模型+工程創新,DS給硬件市場帶來哪些變化?
在本系列報告的第一篇中,我們深度討論了DeepSeek(以下簡稱DS)技術創新對訓練硬件的需求變化。除了訓練以外,DS團隊在最新一系列的开源成果發布中針對推理任務也做出了雙重維度的創新:一方面通過模型優化降低硬件資源佔用,另一方面通過硬件工程化優化以發揮硬件最大效能。
摘要
模型創新:借助MLA、NSA等技術優化加速推理。在上一篇聚焦訓練任務的報告中,我們重點解讀了DS大語言模型中前饋網絡(FFN)架構部分由稠密演化到稀疏(MoE,專家模型)產生的影響,同時,DS在注意力機制(Attention)部分也做出了創新。針對傳統Attention部分需要計算所有詞對之間關聯的特性,在處理文本變成長時,計算量和內存消耗會呈現大幅增長。我們認爲DeepSeek獨創的多重潛在注意力機制(Multi-Latent-Attention,MLA)方法,通過將佔用內存較大的KV矩陣投射到隱空間來解決KV cache佔用過多的問題,類似“高度概括的全局視角”;而近期,DS團隊又在最新發布的論文[1]中指出,可採用原生稀疏注意力(Native Sparse Attention, NSA)方法,從底層設計避免計算無關詞對注意力,類似“關鍵信息的詳細洞察”,直接對序列長度進行壓縮,優化推理算力、存儲开銷。
硬件工程優化:DS團隊採用PD分離+高專家並行度策略充分釋放硬件性能。首先,針對推理過程中預填充(Prefill)和解碼(Decode)兩個對計算/存儲資源要求的差異性較大的任務分別做了針對性的硬件優化配置;其次,爲實現更好的計算單元利用效率並平衡通信开銷,DS團隊在Decode階段採用了高達320的專家並行度(Expert Parallel)來布置推理硬件。DS團隊也开源了MLA相關內核(Kernel),直接解密MLA結構在NV硬件上的具體實現,我們認爲這給开發者優化適配其他硬件(如國產卡)提供了思路。
硬件需求啓示:1)集群推理成爲主流形式,利好以太網通信設備需求;2)DS團隊爲市場帶來高水平的开源模型後,雲端/私域部署需求快速增長,我們測算僅微信接入DS模型有望帶來數十萬主流推理卡的採購需求。結構上,除海外產品外,國產算力鏈以其快速的適配也迎來了商業機會。
風險
生成式AI模型創新、AI算力硬件技術迭代、AI應用落地進展不及預期。
DeepSeek在模型推理過程中引入了哪些創新?
模型創新
V3/R1延續V2的MLA架構,優化KV Cache,加快推理速度
傳統的Transformer模型通常採用多頭注意力機制(Multi-Head-Attention, MHA),但在生成過程中,隨着前置序列的長度變長,需要讀取的KV cache也將越來越大,數據的傳輸成本增加,KV緩存會限制推理效率。減少KV緩存的策略包括MQA和GQA等,它們所需的KV緩存規模較小,但性能卻無法與MHA相比。
圖表1:MHA、GQA、MQA、MLA 架構對比
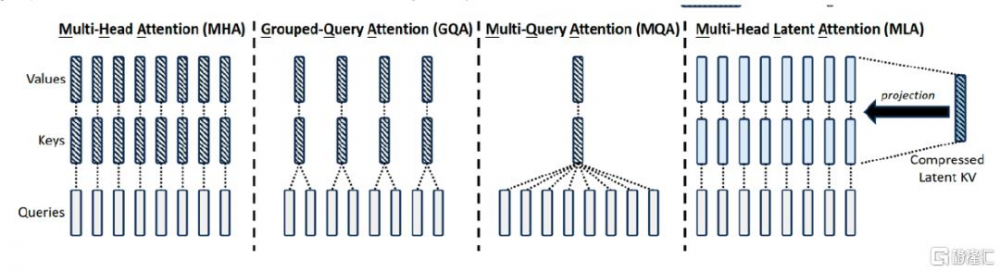
資料來源:DeepSeek V2 技術報告,中金公司研究部
DeepSeek 團隊創新引入了多頭潛在注意力機制(Mult-Head-Latent-Attention,MLA)技術,通過壓縮 KV 存儲,即不對所有的 Key 和 Value 進行存儲,而是存儲一個低秩的變量C,將其投影至隱空間,在計算過程中再恢復出 Key 和 Value,得出原始值,大幅降低存儲需求。按照此方式,KV Cache 只存儲所有注意力頭中 KV 共性的內容,差異性內容在推理時進行計算,將解碼過程的訪存密集型任務轉換爲計算密集型任務。在具體實現機制上,由於推理過程中將隱空間向量恢復到KV原空間所需的矩陣可以與其他矩陣進行吸收合並,因此並未增加計算量,巧妙地獲得了“省存儲但並無多余計算开銷”的效果。
圖表2:DeepSeek MLA實現方法示意圖
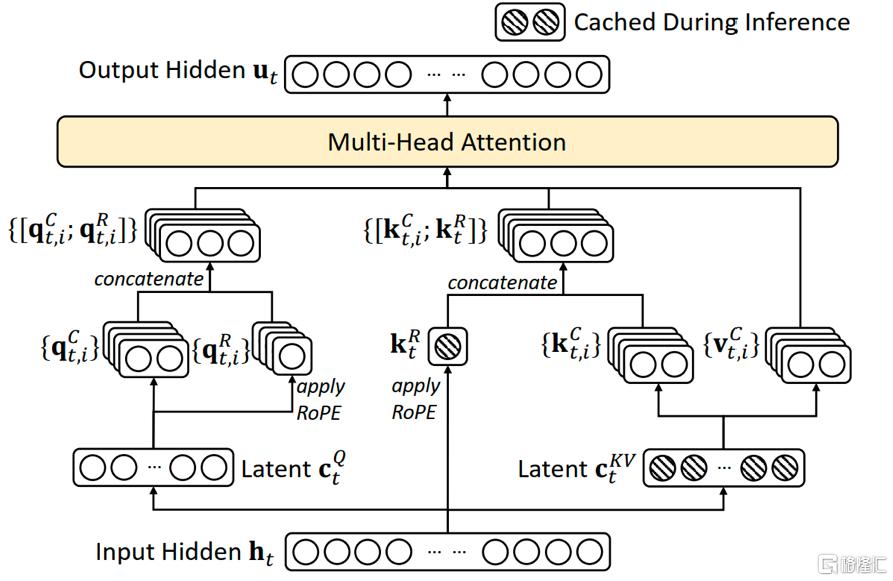
資料來源:DeepSeek V2 技術報告,中金公司研究部
根據DeepSeek發布的《DeepSeek-V2技術報告》,MLA在KV緩存中存儲的元素數量較少,相當於只有2.25組的GQA,但可以實現比MHA更強的性能。如下圖所示,兩個MoE模型(分別具有16B和250B總參數)使用不同的注意力機制時,MLA在大多數基准上都優於MHA。MLA 在減少 KV 緩存的基礎上,還提高了性能與效率。
圖表3:MoE模型使用不同注意力機制的表現
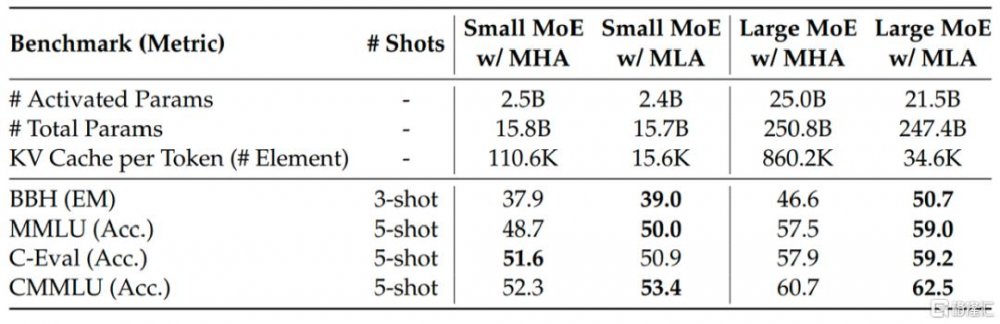
資料來源:DeepSeek V2技術報告,中金公司研究部
NSA技術直接壓縮序列長度,實現高效的長文本建模
近期,DeepSeek團隊又提出的新的原生稀疏注意力機制(Native-Sparse-Attention,NSA)[2],集成了分層字符建模,將算法創新與和硬件對齊的優化相結合,以實現高效的長文本建模。NSA 通過將鍵和值組織成時間塊並通過三條注意力路徑處理它們來減少每個查詢的計算:Token壓縮、Token選擇、滑動窗口。1)Token 壓縮:聚合塊內信息生成壓縮的粗粒度表示,保留全局語義;2)Token選擇:基於壓縮塊的注意力得分,只保留前 N 的塊參與計算;3)滑動窗口:在局部範圍內保持一個連續的上下文窗口,從而確保模型不會錯過局部關聯的重要信息。
圖表4:DeepSeek NSA架構示意圖
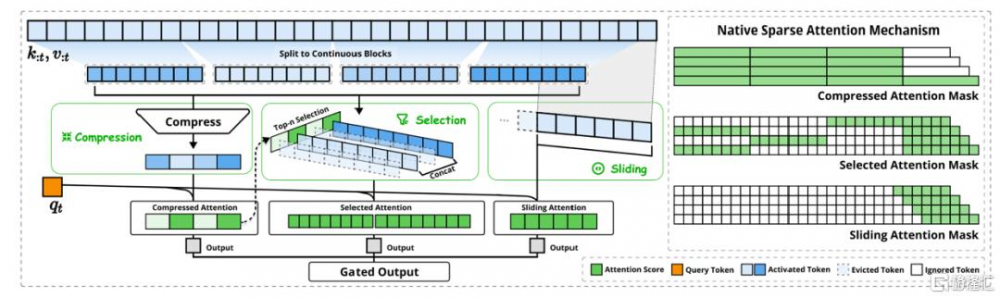
資料來源:DeepSeek NSA技術論文,中金公司研究部
在此基礎上,NSA 給出了一套軟硬協同的解決方案,通過定制化 GPU 內核(Kernel,即在GPU上並行執行的一段代碼),充分挖掘硬件潛力,將理論上的計算量減少轉化爲實際的性能提升。DeepSeek NSA內核的專有特性主要爲: 1)以組爲中心的數據加載:一次性加載一個組內所有頭的 query,以及它們共享的稀疏KV塊;2)共享 KV 獲取:同組的共享 KV只需要加載一次到GPU高速緩存,減少內存訪問次數;3)網格上的外部循環:用NVIDIA Triton網格調度器更好地調度任務,GPU 可以更高效地並行處理任務。
圖表5:DeepSeek NSA 定制 GPU 內核設計示意圖
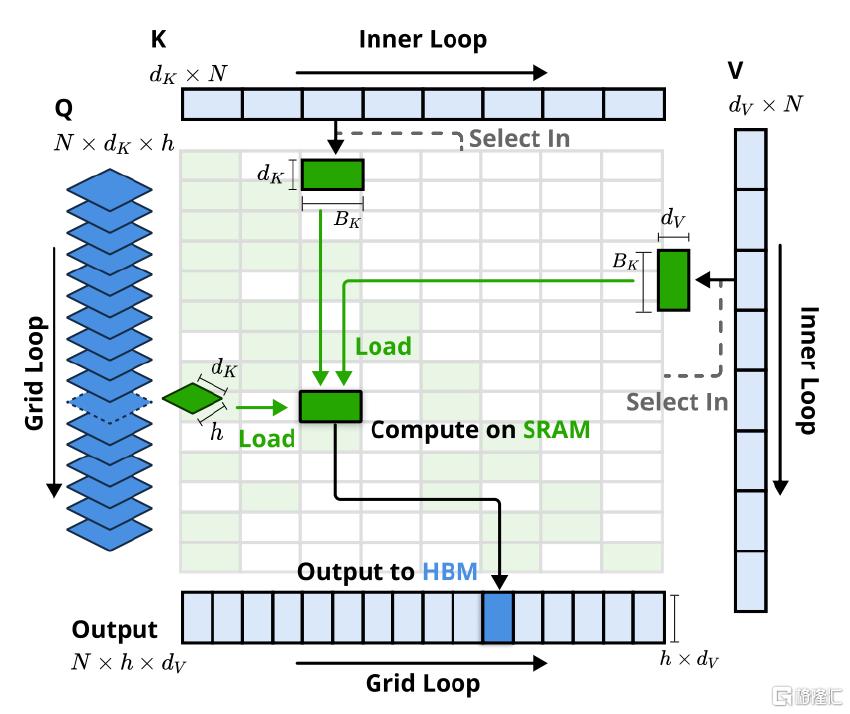
資料來源:DeepSeek NSA技術論文,中金公司研究部
在實證結果上,NSA 雖然爲稀疏架構,但仍然在一般通用性能上有着卓越的表現,在場上下文的表現上尤爲出色。在效率上大大提升了解碼速度(與 KV 緩存量密切相關,如下圖6所示),隨着解碼長度的增加,NSA 低延遲特性體現地愈發明顯,在 64k 上下文長度下實現了高達 11.6 倍的加速。同時,DeepSeek發布的NSA論文也指出,此技術同樣對訓練過程有加速作用,在 64k 上下文長度下實現了 9.0 倍的前向加速和 6.0 倍的反向加速。
圖表6:NSA 與全注意力機制在不同文本長度下內存訪問效率對比
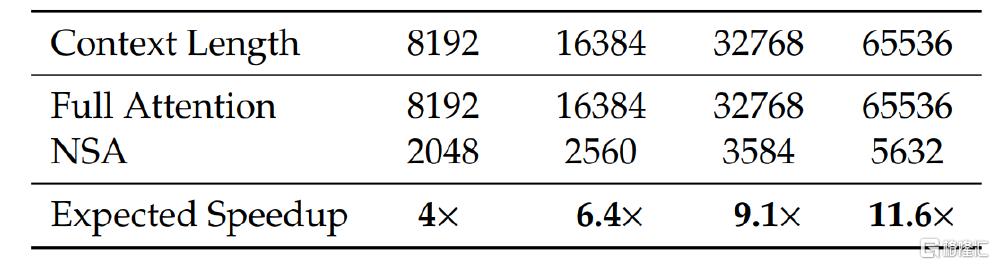
資料來源:DeepSeek NSA 技術論文,中金公司研究部
我們認爲,對比之前在 V2、V3 中應用的 MLA 機制,MLA是壓縮KV Cache的內存佔用,而NSA是從序列長度的壓縮;NSA 架構更關注局部關鍵細節而 MLA 架構更關注全局視角建模,兩者各有所長,除推理應用外,我們認爲DeepSeek 也有望在後續訓練中整合兩者來提高模型整體能力。
圖表7:全面認識DeepSeek注意力機制層面的創新:各類機制對比

資料來源:DeepSeek-V2技術報告,DeepSeeek NSA技術論文,中金公司研究部
硬件工程化創新
Prefill/Decode分離,平衡訪問內存與計算
我們看到,在推理端DeepSeek採用了Prefill(預填充)/Decode(解碼)分離的策略(簡稱PD分離策略)。PD分離通過將數據預填充和解碼過程拆分到不同的計算設備上各自獨立運行,來提升推理效率和准確性。Prefill階段主要負責將輸入數據預處理並加載到硬件中,從計算特性上來說屬於計算密集型,完成KV Cache的生成後,prefill階段本身無需繼續保留這些緩存;而Decode階段則是根據模型的計算結果生成輸出,從計算特性上來說屬於儲存密集型,通常涉及大量、頻繁地訪問KV Cache;二者的計算特性不同導致難以在單一設備上運行時同時提高兩個階段的能力,如下圖所示。我們認爲將 Prefill 與 Decode 過程分離,並選擇適配的硬件是未來 MoE結構模型硬件工程優化的趨勢。
圖表8:Prefill Decode 階段輸出隨 Batch size 變化
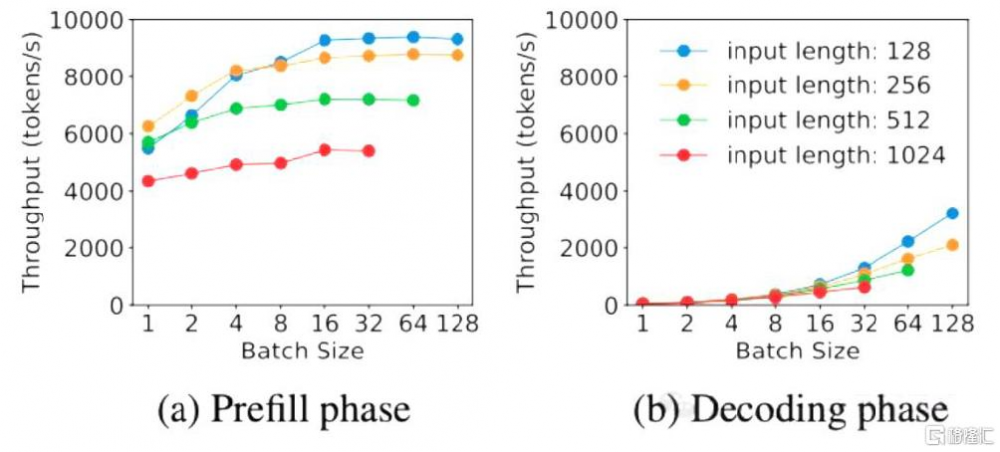
資料來源:DistServe 技術論文[3],中金公司研究部
在《AI進化論(1)》中,我們已經對各種並行計算策略做了基礎分析,再此不再贅述。針對Prefill和decode階段不同的需求,在硬件工程化具體的實施上DeepSeek也採取了針對性的策略,以DeepSeek-V3模型爲例:
► Prefill過程採取4節點32GPU的配置,其中Attention部分採取TP4(Tensor Parallel)+SP(Serial Parallel)+DP8(Data Parallel)的配置,MoE部分採取EP32(Expert Parallel)的配置,以保證每個專家都有較大的batch size,增加計算效率,All2All通信方面域訓練設置相同,不拆分張量。
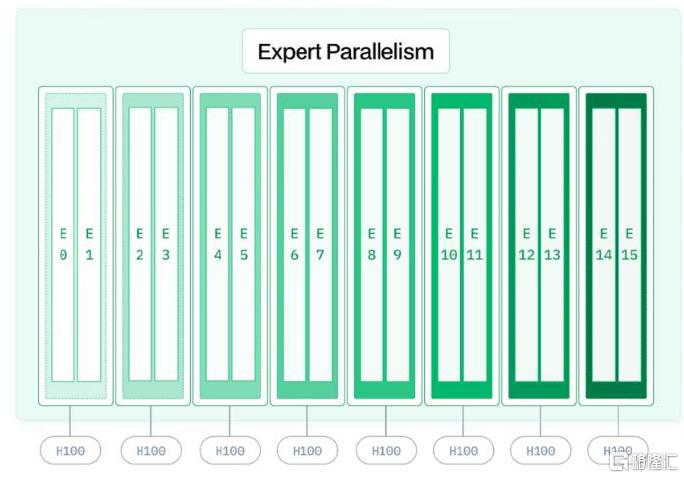
► Decode階段採取40節點320GPU的配置,其中Attention部分採取TP4+SP+DP80的配置,MoE部分採取EP320的配置。
特別來看,在Prefill和Decode過程中,DS團隊還分別設置了“冗余專家(Redundant Expert)”、以及動態冗余策略來優化硬件使用。具體來看,冗余專家是指系統會檢測高負載的專家,並將這些專家冗余部署在不同的 GPU 上,從而平衡每個 GPU 的負載;而動態冗余策略是指,即在每個推理步驟中動態選擇激活的專家,以進一步優化推理效率,即若在推理過程中,某個專家因爲處理了過多的 token 而負載過高,DeepSeek會自動將該專家的部分負載轉移到其他 GPU 上的冗余專家,從而確保推理過程的順利進行。最終的部署方案是,DeepSeek-V3模型在Prefill過程中單GPU承載9個專家,Decode階段單GPU承載1個專家,320卡中256個GPU承載原模型中的專家,64個GPU負責冗余/共享專家。同時,爲減少通信开銷,微批次(Micro-Batch)的使用也很普遍。
圖表9:張量並行(Tensor Parallel,TP)硬件部署示意圖
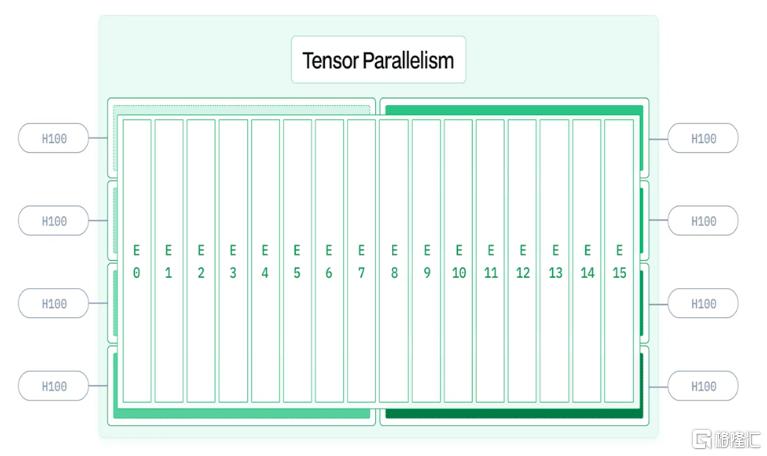
資料來源:https://www.baseten.co/blog/how-multi-node-inference-works-llms-deepseek-r1/,中金公司研究部
圖表10:專家並行(Expert Parallel,EP)硬件部署示意圖
資料來源:https://www.baseten.co/blog/how-multi-node-inference-works-llms-deepseek-r1/,中金公司研究部
增加專家並行度以應對MoE結構變化,對網絡性能提出挑战
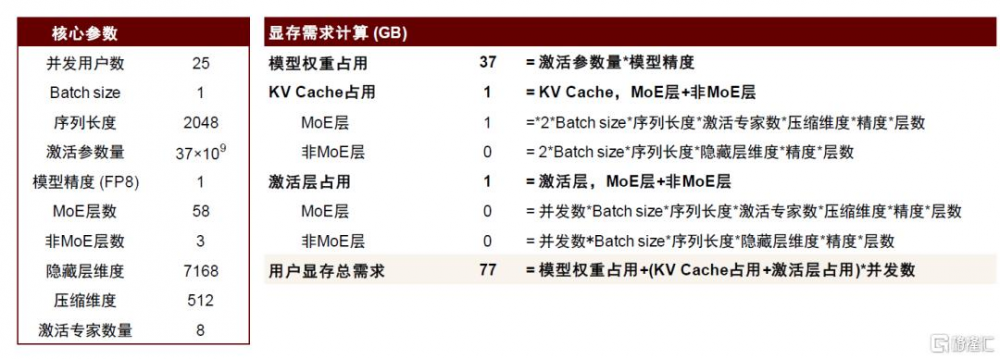
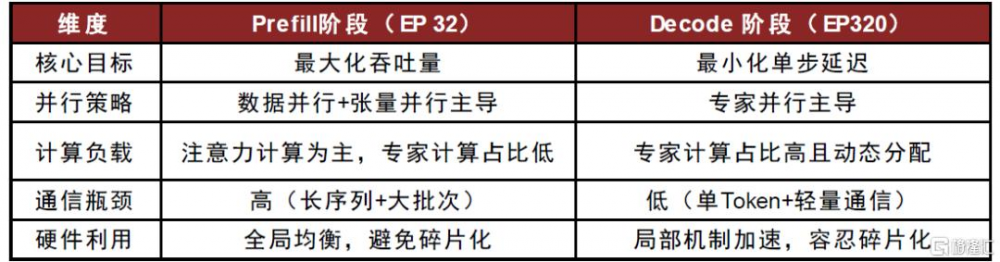
我們看到,隨生成式人工智能技術發展,由於Scaling Law的存在,MoE爲提升性能和泛化能力开始面臨參數量較大的問題。以 DeepSeek-V3爲例,在僅考慮把專家模型激活部分加載至顯存部分來看,序列長度2048、FP8精度推理情況下,25用戶並發所佔用顯存已接近NVIDIA H系列芯片顯存上限,實際應用場景必然會涉及動態路由的不可預測性、以及高並發需求,可能涉及多卡推理,甚至多節點推理情況;若考慮將671B模型參數全部加載至顯存中,僅模型權重部分單節點都能力容納,分布式推理需求應運而生。實際上,爲了實際的推理性能,DeepSeek-V3/R1這類混合 MoE 稀疏架構模型甚至採用了內存兜底策略外更高的並行度。在上文中我們已經提及,爲獲得最大化吞吐量,以及考慮到全局均衡、通信瓶頸高等因素,Prefill階段採用了32的專家並行度(EP32),而對於Decode階段,是一個通信瓶頸較低(每次只生成一個token)的場景,爲實現最小化單步延遲,採用了高達320的專家並行度(EP320),Decode硬件資源部署在40個節點上,這對網絡性能提出了一定挑战。
圖表11:推理顯存需求計算
資料來源:DeepSeek-V3技術報告,中金公司研究部
圖表12:不同應用階段專家並行度對比
資料來源:DeepSeek-V3技術報告,中金公司研究部
啓示:推理硬件技術發展趨勢和市場需求的變化方向?
推理系統部署方式:由單卡向集群演變,關注以太網投資機會
推理系統部署走向分布式集群。無論是出於均衡算力和存儲的目的,還是出於提升專家模型性能的目的,單卡或單台服務器都已難支持MoE架構下的推理任務。以671B參數的“滿血版”DSV3模型來看,甚至需要幾十台H800服務器才能實現高效推理。我們認爲,隨着推理集群規模的增長,模型推理性能呈現上升趨勢,規模效應正逐步顯現,分布式部署有望成爲未來範式。
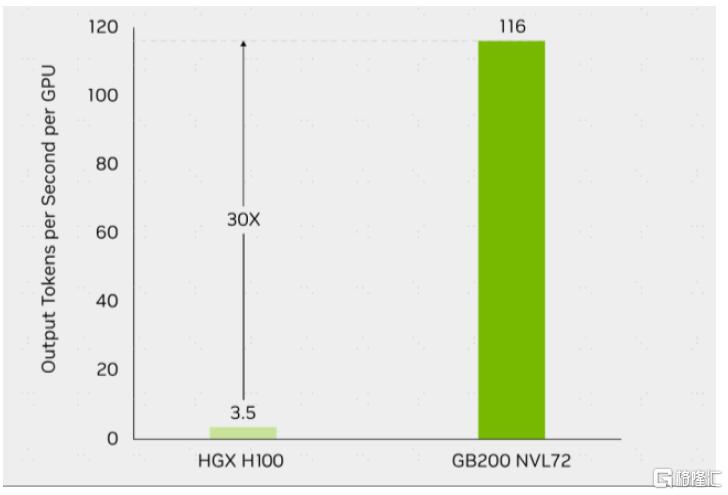
Scale-up超節點有望進一步釋放GPU性能。我們認爲,推理任務高吞吐、低時延的特性,使得scale-up網絡在推理需求釋放的AI時代中有望發揮重要作用。以英偉達NVL72爲例,其內部包含72塊Blackwell GPU和36個Grace CPU,在GPT-MoE-1.8T大模型的推理任務上可實現每卡116 tokens/s的輸出吞吐量,是HGX 100系統的近30倍。中國信通院[4]與產業力量發起ETH-X計劃,認爲超節點推理時每GPU吞吐量提升30%。
圖表13:英偉達GB200 NVL72與HGX H100單卡推理速度對比(GPT-MoE-1.8T)
資料來源:NVIDIA官網,中金公司研究部
注:1):ETH-64的基本參數:64 GPUs,70B+16MoE,Seq=64k/1k,FTX<5s,TTL<50ms
圖表14:ETH-64系統單GPU吞吐量較8卡服務器提升30%
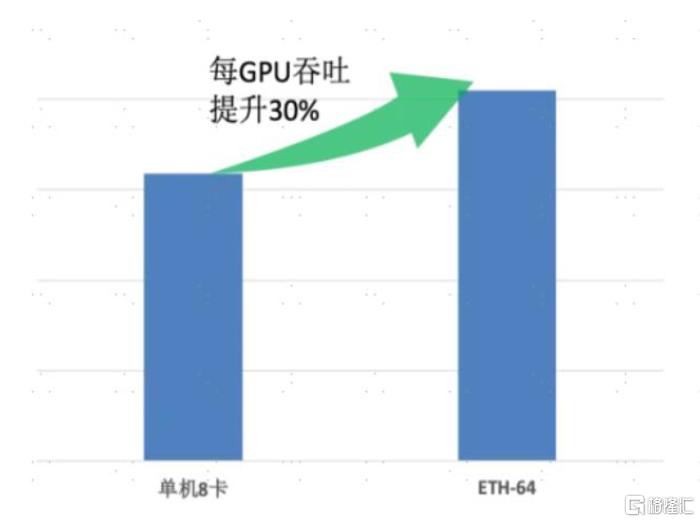
資料來源:中國信通院,中金公司研究部
以太網在Scale-up網絡中开啓滲透。在帶寬方面,以太網基本保持每兩年帶寬翻一番的迭代速度,51.2Tbps產品已實現商用,我們預計2025年102.4Tbps的產品亦有望推出,相較PCIe 5.0交換芯片4.6Tbps的交換容量處於領先。時延方面,業內一些51.2Tbps的轉發延遲已低於400ns,且通過優化可進一步降至200ns以下,屬於行業領先水平。從技術的角度看,以太網已具有取代PCIe(非英偉達體系的主流方案)的可能。行業動態方面,2024年Intel發布的Gaudi-3加速卡集成了以太網網絡,中國信通院發起的ETH-X(以太網)超節點計劃亦开始探索以太網在scale-up網絡中的應用,我們認爲以太網已在scale-up網絡中开啓滲透。
Scale-out網絡中,以太網仍有望憑借性價比獲取市場份額。技術上,InfiniBand受益於協議自身的技術優勢,能夠在數據傳輸、故障修復以及用戶對多租戶方案的要求等方面滿足智能計算要求,在TOP100中InfiniBand的佔比顯著高於以太網。但以太網也能夠應對智能計算,且RoCE(以太網+RDMA)的成本更低、使用更普遍,智能計算廠商對其認知更充分,下遊廠商仍可能傾向於使用以太網進行智能計算,TOP500中以太網的佔比與InfiniBand日趨接近。展望長期,我們認爲以太網將持續性能迭代,有望憑借經濟型與普遍性勝出。
我們建議關注推理分布式部署下,以太網同時在scale-up與scale-out網絡中滲透率提升所帶來的投資機遇。
圖表15:InfiniBand 與以太網在 TOP100 中佔比
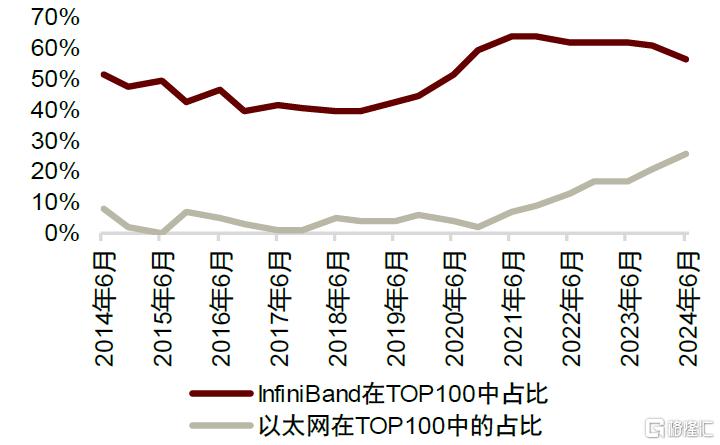
資料來源:TOP500官網,中金公司研究部
圖表16:InfiniBand 與以太網在 TOP500 中佔比
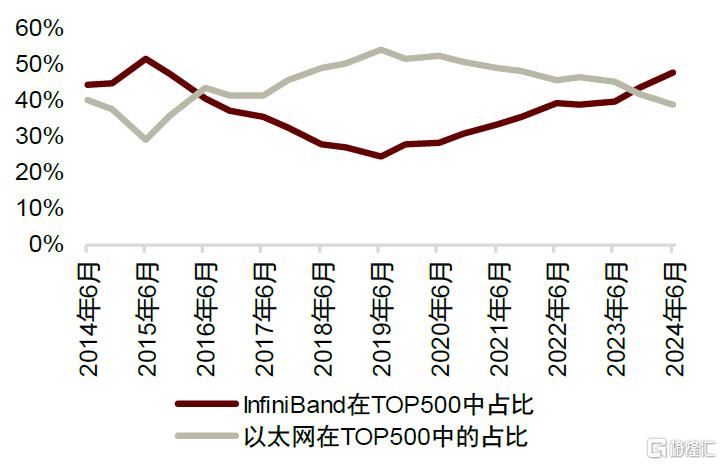
資料來源:TOP500官網,中金公司研究部
推理硬件市場增長:大模型平權帶來廣泛部署需求,接入高日活APP可帶來數十萬GPU需求
在AI進化論第一篇報告中,我們深度分析了訓練成本降低實際會帶來更廣泛商業需求的邏輯,在推理端該邏輯依然適用。我們認爲DeepSeek推理降本推動了推理需求的增長,短期內大量用戶端部署的需求增長會對推理硬件市場增長構成直接拉動,下遊應用生態的想象空間也被進一步打开。舉例來看,近期阿裏巴巴管理層也在最新業績會中表示看到了推理需求的快速增加,並开始追加雲資本开支投資。在大模型平權的趨勢下,硬件投資和應用落地的閉環初見雛形。
圖表17:“大模型平權”下的推理硬件需求邏輯
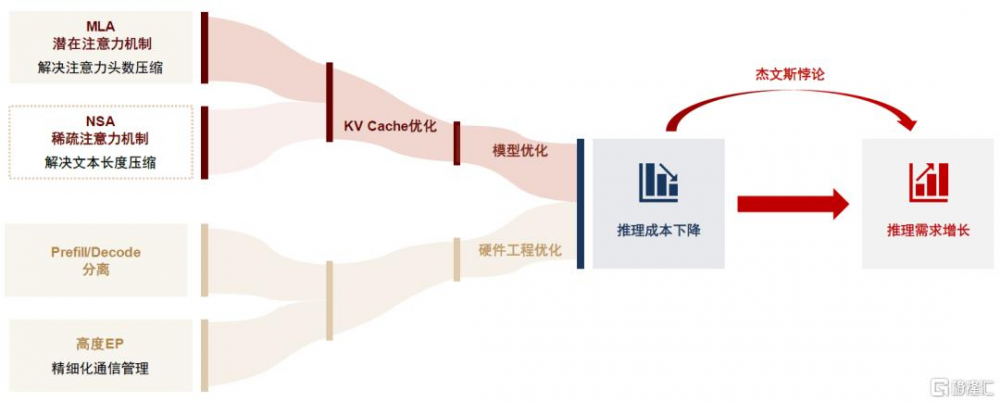
資料來源:DeepSeek V3技術報告,中金公司研究部
2月中旬,微信[5]开啓灰度測試接入DeepSeek事件引發了市場的廣泛關注。由於在EP=320高度並行狀態下模型對顯存佔用空間較小(僅671GB/320=2GB)左右,且激活值在計算過程中被層層丟棄,我們將顯存近似視爲全部分配給KV Cache。在一定的基本假設框架下(見圖17),我們測算出接入微信這類日活用戶數達10億級別APP所需要的NVIDIA Hopper GPU增量爲40萬左右,是較大體量的需求拉動。
圖表18:典型DeepSeek模型在10億日活數APP上部署對GPU的需求量及單token成本測算
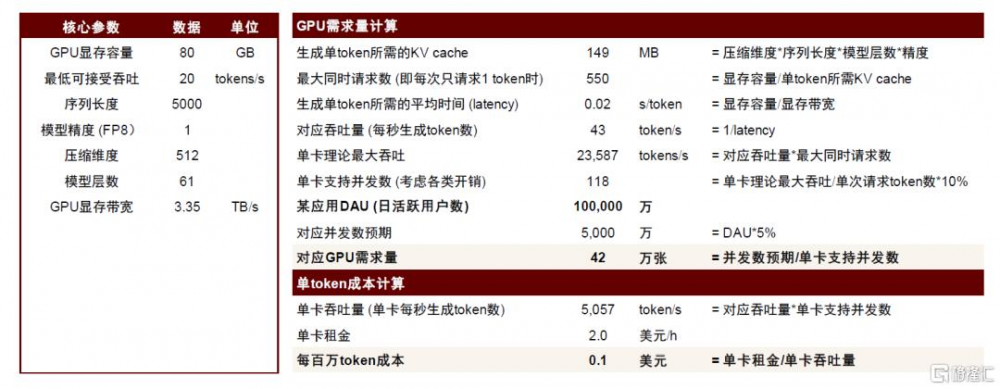
注:此表中GPU需求量爲NVIDIA Hopper系列GPU等效需求;單卡支持並發數計算中乘以10%是考慮到有其他开銷,實際並發數在理論並發數上有所折扣; 資料來源:DeepSeek-V3技術報告,中金公司研究部
國產算力的機會:從芯片到整機,全產業鏈加速適配DeepSeek
國產算力產業鏈全方位適配DeepSeek。1)芯片端,國產主流GPU廠商均已宣布適配DeepSeek,並結合AI infra廠商的算法優化,提供性能較優的推理體驗。例如2月1日硅基流動[6]宣布與昇騰雲合作推出DeepSeek R1/V3推理服務,據官方稱在自研推理加速引擎賦能下可實現持平全球高端GPU部署模型的推理效果。2)整機端,多款一體機產品密集推出,滿足下遊對數據安全、數據隱私的需要。例如聯想[7]基於沐曦N260,其Qwen2.5-14B的推理性能達英偉達L20的110-130%,支持DeepSeek各參數蒸餾模型的本地部署。3)IDC端,華爲雲、天翼雲、騰訊雲、阿裏雲、火山引擎等龍頭雲計算廠商均已上线DeepSeek,供下遊個人及政企單位調用,例如騰訊在元寶、微信中接入DeepSeek。
根據芯東西統計,2025年2月1日-14日短短兩周時間內,即有24家國產AI芯片企業、6家國產GPU企業、6家國產操作系統企業、86家國產服務器或一體機廠商以及82家中國雲計算廠商及AI基礎設施廠商,去重合計超過160家國產算力產業鏈企業宣布完成DeepSeek適配。我們認爲,國產企業全方位適配DeepSeek有望加速AI應用側的落地,反過來亦有望驅動AI本土產業鏈性能的升級共榮。
圖表19:國產算力硬件產業鏈已全面適配DeepSeek大模型(不完全統計)
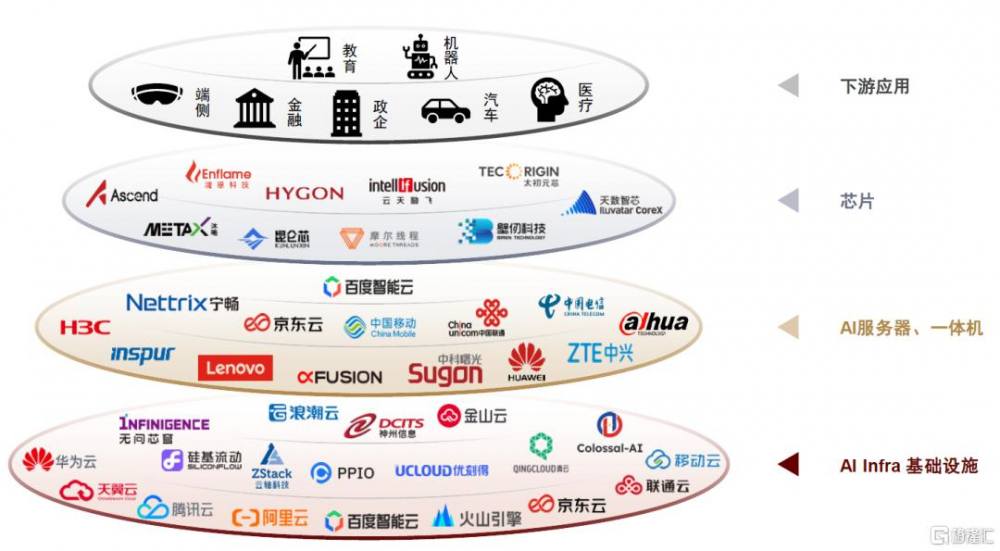
資料來源:公司公告,芯東西,中金公司研究部
圖表20:配套國產芯片的服務器整機針對DeepSeek不同版本模型適配情況
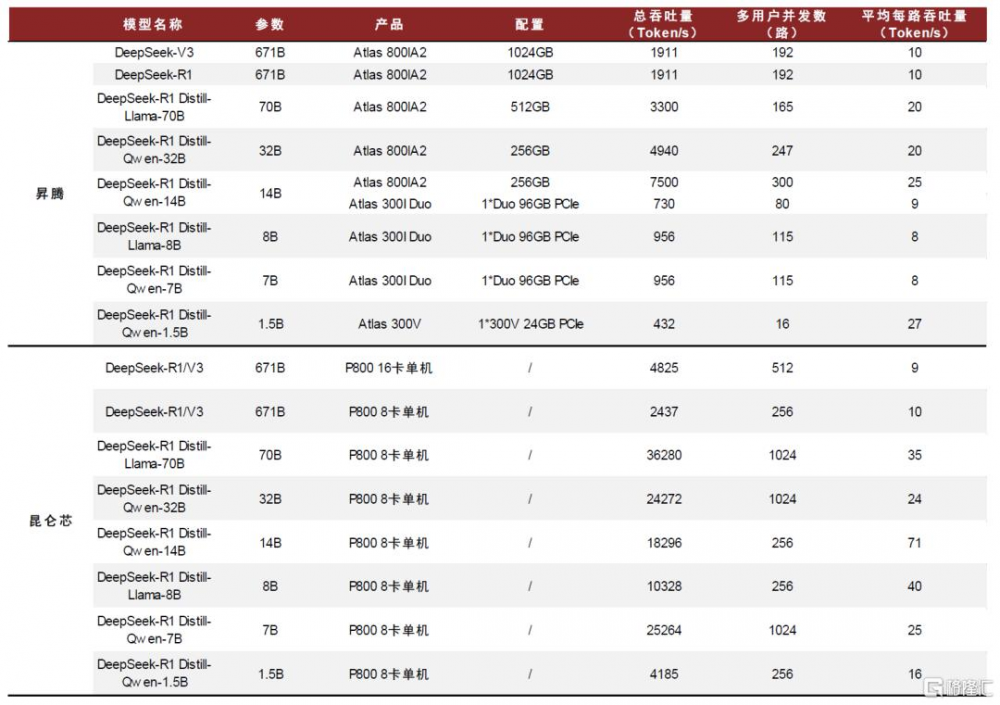
資料來源:昇騰开發者官網,昆侖芯官網,中金公司研究部
風險
► 生成式AI模型創新不及預期。本次DeepSeek模型獲得業內廣泛關注的核心原因之一在於大量細節上的算法創新以及硬件工程創新。如果生成式AI模型技術創新停滯,將直接影響技術迭代與產業升級進程。
► AI算力硬件技術迭代不及預期。GPU的算力水平以及網絡通信的傳輸速率均有可能成爲AI大模型訓練與推理的瓶頸,如果GPU算力及網絡通信的瓶頸持續擴大,或會拖慢生成式AI進化迭代的速度。
► AI應用落地進展不及預期。AI大模型訓練成本與推理成本較高,當前各互聯網大廠紛紛加大資本开支以支撐對AI大模型的研究。但是如果遲遲沒有現象級AI應用出現,當前的AI支出則無法變現,影響互聯網大廠進一步投入的意愿。
本文摘自:2025年2月27日已經發布的《AI進化論(2):模型+工程創新持續喚醒算力,DeepSeek撬動推理需求藍海》
成喬升 分析員 SAC 執證編號:S0080521060004
彭虎 分析員 SAC 執證編號:S0080521020001 SFC CE Ref:BRE806
賈順鶴 分析員 SAC 執證編號:S0080522060002
陳昊 分析員 SAC 執證編號:S0080520120009 SFC CE Ref:BQS925
李詩雯 分析員 SAC 執證編號:S0080521070008 SFC CE Ref:BRG963
孔楊 分析員 SAC 執證編號:S0080524100002
標題:模型+工程創新,DS給硬件市場帶來哪些變化?
地址:https://www.iknowplus.com/post/197617.html







