事關CUDA兼容,英偉達禁止了?
其實自 2021 年以來,Nvidia 就已經在其在线列出的許可條款中禁止使用翻譯層(translation layers)在其他硬件平台上運行基於 CUDA 的軟件,但之前的警告並未包含在安裝過程中放置在主機系統上的文檔。
但據報道,最近,這個描述已添加到安裝 CUDA 11.6 及更高版本時包含的 EULA 中。該限制似乎旨在阻止英特爾和 AMD 最近參與的ZLUDA等計劃,或許更關鍵的是,一些中國 GPU 制造商利用帶有翻譯層的 CUDA 代碼。
軟件工程師Longhorn注意到了這些術語。安裝的 EULA 文本文件中的一個條款寫道:“您不得對使用 SDK 元素生成的輸出的任何部分進行逆向工程、反編譯或反匯編,以將此類輸出工件轉換爲目標非 NVIDIA 平台。” (You may not reverse engineer, decompile or disassemble any portion of the output generated using SDK elements for the purpose of translating such output artifacts to target a non-NVIDIA platform.,")
與 CUDA 11.4 和 11.5 版本一起安裝的 EULA 文檔中不存在該條款,並且可能包含該版本之前的所有版本。但是,它存在於 11.6 及更高版本的安裝文檔中。
作爲一個領導者,這有好的一面,也有壞的一面。一方面,每個人都依賴你;另一方面,每個人都想站在你的肩膀上。後者顯然是 CUDA 所發生的情況。由於 CUDA 和 Nvidia 硬件的組合已被證明非常高效,因此大量程序都依賴它。
然而,隨着更多有競爭力的硬件進入市場,更多的用戶傾向於在競爭平台上運行他們的 CUDA 程序。有兩種方法可以做到這一點:重新編譯代碼(可供各個程序的开發人員使用)或使用翻譯層。
出於顯而易見的原因,使用ZLUDA 這樣的轉換層是在非 Nvidia 硬件上運行 CUDA 程序的最簡單方法。我們所要做的就是獲取已編譯的二進制文件並使用 ZLUDA 或其他轉換層運行它們。
但ZLUDA 現在似乎陷入困境,AMD 和英特爾都放棄了進一步开發它的機會,但這並不意味着翻譯不可行。
出於顯而易見的原因,使用轉換層威脅到了 Nvidia 在加速計算領域的霸權,特別是在人工智能應用方面。這可能是 Nvidia 決定禁止使用翻譯層在其他硬件平台上運行 CUDA 應用程序的推動力。
重新編譯現有的 CUDA 程序仍然完全合法。爲了簡化這一點,AMD 和 Intel 都有工具分別將 CUDA 程序移植到他們的 ROCm和 OpenAPI平台。
隨着 AMD、英特爾、Tenstorrent 和其他公司开發出更好的硬件,更多的軟件开發人員將傾向於爲這些平台進行設計,而 Nvidia 的 CUDA 主導地位可能會隨着時間的推移而減弱。
此外,專門爲特定處理器开發和編譯的程序將不可避免地比通過翻譯層運行的軟件運行得更好,這意味着 AMD、英特爾、Tenstorrent 和其他公司能夠在與 Nvidia 的競爭中獲得更好的競爭地位——如果他們能夠吸引軟件开發人員加入的話。
GPGPU仍然是一個重要且競爭激烈的競技場,我們將密切關注未來事態的進展。
ZLUDA,一個有雄心的項目
早在2020年,一個名爲ZLUDA的項目被描述爲“英特爾 GPU 上 CUDA 的直接替代品”,它正在威脅 Nvidia 專有的 CUDA(統一計算設備架構)生態系統。
該獨立項目(並非由AMD或Intel推動)當時已經提供了在非 Nvidia 顯卡上運行未更改的 CUDA 應用程序的概念證明。
ZLUDA 的基礎正是英特爾的oneAPI Level Zero規範。這是一個私人項目,與英特爾或英偉達沒有任何關系。在剛發起的時候,ZLUDA 仍處於早期階段,缺乏完整的 CUDA 支持。因此,許多 CUDA 應用程序無法與 ZLUDA 一起使用。
但ZLUDA 的創建者當時聲稱,它提供了“接近原生”的性能,暗示幾乎沒有性能損失。他提供了Intel Core i7-8700K的 GeekBench 5.2.3 結果,該處理器配備 Intel 的 UHD Graphics 630 iGPU,並運行 OpenCL 和 ZLUDA。對於後者,作者欺騙 GeekBench 認爲 Intel iGPU 是速度較慢的 Nvidia GPU。然而,結果來自相同的 iGPU。
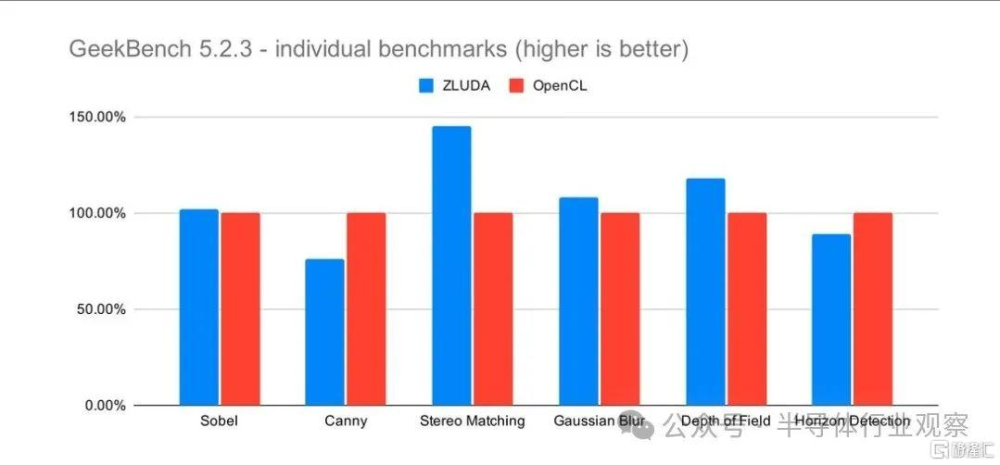
結果表明,與 OpenCL 性能相比,ZLUDA 的性能提高了 10%。總體而言,我們預計較基准組提高 4%左右。
作者明確表示,ZLUDA 與 AMD HIP 或 Intel DPC++ 完全不同,因爲後兩者是程序員將應用程序移植到所選特定 API 的工具。另一方面,ZLUDA 不需要任何額外的工作,因爲 CUDA 應用程序只需在 Intel GPU 上運行。當然,只要支持 CUDA 子集即可。
經過幾年的發展,該項目同樣支持了AMD的GPU。據了解,今天的 ZLUDA 與 2020 年的版本有很大不同。它不是基於英特爾的 oneAPI 構建並包括對該公司 GPU 的支持,而是基於 AMD 的競爭 ROCm 解決方案,並且僅支持 Radeon GPU。目前還不完全清楚爲什么英特爾的支持被取消,但這可能與 ZLUDA 2020 版本僅支持 Xe 之前的集成顯卡有關。當 Arc Alchemist GPU 於 2022 年問世時,項目开發者Janik 已與 AMD 合作。开發人員也表示 ,ZLUDA“僅可能收到運行我個人感興趣的工作負載 (DLSS) 的更新”,這意味着該項目或多或少已經完成。Janik 的最終目標似乎是獲得英特爾或 AMD 的支持。
但進入今年二月中,有消息指出,該項目似乎不會進行進一步的工作,至少不會進行重大更新,ZLUDA 开發人員 Andrzej Janik(代號 vosen)表示,隨着這兩家公司(Intel和AMD)退出,他表示“我們已經沒有 GPU 公司了”。
“實際上,該項目現在已經被放棄了。”Janik說。
由此可見,英特爾和 AMD 對讓其 GPU 與現有 CUDA 生態系統兼容不感興趣,這一點很能說明問題。看起來他們更愿意與帶有 oneAPI 和 ROCm 的 CUDA 正面交鋒,它們更新且开發程度較低,但擁有开源的好處。
迄今爲止,CUDA 仍然是專業和數據中心圖形軟件中更流行的解決方案,目前尚不清楚這種情況是否會很快改變,特別是如果 Nvidia 的 GPU 在功能和性能方面繼續領先英特爾和 AMD 的話。
打破CUDA霸權?
關於CUDA霸權這個論調,已經不是什么新鮮事了。
例如英特爾首席執行官帕特·基辛格 (Pat Gelsinger)在去年年底於紐約舉行的一次活動中首先對 Nvidia 的 CUDA 技術大加贊賞,並聲稱推理技術將比人工智能訓練更重要。但在接受提問時,基辛格表示 Nvidia 在訓練方面的 CUDA 主導地位不會永遠持續下去。
他同時說道,“你知道,整個行業都在積極消除 CUDA 市場,”基辛格說。他列舉了 MLIR、 Google和 OpenAI等例子,暗示他們正在轉向“Pythonic 編程層”,以使 AI 訓練更加开放。
英特爾 CTO Greg Lavender在2023年9月的一個演講中更是毫不掩飾地打趣道:“我將向所有开發人員提出一個挑战。讓我們使用大模型和 Copilot 等技術來訓練機器學習模型,將所有 CUDA 代碼轉換爲 SYCL。”(原文:I'll just throw out a challenge to all the developers. Let's use LLMs and technologies like Copilot to train a machine learning model to convert all your CUDA code to SYCL)。
其中的SYCL 就是英特爾爲打破 CUDA 對 AI 軟件生態系統束縛做得的最新舉措。據介紹,SYCL(或更具體地說 SYCLomatic)是一個免版稅的跨架構抽象層,爲英特爾的並行 C++ 編程語言提供支持。簡而言之,在將 CUDA 代碼移植爲可在非 Nvidia 加速器上運行的過程中,SYCL 處理大部分繁重工作(據稱高達 95%)。但正如您所期望的那樣,通常需要進行一些微調和調整才能使應用程序全速運行。
當然,,SYCL 絕不是編寫與加速器無關的代碼的唯一方法。如Curley 所說,OpenAI 的 Triton 或 Google 的 Jax 等框架就是其中兩個例子。
AMD CEO Lisa Su在接受採訪談到英偉達CUDA是表示,不相信護城河。她直言,像 PyTorch 這樣的東西往往具有與硬件無關的功能。她同時指出,這意味着現在在 PyTorch 上運行 CUDA 的任何人都可以在 AMD 上運行,因爲我們已經在那裏完成了工作。坦率地說,它也可以在其他硬件上運行。
在去年的Advancing AI 大會上,AMD總裁Victor Peng就介紹了並行計算框架的最新版本ROCm 6,該框架專門針對 AMD Instinct 的綜合軟件堆棧進行了優化,特別適合生成 AI 中的大型語言模型。
專注於微調大型語言模型的初創公司 Lamini 則透露,它已經“祕密地在 100 多個AMD Instinct MI200 系列 GPU 上運行,並表示該芯片設計商的 ROCm 軟件平台“已經實現了與 Nvidia 針對此類模型的主導 CUDA 平台的軟件對等(software parity)。
曾從事 x86、Arm、MISC 和 RISC-V 處理器研究的傳奇處理器架構師Jim Keller早前也批評了Nvidia 的 CUDA架構和軟件堆棧,並將其比作 x86,他稱之爲沼澤。他指出,就連英偉達本身也有多個專用軟件包,出於性能原因,這些軟件包依賴於开源框架。
keller在後續帖子中寫道。“如果你確實編寫 CUDA,它可能不會很快。[...] Triton、Tensor RT、Neon 和 Mojo 的存在是有充分理由的。”
即使在Nvidia 本身,也有不完全依賴 CUDA 的工具。例如,Triton Inference Server 是 Nvidia 的一款开源工具,可簡化 AI 模型的大規模部署,支持 TensorFlow、PyTorch 和 ONNX 等框架。Triton 還提供模型版本控制、多模型服務和並發模型執行等功能,以優化 GPU 和 CPU 資源的利用率。
Semianalysis作者Dylan Patel之前在一篇文章中也強調,隨着 PyTorch 2.0 和 OpenAI Triton 的到來,英偉達在這一領域的主導地位正在被打破。
標題:事關CUDA兼容,英偉達禁止了?
地址:https://www.iknowplus.com/post/86734.html







