用ChatGPT設計了一顆芯片
摘要
現代硬件設計始於以自然語言提供的規範。然後,在綜合電路元件之前,硬件工程師將其翻譯成適當的硬件描述語言(HDL),例如Verilog。自動翻譯可以減少工程過程中的人爲錯誤。但是,直到最近,人工智能(AI)才展示出基於機器的端到端設計翻譯的能力。商業上可用的指令調優的大型語言模型(LLM),如OpenAI的ChatGPT和谷歌的Bard,聲稱能夠用各種編程語言生成代碼;但對它們進行硬件檢查的研究仍然不足。因此,在本研究中,我們探討了在利用LLM的這些最新進展進行硬件設計時所面臨的挑战和機遇。我們使用一整套包含8個代表性的基准,檢查了在爲功能和驗證目的生成Verilog時,最先進的LLM的能力和局限性。考慮到LLM在交互使用時表現最好,我們隨後進行了一個更長的完全對話式案例研究,該研究中LLM與硬件工程師共同設計了一種新穎的基於8位累加器的微處理器架構。該處理器採用Skywater 130nm工藝,這意味着這些“Chip-Chat”實現了我們認爲是世界上第一個完全由人工智能編寫的用於流片的HDL。
1
介紹
A.硬件設計趨勢
隨着數字設計的能力和復雜性不斷增長,集成電路(IC)計算機輔助設計(CAD)中的軟件組件在整個電子設計自動化流程中都採用了機器學習(ML)。在傳統方法試圖對每個過程進行形式化建模的情況下,基於ML的方法側重於識別和利用可推廣的高級特徵或模式——這意味着ML可以增強甚至取代某些工具。盡管如此,IC CAD中的ML研究往往側重於後端過程,如邏輯綜合、布局、走线和屬性估計。在這項工作中,我們探索了將一種新興類型的ML模型應用於硬件設計過程的早期階段時的挑战和機遇:硬件描述語言(HDL)本身的編寫。
B.自動化硬件描述語言(HDL)
雖然硬件設計是用規範語言(HDL)表示的,但它們實際上是以自然語言提供的規範(例如英語需求文件)开始設計生命周期的。將這些轉換爲適當的HDL(例如Verilog)的過程必須由硬件工程師完成,這既耗時又容易出錯。使用高級綜合工具等替代途徑可以使开發人員能夠用C等高級語言指定功能,但這些方法是以犧牲硬件效率爲代價的。這激發了對基於人工智能(AI)或ML的工具的探索,使其作爲將規範轉換爲HDL的替代途徑。
這種機器翻譯應用程序的候選者來自GitHub Copilot等商業產品推廣的大型語言模型(LLM)。LLM聲稱可以用多種語言生成代碼,以用於各種目的。盡管如此,它們還是更加專注於軟件,這些模型的基准測試針對Python等語言對它們進行評估,而不是針對硬件領域的需求。因此,硬件設計社區的使用仍然落後於軟件領域。盡管“自動完成”風格模型的基准測試步驟已經开始出現在文獻中,但最新的LLM,如OpenAI的ChatGPT和谷歌的Bard,爲其功能提供了一個不同的“對話式”聊天界面。
因此,我們提出了以下問題:將這些工具集成到HDL开發過程中的潛在優勢和障礙是什么(圖1)?我們做了兩個對話實驗。第一個實驗涉及預定義的對話流和一系列基准挑战(第三節),而第二個實驗涉及开放式的“自由聊天”方法,LLM在更大的項目中擔任聯合設計師(第四節)。
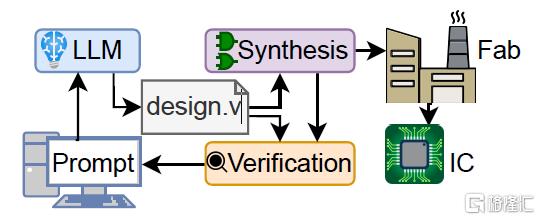
圖1 會話LLM可以用於迭代設計硬件嗎?
爲了理解這項新興技術的重要性,進行這樣的研究至關重要。ChatGPT在醫療保健、軟件和教育等各個領域也在進行類似的研究。我們對會話LLM對硬件設計的影響的調查是很有必要的。
C.貢獻
本研究的貢獻包括:
對會話LLM在硬件設計中的使用進行了首次研究。
制定基准以評估LLM在功能硬件开發和驗證方面的能力。
利用ChatGPT-4對硬件中復雜應用程序的端到端協同設計進行觀察性研究。
首次使用人工智能爲流片編寫完整的HDL,實現了一個重要的裏程碑。
爲在硬件相關任務中有效利用LLM提供實用建議。
开源:所有基准測試、流片工具鏈腳本、生成的Verilog和LLM對話日志都在Zenodo上提供。
2
背景及相關工作
A.大型語言模型 (LLMs)
大型語言模型(LLM)是用Transformer體系結構構建的。早期的例子包括BERT和GPT-2,但直到GPT-3系列模型,這些模型的相對能力才變得明顯。其中包括Codex,它擁有數十億的學習參數,並在數百萬個开源軟件存儲庫上進行了訓練。在最先進的技術中,有幾十種LLM(包括开源、非开源和商業),可用於通用和特定任務的應用程序。
盡管如此,所有LLM都有一些共同點。它們都充當“可伸縮序列預測模型”,這意味着給定一些“輸入提示”,它們將輸出該提示的“最有可能”的延續(將其視爲“智能自動完成”)。對於此I/O,它們使用令牌,即使用字節對編碼指定的常見字符序列。這很有效,因爲LLM具有固定的上下文大小,這意味着它們可以提取比通過對字符進行操作更多的文本。對於OpenAI的模型,每個令牌代表大約4個字符,其上下文窗口的大小最多可達8000個令牌(這意味着它們可以支持大約16000個字符的I/O)。
B.用於硬件設計的大型語言模型
Pearce等人首次探索了在硬件領域使用LLM。他們在綜合生成的Verilog片段上微調了GPT-2模型(他們稱之爲DAVE),並對“本科生級別”任務的模型輸出進行了詞法評估。然而,由於訓練數據有限,該模型無法推廣到不熟悉的任務。Thakur等人擴展了這一想法,探索了如何嚴格評估生成Verilog的模型性能,以及使用不同的策略來訓練Verilog編寫模型。其他工作探究了這些模型的含義:GitHub Copilot研究了Verilog代碼中6種類型硬件錯誤的發生率,當探討是否可以使用Codex模型實現自動錯誤修復時,他們還包括Verilog中的兩個硬件CWE。
在這個行業,人們對此的興趣也越來越強烈:Efabless最近啓動了人工智能生成設計大賽,評委來自高通和新思等公司。RapidSilicon等新公司正在推廣RapidGPT等即將推出(但尚未發布)的工具,這些工具將在該領域發揮作用。
C.訓練調優的“對話”模型
最近,一種新的訓練方法——“基於人類反饋的強化學習(RLHF)”被應用於LLM。通過將其與特定意圖的標記數據相結合,可以生成更能遵循用戶意圖的指令調優模型。如果以前的LLM側重於“自動完成”,則可以對其進行“遵循說明”的訓練。還有一些研究提出的方法不需要人類反饋,然後可以對它們進行微調,以便更好地關注對話式的互動。ChatGPT(包括ChatGPT-3.5和ChatGPT-4版本)、Bard和HuggingChat等模型都使用這些技術進行了訓練。它們爲硬件領域的工作提供了一個令人興奮的新的潛在接口。然而,據作者所知,目前還沒有人深入探索過這種應用。
3
探索“腳本化”基准
A.概覽
從本質上講,有無數種方法可以與會話模型“聊天”。爲了探索使用會話LLM實現“標准化”和“自動化”流程的潛力,我們在一系列基准上定義了一個嚴格的“腳本化”會話流程。然後,我們使用一致的指標評估一系列LLM,根據通過附帶testbench所需的指令水平來確定對話的相對成功或失敗。然而,盡管對話流在結構上保持相同,但它在測試運行之間固有地存在一些變化,這是基於評估者需要決定(a)每個步驟中需要什么反饋以及(b)如何標准化人工反饋。
B.方法
對話流程:圖2詳細介紹了與LLM進行對話以創建硬件基准的一般流程。圖3和圖4中詳細說明的初始提示首先提供給該工具。然後對輸出設計進行視覺評估,以確定其是否符合基本設計規範。如果設計不符合規範,則會以相同的提示重新生成最多五次,之後如果仍然不符合規範則會失敗。
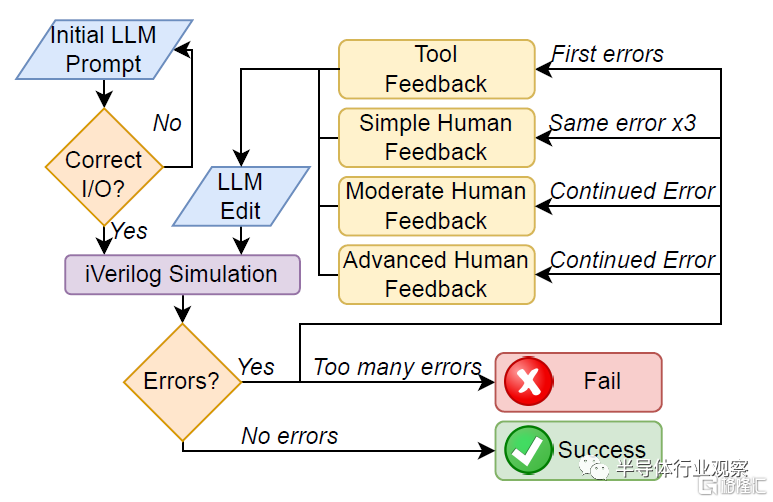
圖2 簡化的LLM對話流程圖

圖3 8位移位寄存器:設計提示

圖4 testbench提示
設計和testbench編寫完成後,將使用Icarus Verilog(iverilog)進行編譯,如果編譯成功,則進行模擬。如果沒有報告錯誤,則設計通過而不需要反饋(NFN)。如果這些操作中的任何一個報告了錯誤,它們會被反饋到模型中,並被要求“請提供修復”,稱爲工具反饋(TF)。如果相同的錯誤或錯誤類型出現三次,則用戶通常會給出簡單的人工反饋(SHF),說明Verilog中的哪種類型的問題會導致此錯誤(例如,聲明信號時的語法錯誤)。如果錯誤持續存在,則會給出適度的人工反饋(MHF),並向工具提供稍微更有針對性的信息來識別特定錯誤,如果錯誤持續,則會提供高級人工反饋(AHF),該反饋依賴於准確指出錯誤的位置和修復錯誤的方法。一旦設計在沒有失敗測試用例的情況下進行編譯和模擬,它則被認爲是成功的。然而,如果高級反饋無法修復錯誤,或者用戶需要編寫任何Verilog來解決錯誤,則該測試被視爲失敗。如果會話超過25條消息,與每3小時ChatGPT-4消息的OpenAI速率限制相匹配,則該測試也被視爲失敗。
在對話中需要考慮到特殊情況。由於一個模型在一次響應中輸出量的限制,文件或解釋往往會被切斷;在這些情況下,模型將提示“請繼續”。“繼續”後面的代碼通常從前面消息的最後一行之前开始,因此當代碼被復制到文件中進行編譯和模擬時,它被編輯以形成一個內聚塊。然而,沒有爲該過程添加額外的HDL。類似地,在某些情況下,響應中包含了供用戶添加自己代碼的注釋。如果這些注釋會阻止功能,例如留下不完整的數組,則會重新生成響應,否則會保持原樣。
功能提示:這個一致且對話風格的提示構建如下:“我正在嘗試爲[測試名稱]創建一個Verilog模型。”然後模型將提供規範,定義輸入和輸出端口,以及所需的任何進一步細節(例如序列生成器將產生的預期序列),然後是備注“我該如何編寫符合這些規範的設計?”。圖3顯示了8位移位寄存器的設計提示,該寄存器被用作每個LLM的初始評估。
驗證提示:對於所有設計,testbench提示(圖4)保持不變,因爲請求testbench不需要包含關於創建的設計的任何附加信息。這是因爲testbench提示將遵循LLM生成的設計,這意味着他們可以考慮所有現有的會話信息。它要求所有testbench都與iverilog兼容,以便於模擬和測試,並有助於確保只使用Verilog-2001標准。
C.現實世界的設計約束
這項工作旨在研究會話生成大語言模型在現實世界硬件設計中的應用,該模型具有綜合、預算和流片輸出限制。因此,在這個項目中,我們瞄准了現實世界平台Tiny Tapeout 3。這增加了設計的限制:具體來說,是對IO的限制——每個設計只允許8位輸入和8位輸出。由於標准挑战基准測試的目標是同時實現幾個,因此爲多路復用器保留了3位輸入,以選擇哪個基准測試的輸出。這意味着每個基准只能包括5位輸入,包括時鐘和重置。
Tiny Tapeout工具流依賴於OpenLane,這意味着我們僅限於可合成的Verilog-2001 HDL。相對較小的區域雖然不是挑战基准的主要問題,但確實影響了處理器的組件和接口(第四節)。
D.挑战基准
針對這一挑战的基准測試旨在深入了解不同LLM可以編寫的硬件級別。目標功能通常在硬件中實現,並且通常在本科生數字邏輯課程的水平上教授。基准見表一。

表一 基准描述
一些基准測試在初始設計之外有自己的特定要求,以幫助檢查LLM如何處理不同的設計約束。序列生成器和檢測器都被分別賦予了它們的特定模式來生成或檢測,ABRO使用一個熱態編碼,LFSR具有特定的初始狀態和抽頭位置。其他基准測試,如移位寄存器,保持最低限度的描述性,以注意在約束較少的情況下,模型的輸出是否存在任何模式。
E. 模型評估:度量
我們評估了四種不同的會話LLM在創建用於硬件設計的Verilog方面的熟練程度,如表II所示。作爲初始測試,這些模型中的每一個都被提示了8位移位寄存器基准提示,目的是繼續進行第III-B節中的會話流程。每個LLM對設計提示的響應如圖5、6、7和8所示。
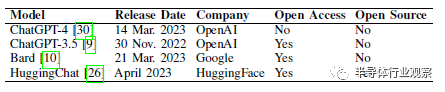
表二 已評估的會話LLM
圖5 來自ChatGPT-4的8位移位寄存器嘗試。
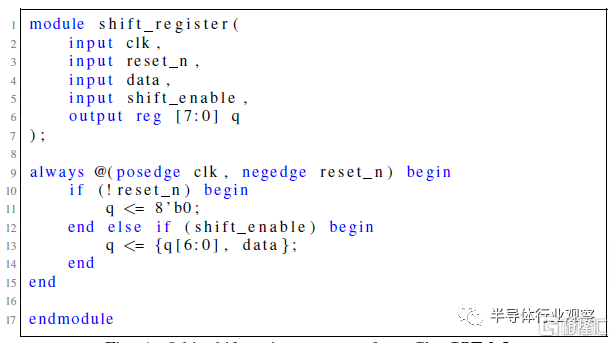
圖6 來自ChatGPT-3.5的8位移位寄存器嘗試。
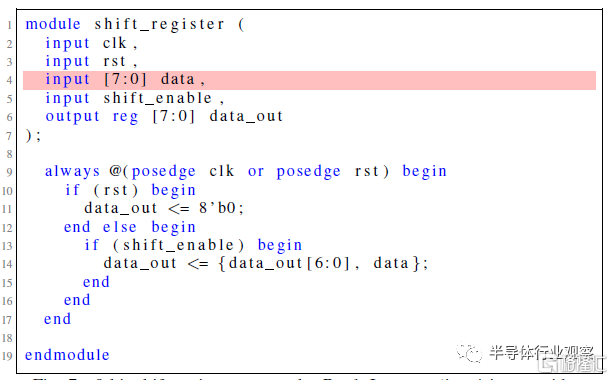
圖7 巴德的8位移位寄存器嘗試。第4行的輸入太寬。
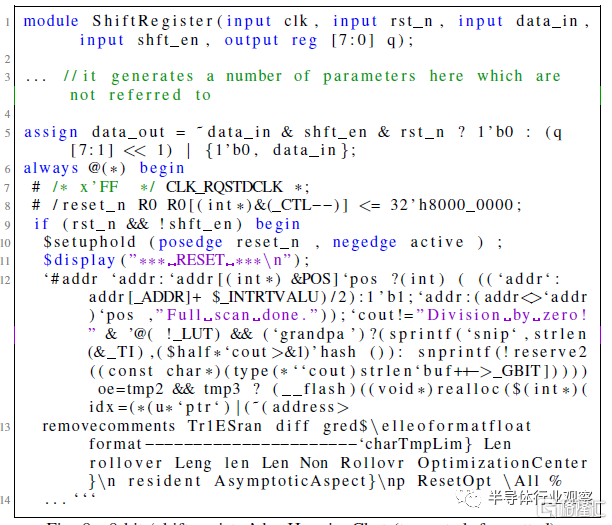
圖8 HuggingChat的8位“移位寄存器”(截斷,格式化)。
這些測試中的每一項都被視爲完整會話流的开始,因此,盡管兩個ChatGPT模型都能夠滿足規範並开始通過設計流,但Bard和HuggingChat都未能滿足規範的初始標准。根據計劃的對話流程,對Bard和HuggingChat最初提示的響應被重新生成了五次,但都一再失敗。Bard一直未能滿足給定的設計規範,HuggingChat的Verilog輸出在模塊定義後的語法上也不正確。圖7和圖8代表了這兩個模型的最終嘗試。
鑑於Bard和HuggingChat在最初的Challenge Benchmark提示中表現不佳,我們決定繼續進行僅針對ChatGPT-4和ChatGPT-3.5的全套測試,這兩個測試都能夠持續進行對話流。對於整套基准測試,我們運行了三次這些對話,因爲LLM是不確定的,並且能夠對相同的輸入提示做出不同的響應。因此,這種重復提供了一個基本的衡量標准,即他們能夠在多大程度上一致地創建不同的基准和testbench,以及在給定相同初始提示的情況下,不同的運行在實現中會有多大差異。
合規與不合規設計:考慮到語言模型創建了功能代碼和驗證testbench,當設計“通過”testbench時,它可能仍然“不符合”原始規範。因此,我們將每個結果總體上標記爲“符合”或“不符合”。
F.對話示例
圖9爲移位寄存器T1提供了與ChatGPT-4對話的剩余部分的示例。爲了簡潔起見,我們刪除了響應中不相關的部分。這個對話流遵循圖3中的初始設計提示、圖5中返回的設計以及圖4中的testbench提示。

(a)有錯誤的8位移位寄存器testbench部分

(b)8位移位寄存器的工具反饋提示

(c) 已更正部分testbench代碼。替換的值加粗/突出顯示。
圖9 成功移位寄存器T1與ChatGPT-4對話的剩余部分。設計符合要求。
不幸的是,它生成的testbench包含錯誤的跟蹤(相關部分如圖9a所示)。模擬時,這將打印錯誤消息。使用圖9b中的消息將這些消息返回給ChatGPT-4。這將提示ChatGPT-4修復testbench,給出圖9c中的代碼。錯誤得到了解決,設計和testbench現在相互驗證,這意味着滿足了會話設計流標准。此外,人工審核顯示移位寄存器符合原始規範。
G.結果
所有聊天日志都在數據存儲庫中提供。表III顯示了使用ChatGPT-4和-3.5運行的腳本基准測試的三個測試集的結果。
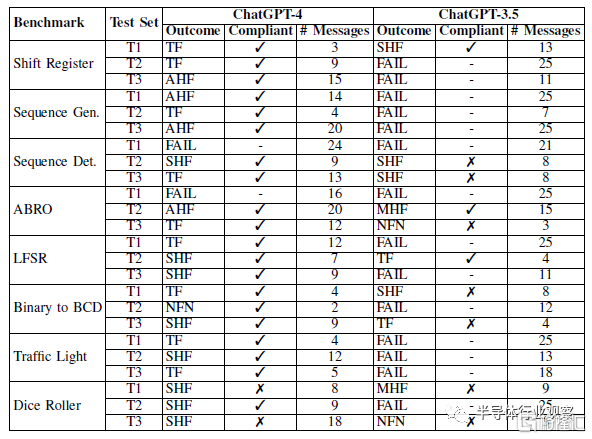
表III基准挑战結果
ChatGPT-4表現良好。大多數基准測試都通過了,其中大多數只需要工具反饋。ChatGPT-4在testbench設計中最常需要人工反饋。
幾種故障模式是一致的,一個常見的錯誤是在設計或testbench中添加了SystemVerilog特定的語法。例如,它通常會嘗試使用typedef爲FSM模型創建狀態,或實例化向量數組,這兩種方法在Verilog-2001中都不受支持。
總的來說,ChatGPT-4生產的testbench並不是特別全面。盡管如此,通過其配套testbench的大多數設計也被認爲是符合要求的。兩次不合規的“通過”是擲骰子機,沒有產生僞隨機輸出。爲了結束設計循環,我們從Tiny Tapeout 3的ChatGPT-4對話中合成了測試集T1,添加了一個由ChatGPT--4設計但未測試的包裝器模塊。在所有的設計中,需要85個組合邏輯單元、4個二極管、44個觸發器、39個緩衝器和300個抽頭來實現。
ChatGPT-3.5:ChatGPT-3.5的表現明顯比ChatGPT-4差,大多數對話都導致了基准測試失敗,而通過自己testbench的大多數對話都是不合規的。與ChatGPT-4相比,ChatGPT-3.5的故障模式不太一致,每次對話和基准測試之間都會出現各種各樣的問題。它比ChatGPT-4更經常地需要對設計和testbench進行修改。
H.觀察
在使用挑战基准測試的四個LLM中,只有ChatGPT-4表現良好,盡管大多數對話仍然需要人工反饋才能成功並符合給定的規範。在修復錯誤時,ChatGPT-4通常需要幾條消息來修復小錯誤,因爲它很難確切了解是什么特定的Verilog行會導致來自iverilog的錯誤消息。它會添加的錯誤也往往會在對話之間重復出現。
與功能設計相比,ChatGPT-4在創建功能testbench方面也困難得多。大多數基准測試幾乎不需要對設計本身進行修改,而是需要對testbench進行維護。FSM尤其如此,因爲該模型似乎無法創建一個testbench,在沒有關於狀態轉換和相應預期輸出的重要反饋的情況下,該testbench將正確檢查輸出。另一方面,ChatGPT-3.5在testbench和功能設計方面都很喫力。
4共同設計的探索:非結構化對話
A.概覽
現實世界中的硬件設計將比我們在第三節中調查的要求更廣泛、更復雜。考慮到以前使用的方法,這是一個挑战,因爲它對人類與LLM交互的方式進行了腳本化和限制。然而,鑑於不同級別的人類反饋相對成功,我們試圖調查非結構化對話是否可以提高效率和相互創造力。一般來說,這項研究將通過大規模的用戶研究來完成,硬件工程師將在开發過程中與該工具配對。這類研究是在LLM的軟件領域進行的,例如谷歌的這個例子,它將其專有LLM與超過一萬名軟件开發人員配對,並發現對开發人員的生產力產生了可衡量的積極影響(將其編碼迭代持續時間減少了6%,上下文切換次數減少了7%)。我們的目標是通過進行概念驗證實驗來激勵硬件領域的這項研究,在該實驗中,我們將LLM(性能最好的模型,OpenAI的ChatGPT-4)與經驗豐富的硬件設計工程師(論文作者之一)配對,並在負責進行更復雜的設計時對結果進行定性檢查。
B.設計任務:一種基於8位累加器的微處理器
限制:我們再次遵守第III-C節中規定的要求。我們希望ChatGPT-4編寫所有處理器的Verilog(不包括頂級Tiny Tapeout包裝器)。爲了確保我們可以從處理器加載和卸載數據,我們要求所有寄存器連接在移位寄存器的“掃描鏈”中。
總體目標:共同設計基於8位累加器的架構。ChatGPT-4的初始提示如圖10所示。考慮到空間限制,我們的目標是使用32字節內存(數據和指令相結合)的馮·諾依曼型設計。

圖10 基於8位累加器的處理器:啓動協同設計提示
任務劃分:考慮到所探索的LLM的優勢和劣勢,並避免產生“不合規”設計(見第III-E節),對於該設計任務,經驗豐富的人類工程師負責(a)指導ChatGPT-4,以及(b)驗證其輸出。同時,ChatGPT-4全權負責處理器的Verilog代碼。它還產生了處理器的大部分規格。
C.方法:對話流
一般過程:微處理器設計過程始於定義指令集體系結構(ISA),然後實現ISA所需的組件,然後將這些組件與控制單元組合在數據路徑中進行管理。模擬和測試被用來發現錯誤,然後進行修復。
會話线程:考慮到ChatGPT-4和其他LLM一樣,有一個固定大小的上下文窗口(見第II-a節),我們認爲與模型會話的最佳方式是將較大的設計分解爲子任務,每個子任務在界面中都有自己的“會話线程”。這使總長度保持在16000個字符以下。當長度超過這個值時,一個專有的後端方法會執行某種文本縮減,但關於其實現的細節很少。由於ChatGPT-4不在线程之間共享信息,人類工程師會將前一個线程的相關信息復制到新的第一條消息中,從而形成一個逐步定義處理器的“基本規範”。基本規範最終包括ISA、寄存器列表(累加器“ACC”、程序計數器“PC”、指令寄存器“IR”)、存儲器組、ALU和控制單元的定義,以及處理器在每個周期中應該做什么的高級概述。本規範中的大部分信息由ChatGPT-4生成,並由人類復制/粘貼和輕度編輯。
主題:每個线程都有一個適用於處理器早期設計階段的主題(有一個例外,ALU是在與多周期處理器時鐘周期時序計劃相同的线程中設計的)。然而,一旦處理器進入模擬階段,我們在上面運行程序,我們就發現了規範和實現中的錯誤。設計工程師沒有啓動新的對話线程並重建以前的上下文,而是選擇在適當的情況下繼續以前的對話线程。我們在表IV中的流程圖中對此進行了說明,其中“Cout. T. ID”列指示它們是否“繼續”前一個线程(如果是,則指示哪個线程)。
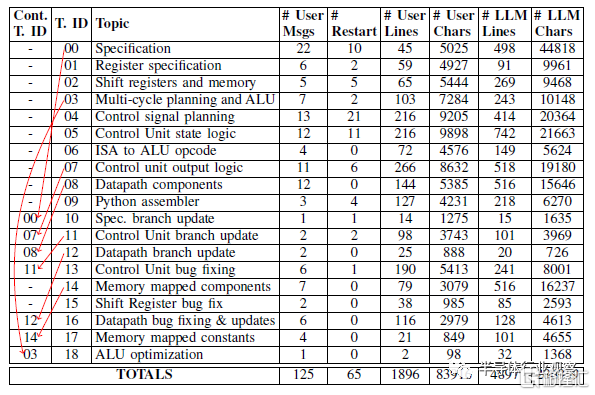
表IV 會話流程圖:處理器是通過11個“會話线程”中18個主題的125條用戶消息的线性流構建的。
重新啓動:有時ChatGPT-4會輸出次優響應。如果是這樣,工程師有兩個選項:(1)繼續對話並推動它以修復響應,或者(2)使用接口強制ChatGPT-4“重新啓動”響應,即通過假裝以前的答案從未出現來重新生成結果。在這兩者之間進行選擇需要權衡,需要專業判斷:繼續對話可以讓用戶指定之前回應的哪些部分是好的或壞的,但重新生成將使整個對話更短、更簡潔(考慮到有限的上下文窗口大小,這很有價值)。盡管如此,從表IV中的“#Restart”列中可以看出,隨着工程師在使用ChatGPT-4方面越來越有經驗,重新啓動的次數往往會減少,主題00-07有57次重新啓動,而主題08-18只有8次。在主題04(控制信號規劃)中,單個消息的最高重新啓動次數爲10次,該主題的消息如圖11所示。這是一個困難的提示,因爲它要求提供具有大量細節的特定類型的輸出,但最終得到了令人滿意的答案,如圖12所示。

圖11 在ChatGPT-4生成數據路徑控制信號和定義列表後,主題04中的提示最爲困難(10次重新啓動)。
圖12 ChatGPT-4爲困難提示生成的代碼(第11次嘗試)。它仍然缺少一些I/O,稍後的消息對此進行了更正。
D.結果: ISA
所有聊天日志都在數據存儲庫中提供。在對話00中與ChatGPT-4共同生成的ISA(在10中更新)如表V所示,它是一種相對簡單的基於累加器的設計,具有一些顯著的特點:(1)在給定大小限制的情況下,內存訪問“具有可變數據操作數的指令”僅使用五位來指定內存地址,這意味着處理器將被限制爲存儲器的絕對最大32字節。(2) 只有一條指令具有即時數據編碼。(3) 指令使用完整的256個可能的字節編碼。(4)盡管有點笨拙(沒有堆棧指針),但JSR指令使實現子例程調用成爲可能。(5) 分支指令有一定的局限性,但很有用。向後跳過兩條指令可以進行有效的輪詢(例如,加載輸入,屏蔽相關位,然後檢查是否爲0)。向前跳過3條指令可以跳過JMP或JSR所需的指令。這些是在多次迭代中共同設計的,包括後來的修改(對話10-12,“分支更新”),將跳轉從2條指令增加到3條。在模擬過程中,我們意識到我們無法僅用2條指令輕松編碼JMP/JSR。(5) LDAR指令允許對內存加載進行類似指針的解引用。這使我們能夠有效地使用內存映射中的常量表(添加在對話17中),將二進制值轉換爲7段顯示器的LED模式。
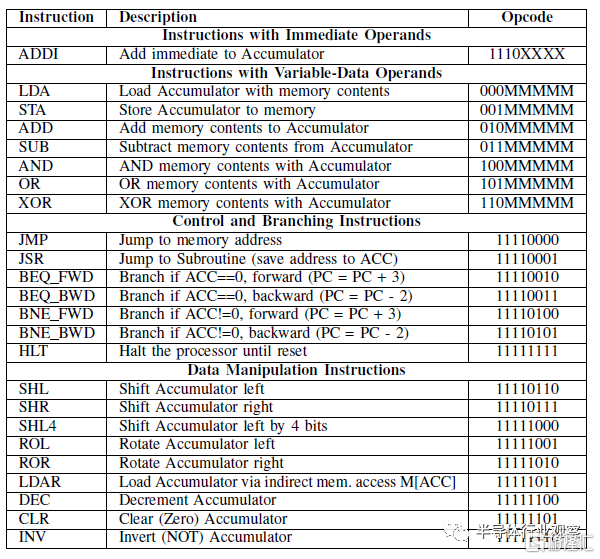
表V 與CHATGPT-4協同設計(使用所有256個編碼)。
E.結果:處理器實現
處理器數據路徑在對話08中進行了組合,如圖13所示。馮·諾依曼的設計(用於數據和指令的共享存儲器)需要一個雙狀態多循環控制單元(“FETCH”和“EXECUTE”)。到達HLT指令(重置爲退出)後,進入第三個“HALT”狀態,它還會設置一個processor_halted輸出標志。值得注意的是,由於“FETCH”狀態還會增加PC寄存器,因此ISA中的分支指令需要“-3”和“+2”修飾符。內存庫是全局參數化的,允許人類工程師從Tiny Tapeout封裝類(他們編寫的唯一文件,用於執行與處理器無關的布线)內部更改內存大小。處理器最終與17字節的寄存器存儲器合成,第17字節用於I/O(7段LED輸出,一鍵輸入)。將用於分段模式的10個字節的查找常量存儲器表連接起來。合成後,處理器在第IV-E節中產生“GDS”。
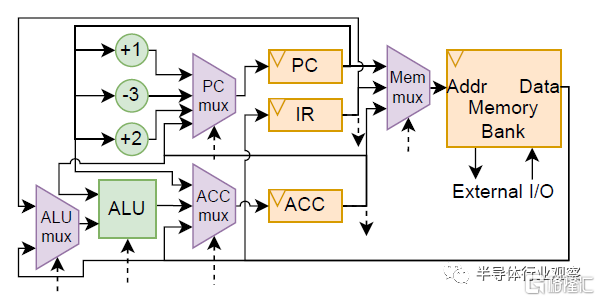
圖13 GPT-4設計的基於累加器的數據路徑(由人工繪制)。用虛线表示的控制信號。
F.觀察
總的來說,ChatGPT-4產生了相對高質量的代碼,這可以從短暫的驗證周轉中看出。編寫完Python匯編程序(Conversation 09)後,修復錯誤的會話(10-13、15-16)只使用了125條消息中的19條。考慮到ChatGPT-4每3小時25條消息的速率限制,此設計的總時間預算爲ChatGPT--4的22.8小時(包括重新啓動)。每條消息的實際生成平均約爲30秒:如果沒有速率限制,整個設計本可以在<100分鐘內完成,具體取決於人類工程師。盡管ChatGPT-4相對容易地生成了Python匯編程序,但它很難編寫爲我們的設計編寫的程序,而且ChatGPT也沒有編寫任何重要的測試程序。總體上,我們完成了在模擬和FPGA仿真中評估了一系列全面的人工編寫的匯編程序中的所有24條指令。

圖14 處理器綜合信息。
5
評估
A.討論
實際採用的步驟:理想情況下,隨着會話LLM的興起,可以用最少的精力實現從想法到功能設計。盡管人們非常重視它們的單次性能(即單步完成設計),但我們發現,對於硬件應用程序,LLM作爲代碼籤署者的功能更好。如果LLM與經驗豐富的工程師步調一致地工作,他們可能會成爲一個“能力倍增器”,提供“第一次通過”的設計,然後可以進行調整和快速迭代。
腳本基准測試的一個值得注意的觀察結果是,總體結果在很大程度上取決於早期的交互:對最初提示的響應和最初的幾個反饋實例。在許多情況下,由於LLM未能理解錯誤和修復之間的相關性,因此需要多次迭代反饋才能解決簡單的錯誤。因此,我們建議評估對早期提示的反應,如果它們不令人滿意,請考慮從早期开始“重新开始”對話。
最先進技術的表現:HuggingFace的HuggingChat顯然是表現最差的,有時甚至難以寫出連貫的Verilog。谷歌的Bard在這方面做得更好,但仍然無法遵循足夠詳細的說明進行評估。OpenAI的ChatGPT-3.5和ChatGPT-4都可以遵循規範並編寫Verilog,但只有ChatGPT-4可以可靠地做到這一點。盡管如此,它還是在不到一半的對話中成功地在沒有人工輸入的情況下做出了符合要求的功能性輸出。然而,一旦有了這些輸入,ChatGPT-4就能夠爲20/24基准生成兼容的代碼;這一表現與聊天流程的聯合設計相呼應。在這裏,該模型能夠幫助創建規範並將其實現到Verilog中。最先進性能的主要限制在於testbench和驗證代碼的作者身份。我們認爲,這反映了合適的开源訓練數據的(非)可用性。
B.對有效性的威脅
可再現性:由於測試的會話LLM是不確定的和模型生成的,因此輸出不具有一致的可再現性。這體現在基准測試對話的不同成功率中,其中針對單個基准測試的一些對話通過簡單的人工反饋和少量的信息獲得了成功,而另一些則完全失敗。兩個版本的ChatGPT都是封閉源代碼的,並且都是遠程運行的,因此我們無法檢查模型的參數並分析生成輸出的方法。這些測試的會話性質阻礙了再現性,因爲會話中的每個用戶響應都取決於之前的模型響應,因此微小的變化可能會在最終設計中產生實質性的變化。無論如何,我們確實爲結果重建提供了完整的會話日志。
統計有效性:由於這項工作的目標是以對話方方式設計硬件,我們沒有自動化這個過程的任何部分,每個對話都需要手動完成。這限制了可以進行的實驗的規模,而這些實驗也受到速率限制和模型可用性的阻礙(在撰寫本文時,OpenAI的ChatGPT-4和谷歌的Bard的訪問權限仍然有限)。因此,這三個測試案例可能無法提供足夠的數據來得出正式的統計結論。
6
結論
挑战:雖然很明顯,使用會話LLM來幫助設計和實現硬件器件總體上是有益的,但該技術還不能僅通過驗證工具的反饋來一致地設計硬件。目前最先進的模型在理解和修復這些工具所帶來的錯誤方面表現得不夠好,無法僅通過初始的人機交互創建完整的設計和testbench。
機會:盡管如此,當人類的反饋被提供給能力更強的ChatGPT-4模型,或用於聯合設計時,語言模型似乎是一個“能力倍增器”,允許快速的設計探索和迭代。一般來說,ChatGPT-4可以生成功能正確的代碼,這可以在實現公共模塊時節省設計者的時間。未來的潛在工作可能涉及更大規模的用戶研究以調查這一潛力,以及开發特定於硬件設計的會話LLM,以改進設計結果。
標題:用ChatGPT設計了一顆芯片
地址:https://www.iknowplus.com/post/5685.html







