有進一步突破能力上限的機會。單模態語言大模型僅基於人類的文字語料進行訓練,其數據來源有限且正處在迅速的學習消耗過程中。但多模態大模型可以利用自然界中天然存在的更爲豐富的圖像、聲音等數據與信息進行訓練,中金研究認爲其“智能”的上限在理論上或將高於單模態大模型。
► 多模態大模型在交互上更貼近人類的習慣,提供更優化的大模型使用體驗。單模態語言模型在交互方式上較爲單一,而多模態大模型能夠對多種類型的輸入進行支持,用戶也得以以更加靈活便捷的方式與模型進行交互操作,達到更爲友好的使用體驗。
圖表:產學研界旨在多模態領域“復刻”LLM語言大模型的成功
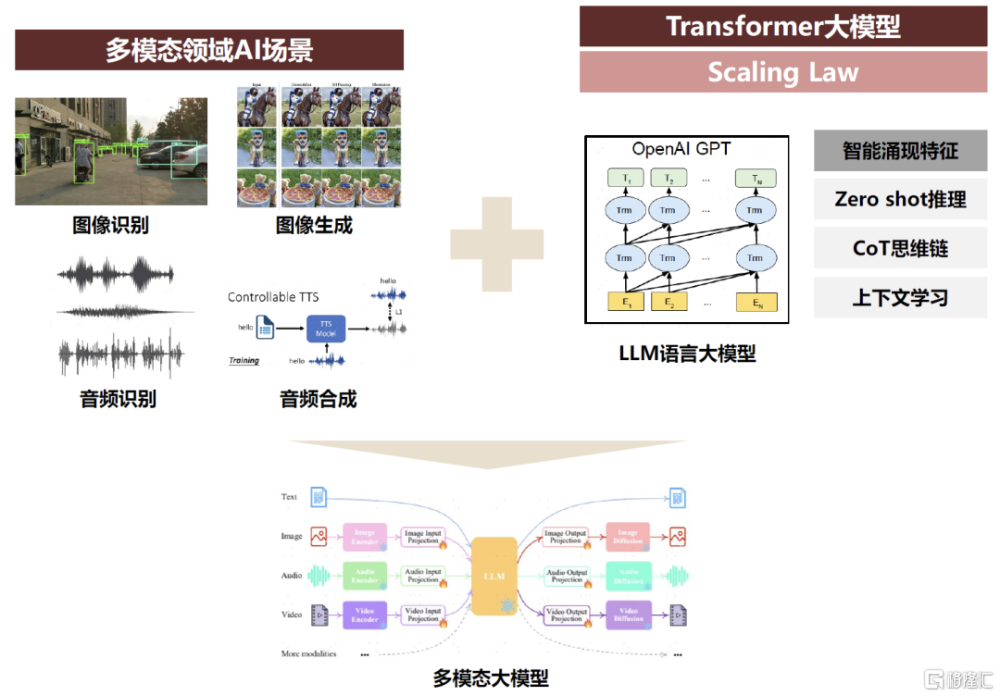
資料來源:《Multimodal Foundation Models: From Specialists to General-Purpose Assistants》(Tang et al., 2023),中金公司研究部
產業界對於多模態大模型的探索有何進展?
如何去“學習”多種模態的特徵以及模態之間隱含的關系是構建多模態大模型的重點。在構建和訓練多模態大模型時,本質上是要把多種不同的模態在一致的特徵向量空間中進行表徵,進而讓模型能夠對不同模態隱含的特徵以及不同模態之間隱含的關系進行學習。在這一過程中,需要找到更合適的對於各種模態信息的特徵表達,以及讓模型訓練出更合適的將不同的模態特徵映射至一致的向量空間中的投影方法,進而讓模型達到更好的推理效果,最終實現多模態領域的“智能湧現”。
多模態大模型的一種典型架構:各模態的編解碼器+投影/壓縮網絡+生成網絡。對於多模態大模型的架構,過去數年來產業界也嘗試了多種路线的探索,其中一種較爲典型的架構如下圖所示,主要由三部分構成。
► 文字、圖像、視頻等多種模態的編解碼器(多模態信息的感知和抓取),編碼器負責將輸入的多模態信息轉換成特徵表示,進而能夠讓模型對輸入的信息進行理解。由於編碼器的類型可以有多種不同的選取方式,因此其轉換出的特徵表示的形式和維度仍存在區別,實際上是處於不同的向量空間中;解碼器則負責在最後將前部分模型輸出的特徵表示解碼還原成文字、圖像、視頻等不同類型的模態信息,最終得到模型輸出。
► 投影/壓縮網絡(多模態信息的對齊和交互),多模態大模型需要對不同模態的特徵進行理解和處理,因此在不同模態的輸入信息通過編碼器得到特徵表示後,還需要通過中間層的投影/壓縮網絡進行處理,使得不同模態的特徵能夠在一致的向量空間中進行表徵,進而能夠讓後續的生成網絡進行統一處理。同理在生成網絡輸出向量特徵後,也需要對其進行反解,將其解壓縮並還原至原有的向量空間中。
► 生成網絡,其處於多模態大模型的中間部分,負責將不同模態信息的特徵表示在統一的向量空間中進行處理,進而達到模型預設的多模態任務訓練目標。目前產業界的許多工作是希望將大模型在語言領域“Scaling Law”的成功在多模態領域復現,因此目前很多多模態大模型中的生成網絡都是由Transformer來擔當。
圖表:多模態大模型的一種典型架構
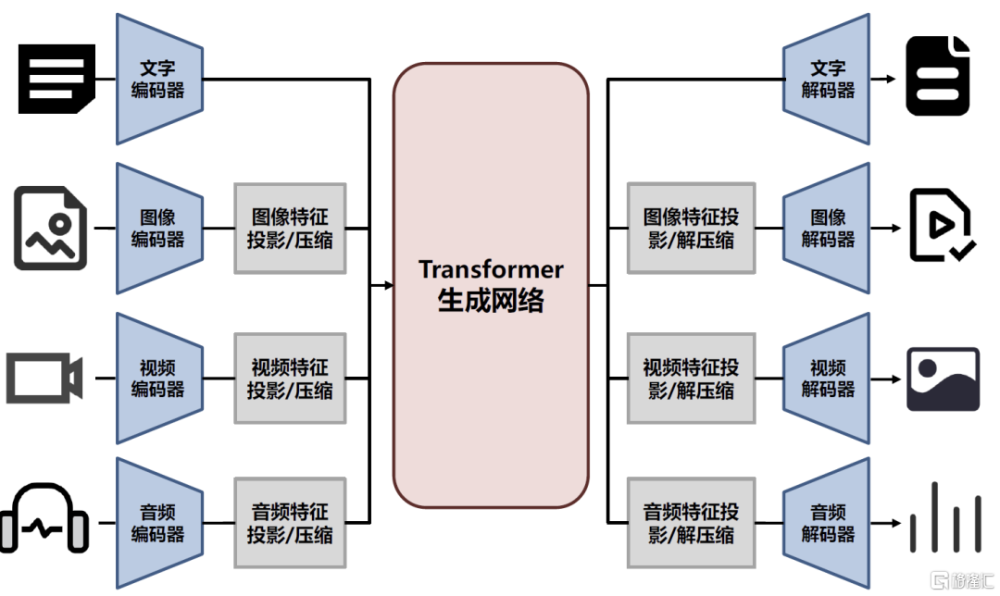
資料來源:《NExT-GPT: Any-to-Any Multimodal LLM》(Wu et al., 2023),中金公司研究部
多模態大模型領域的技術棧尚未收斂。實際上目前產業界在多模態大模型的架構路线上也仍存在一定分歧,比如有一些路线是採用“全Token化的方式”,即直接將文字、圖像、視頻等不同的模態信息特徵都進行Token化,在LLM能夠一致處理的向量空間中進行表徵,進而用Transformer進行統一處理。但也有一些路线是對於不同的模態選取不同的方式進行特徵提取和處理,再通過訓練多模態轉換器或者感知器,對特徵表示進行投影,進而讓預訓練好的LLM對圖像、視頻等其他模態特徵進行感知和處理。總體來看,產業界對於多模態大模型的技術路线探索尚未成熟收斂,不同的路线都有大量的工作正在嘗試進行中。
圖表:多模態大模型領域的技術棧尚未收斂
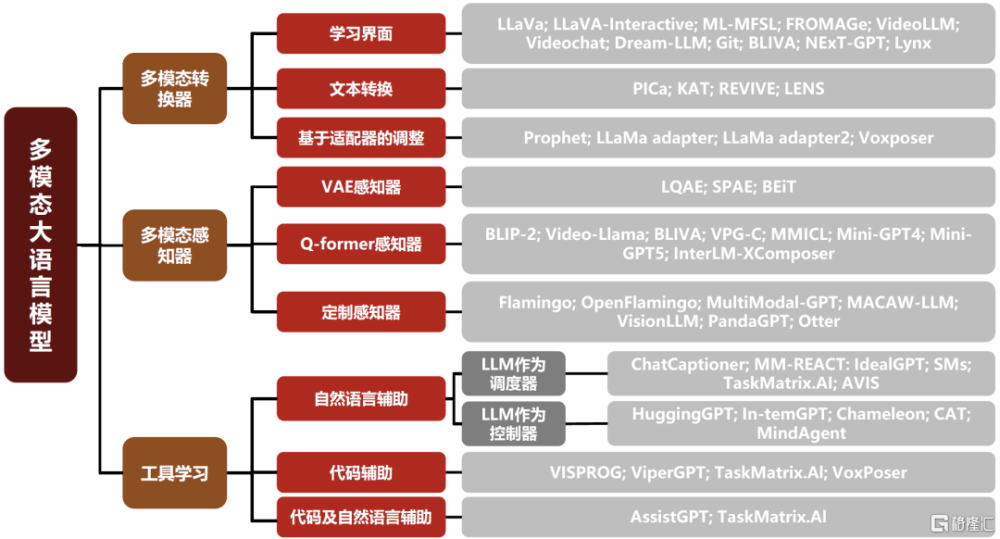
資料來源:《How to Bridge the Gap between Modalities: A Comprehensive Survey on Multimodal Large Language Model》(Song et al., 2023),中金公司研究部
多模態大模型的探索並非一蹴而就,近年來產業聚焦在視覺等重點模態領域逐步突破。對於中金研究上文所提到的理想中的“Any-to-Any”大模型,Google Gemini、Codi-2等均是處於探索階段的方案,其最終技術方案的成熟還需要在各個模態領域的路线跑通,實現多模態知識學習,跨模態信息對齊共享,進而實現理想中多模態大模型。現階段產業主要的工作還是聚焦在視覺等典型的重點模態,試圖將Transformer大模型架構進一步在圖像、視頻、3D模型等模態領域引入使用,完善各個模態領域的感知和生成模型,再進一步實現更多模態之間的跨模態打通和融合。
► 圖像:早在2023年LLM的流行之前,過去產業界在對於圖像的理解和生成模型領域已經打下了堅實的基礎,其中也產生了CLIP、Stable Diffusion、GAN等典型的模型成果,孕育出了Midjourney、DALL·E等成熟的文生圖應用。而更進一步,產業界也在積極探索將Transformer大模型引入圖像相關任務領域(ViT,Vision Transformer;DiT,Diffusion Transformer),探索統一視覺大模型的建立,以及將LLM大語言模型與視覺模型進行更加密切的融合,包括近年來的GLIP、SAM、GPT-V都是其中的重點成果。
► 視頻:由於視頻本質上是由很多幀的圖像疊加而成,因此本質上語言與視頻模態的融合和語言和圖像具有相當多的互通之處,產業界也在嘗試將圖像生成模型遷移到視頻生成,先基於圖像數據進行訓練,再結合時間維度上的對齊,最終實現文生視頻的效果。其中近年來也產生了VideoLDM、W.A.L.T.等典型的成果,並在近期也出現了Sora這樣具有明顯突破性效果的模型,其在視頻生成領域沿用了Diffusion Transformer架構,並在視頻類場景首次呈現出“智能湧現”的跡象。
► 3D模型:實際上3D是由2D+空間信息構成,因此類似於由圖像生成到視頻生成的延伸,2D圖片的生成方法理論上也可以遷移到3D中。近年來產業界也在積極探索將圖像領域的GAN、自回歸、Diffusion、VAE等骨幹模型在3D模型生成任務中的擴展,其中也產生了3D GAN、MeshDiffusion、Instant3D等重點的模型成果。但相比圖像和視頻生成,目前的3D模型生成技術還處於早期發展階段,相關模型的成熟度仍有較大提升空間。
► 音頻:語音相關的AI技術在過去多年中已經較爲成熟,但近年來Transformer大模型在AI音頻領域的投入應用,還是成功推動了相關技術再上台階,實現更優的音頻理解和生成效果,其中重點的項目成果包括Whisper large-v3、VALL-E等。
► 更多模態:除了上面中金研究提到的幾種典型的模態之外,還有很多目前沒有辦法很好的以數據形式抓取的模態(比如嗅覺、味覺、觸覺等,可能是以腦信號的形式,需要腦科學的進一步發展),以及應用場景相對細分的模態(比如結構化數據等)。中金研究認爲未來AI在多模態的領域拓展以及模型能力邊界的提升仍有無限的可能。而在下面的各個章節中,中金研究也會依次從圖像、視頻、音頻、3D等幾個典型的模態領域入手,分別就產業技術發展的脈絡和未來趨勢進行闡述。
圖表:典型的多模態領域——視覺場景近年來的主要工作概覽
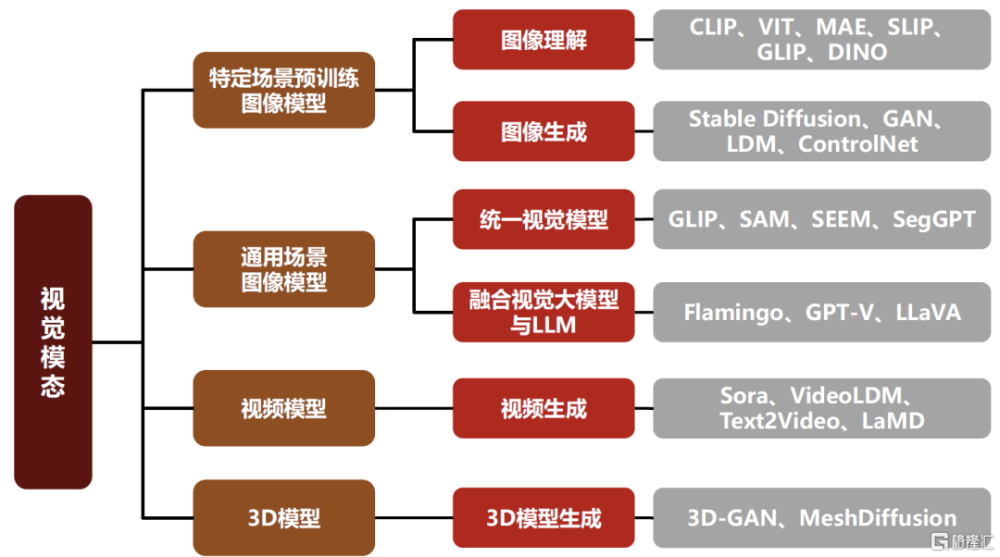
資料來源:《Multimodal Foundation Models: From Specialists to General-Purpose Assistants》(Chunyuan Li, Zhe Gan, Zhengyuan Yang, Jianwei Yang, Linjie Li,Lijuan Wang, Jianfeng Gao, Microsoft Corporation, 2023),中金公司研究部
圖像:技術路徑收斂,應用百花齊放
技術演進:源起CNN,擴散模型爲主流生圖架構
以深度學習爲基、GAN爲起點,AI生成圖像的技術發展歷史經歷四大階段。最早期階段中,20世紀末的深度學習技術,尤其是卷積神經網絡(CNN)在圖像特徵識別的能力爲機器生成基礎圖像奠定了基礎。此後,變分自編碼器(VAE)和生成對抗網絡(GAN)的問世,讓計算機得以使用概率分布和對抗式訓練精煉生成結果,爲AI生成圖像技術邁出了重要一步。隨後,擴散模型(diffusion model)的出現,以其生成高質量圖像的能力超越了傳統以GAN爲主流的生成模型。自2022年以來,基於diffusion model的AI生成圖像模型呈現繁榮增長,各類生成模型在“理解”指令和繪畫能力上都有大幅提升,顯著提升了AI生成的圖像質量和降低了優質內容的創作門檻。
圖表:擴散模型已成爲目前多模態圖像技術的主流路线
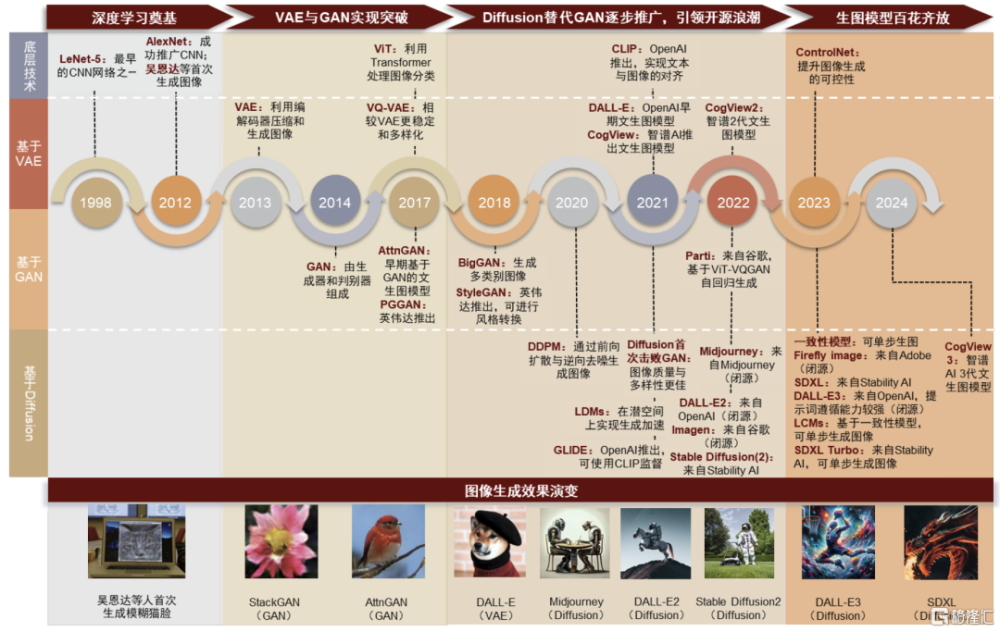
資料來源:Fabianmosele,量子位,OpenAI官網,Stability AI官網,中金公司研究部
展望未來,Image caption(圖像描述)路线凝聚圖文對齊共識,有望進一步推廣。多模態技術進展迅速,數據重要性凸顯,在實際應用中多模態數據不易獲得、標注欠缺細節,而合成數據可提升訓練的多樣性及模態對齊的精確度,成爲有效的數據增強手段。根據DALL-E 3論文結論[1],在訓練模型時結合合成標注有望提升模型CLIP Score。中金研究認爲Image caption將成爲合成標注訓練文生圖模型的重要路徑,普遍操作是使用微調後的圖-文預訓練模型生成高質量文本描述,此外細致的長文本標注將更有效優化模型表現。當前OpenAI DALL-E 3、華爲PixelArt-α均積極探索該路线。
立足二維圖像出發點,向三維領域延拓。文生圖模型DiTs依托Transformer架構實現更強大的計算能力,爲處理更復雜的3D、視頻數據奠定基礎,在後續OpenAI視頻生成模型Sora中得到應用。中金研究認爲隨着2D圖像生成模型在效率、一致性等方面的提升,有望推動3D模型與視頻多模態領域技術變革。
視頻:優化時序對齊,生成效果突破
技術基礎:圖片生成模型疊加時序對齊實現視頻生成
視頻本質上是一系列圖像的連續展示,圖片生成是視頻生成的基礎。圖片生成的主流技術即擴散模型同樣也是視頻生成的主流技術,目前主流的文生視頻模型的技術路线爲基於文生圖模型,通過在時間維度加入卷積或注意力,在生成的關鍵幀基礎上實現時序對齊得到視頻。在此基礎上,插幀+超分、初始噪聲對齊、基於LLM增強描述等方法均有助於增強時序對齊能力,實現更高質量的視頻生成。Zero-shot領域的一系列研究則能夠實現無需訓練,直接將圖片生成模型轉化爲視頻生成模型。
圖表:基於擴散模型的文生視頻模型主要文獻
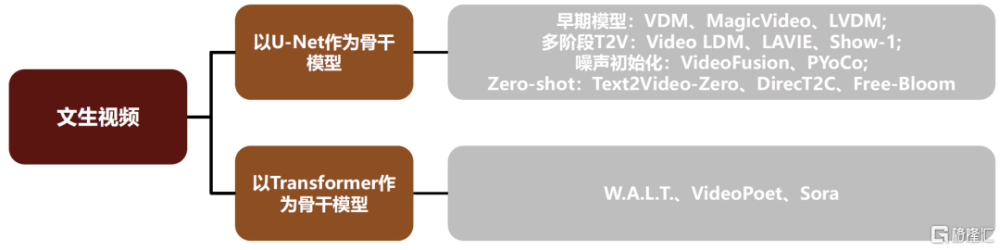
資料來源:《A survey on video diffusion models》(Xing et al., 2023),中金公司研究部
模型改良:Transformer代替U-Net,模型可拓展性大幅增強
Transformer代替U-Net,可拓展性更強的視頻生成模型得以出現。前文中金研究提到,基於U-Net的擴散模型是文生視頻模型的主流技術,而這類擴散模型參數量相對較小,可拓展性相對較弱。爲解決模型的可拓展性問題,學界和業界將Transformer架構引入視頻生成任務,具體可以分爲兩類:1)將Transformer代替U-Net引入擴散模型,構建DiTs(Diffusion transformer);2)構建基於純Transformer的視頻生成模型。由於Transformer的全注意力機制產生的內存需求會隨着輸入序列的長度增加而呈現平方增長,因此處理高維信號(如視頻)時,模型對計算量需求更大,訓練和推理成本或明顯高於基於U-Net的擴散模型。
Sora:基於DiTs架構,實現長視頻的高質量生成
Sora展現了高質量的長視頻生成能力,相較先前的視頻生成模型,中金研究認爲其最爲突出的創新之處在於:1)視覺編碼器實現時間空間維度壓縮並進行Patch(圖塊化)處理,使得長視頻生成成爲可能;2)借助Transformer的位置編碼性質,使用不限制輸入形狀的DiTs,能夠創新性地實現任何像素和長寬比視頻的生成;3)中金研究判斷其訓練數據集中可能包含帶有物理信息的合成數據,從而使模型展現出對物理信息的初步理解能力;4)復用DALL·E 3的重標注技術,對視頻數據生成高質量文字標注,借助GPT對提示詞進行擴展,提升生成效果。
圖表:Sora可能的模型架構
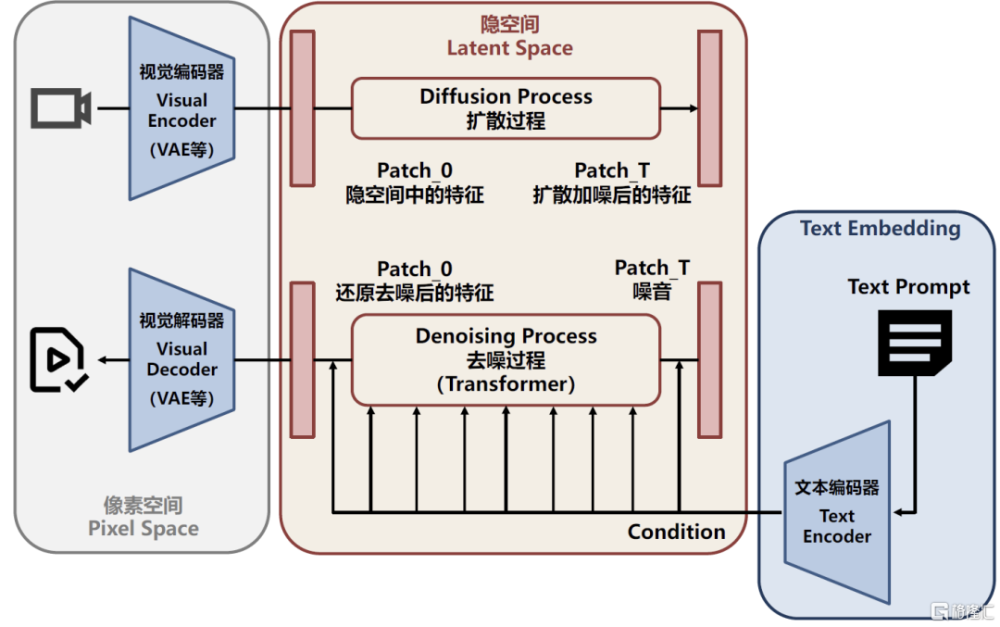
資料來源:Sora技術報告,中金公司研究部
視頻生成模型展望:物理信息感知增強+視頻生成時間延長。中金研究認爲Sora具備了初步的物理關系理解能力,在視頻生成時長上也實現了從秒級到分鐘級的突破。展望未來,伴隨參數規模的提升和訓練數據的增加,中金研究認爲視頻生成模型或能習得更多“物理運動規律”,從而生成更貼合實際的視頻;另一方面,模型規模的提升直接表現爲對視頻處理能力的增強,類似自然語言領域LLM的迭代,中金研究認爲生成視頻時長或持續提升,未來“短片”甚至“電影”的生成或將成爲可能。
語音:Transformer加持,AI配音興起
技術前沿:Transformer加持下的語音合成發展更趨成熟
語音技術沿革可分爲三階段,深度學習驅動發展加速。1950年代語音技術處於技術早期,模版匹配、串聯合成等技術得到發展,效果有限;1980年代引入以HMM(隱馬爾可夫模型)爲代表的參數統計模型,增加對語音信號的建模精度,提高語音識別的准確性以及語音合成的質量;2009年後步入深度學習時代,採用神經網絡進行聲學建模,更靈活地捕捉文本特徵與語音特徵的復雜映射,從DNN、RNN到Transformer,語音技術迎來高速發展。
圖表:深度學習驅動當前語音技術快速發展,Transformer成爲主流路线
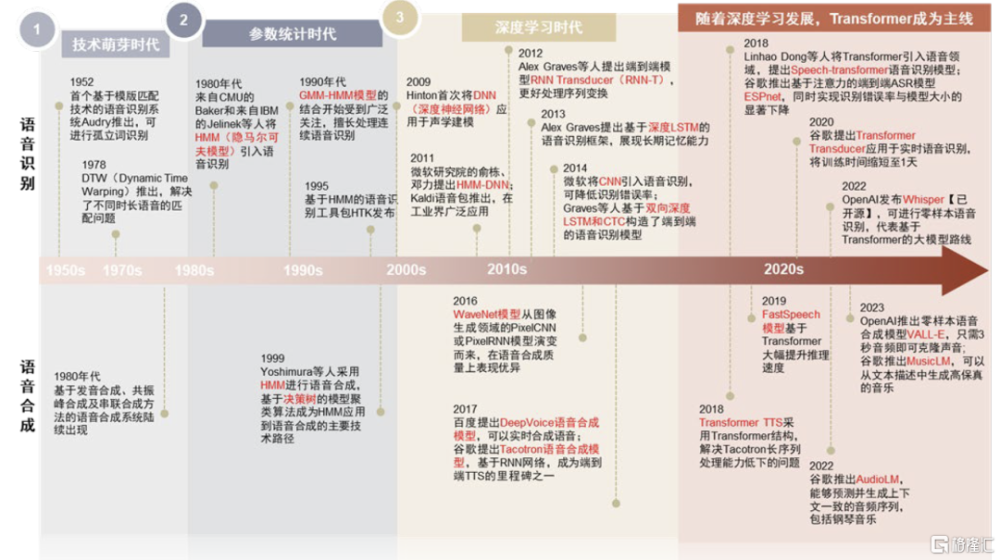
資料來源:廈門大學語音實驗室,中金公司研究部
語音技術主要向增強泛化能力的方向持續延伸,Transformer架構引領語音技術迭代浪潮。泛化能力是指模型對於未經訓練的數據的適應能力,技術基礎來自具有強大學習能力的網絡架構和大量多樣化的數據訓練。語音模型泛化能力的增強主要體現在:從覆蓋單一語種到多語種和方言,從處理人聲到自然聲音、音樂,從簡單語音識別或合成到零樣本學習和多任務集成。目前Transformer已成爲語音技術的baseline(基线)架構。Transformer模型具備強大的泛化能力,高度受益於其並行訓練能力和多頭注意力機制:多頭注意力機制允許模型從多角度學習序列特徵,在捕捉復雜信息和處理長依賴問題時表現出色,提升模型在復雜場景下的魯棒性;並行訓練能力能夠幫助模型處理更大規模、多樣化的數據,間接提升模型通用性。
3D:產業持續探索,方向初見端倪
3D生成任務要素:數據表徵、數據集、生成模型、應用
3D生成領域的整體思路:2D+空間信息。中金研究認爲視頻和3D的生成均可以視爲2D圖片生成任務的延伸,其中視頻即爲在圖片生成的基礎上增加時間信息,實現時序的對齊;3D則爲2D的基礎上增加空間信息,實現高維的拓展。因此,在2D圖片生成領域的主流主幹模型(GAN、自回歸、Diffusion、VAE等)均可以在3D生成任務中實現模型擴展。在研究3D領域之前,《Advances in 3D Generation: A Survey》(Li等,2024)對3D領域的數據表示、訓練數據集、訓練數據集、3D生成模型種類、應用等做了歸納總結:
► 3D數據表徵:包括網格(Mesh)、點雲(Point clouds)等顯式表示,以及NeRF(Neural radiance fields,神經輻射場)等隱式表示,還包括體素(Voxel grids,3D空間中的像素)這類混合表示,其中NeRF具有強大的三維表達能力和潛在的廣泛應用範圍,是3D數據表徵的關鍵技術;
► 3D數據集:包括3D數據(數據量和精度有限)、多視角圖片(用途最爲廣泛)、單張圖片(使用仍具有較大難度)等。目前3D對象數據集仍然稀缺,代表性的數據集包括ShapeNet(Chang等,2015)構建了5.1萬個3D CAD模型,爲3D數據集的充實做出开創貢獻;Deitke等(2023)構建了Objaverse和Objaverse-xl數據集,分別有80萬和1000萬個3D對象;
► 3D生成模型:前饋生成(通過前向傳遞中直接生成結果)、基於優化的生成(每次生成需要迭代優化)、程序生成(根據規則創建3D模型)、生成式新視圖合成(生成多視角圖像);
► 3D應用:包括3D人生成、3D人臉生成、3D物體生成、3D場景生成等應用。
圖表:3D生成領域涵蓋3D表示、3D生成模型、數據集、應用
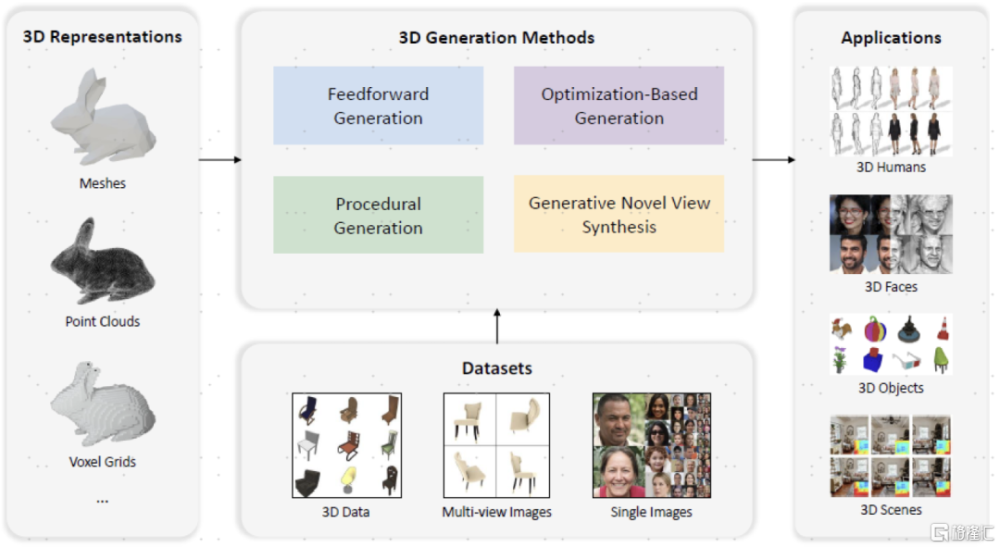
資料來源:《Advances in 3D Generation: A Survey》(Li et al., 2024),中金公司研究部
3D生成可能是未來視覺多模態領域取得突破性進展的下一場景。回顧生成類大模型的發展進度,首先以GPT-3爲代表的大模型在語言領域最先取得突破;接下來擴散模型逐步成熟使得圖片生成任務能夠很好完成;以圖片爲基礎,中金研究認爲視頻可以看做圖片在時間維度的擴展,以Sora爲代表的大模型也產生了良好的效果,而3D模型則可以看做圖片在空間維度的擴展,中金研究認爲3D生成模型或成爲下一個階段學界和產業界進一步突破的方向,建議重點跟蹤和關注前沿進展。
3D模型生成技術的突破也會使產業邁向“世界模型”的探索更近一步。中金研究認爲,若3D生成模型取得突破,則意味着大模型對空間信息的理解能力明顯增強,能夠學習到三維世界中的信息並生成三維物體和場景。結合視頻(大模型對動作的時間變化的理解能力)領域取得的突破成果,大模型或能夠具備對物理世界的時空信息具備更加完整把握能力,因此中金研究認爲3D模型的潛在突破進展或能對構建理解一定物理信息的“世界模型”更進一步。
注:本文摘自中金研究2024年3月5日已經發布的《人工智能十年展望(十七):大模型興起之後,多模態湧現之前》,分析師:於鐘海 S0080518070011 ;王之昊 S0080522050001 ;魏鸛霏 S0080523060019 ;譚哲賢 S0080122070047;肖楷 S0080523060007 ;遊航 S0080523010001
標題:中金:大模型興起之後,多模態湧現之前
地址:https://www.iknowplus.com/post/87070.html







