英偉達H200突然發布:容量翻倍,帶寬狂飆
在今年的S23大會上,NVIDIA 突然宣布推出了 NVIDIA HGX H200,爲全球領先的 AI 計算平台帶來強大動力。據介紹,該平台基於 NVIDIA Hopper 架構,配備 NVIDIA H200 Tensor Core GPU 和高級內存,可處理生成 AI 和高性能計算工作負載的海量數據。
英偉達指出,NVIDIA H200 是首款提供 HBM3e 的 GPU,作爲一種更快、更大的內存,HBM3e可加速生成式 AI 和大型語言模型,同時能推進 HPC 工作負載的科學計算。借助 HBM3e,NVIDIA H200 能以每秒 4.8 TB 的速度提供 141GB 內存,與前前一代的NVIDIA A100 相比,容量幾乎翻倍,帶寬增加 2.4 倍。

HGX H200 由 NVIDIA NVLink 和 NVSwitch 高速互連提供支持,可爲各種應用工作負載提供最高性能,包括針對超過 1750 億個參數的最大模型的 LLM 訓練和推理。英偉達表示,在不斷發展的人工智能領域,企業依靠LLM來滿足各種推理需求。當爲大量用戶群大規模部署時,人工智能推理加速器必須以最低的 TCO 提供最高的吞吐量。
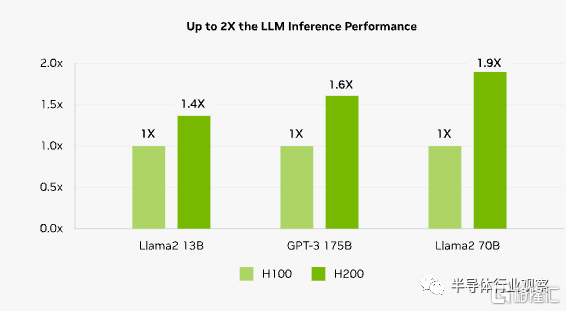
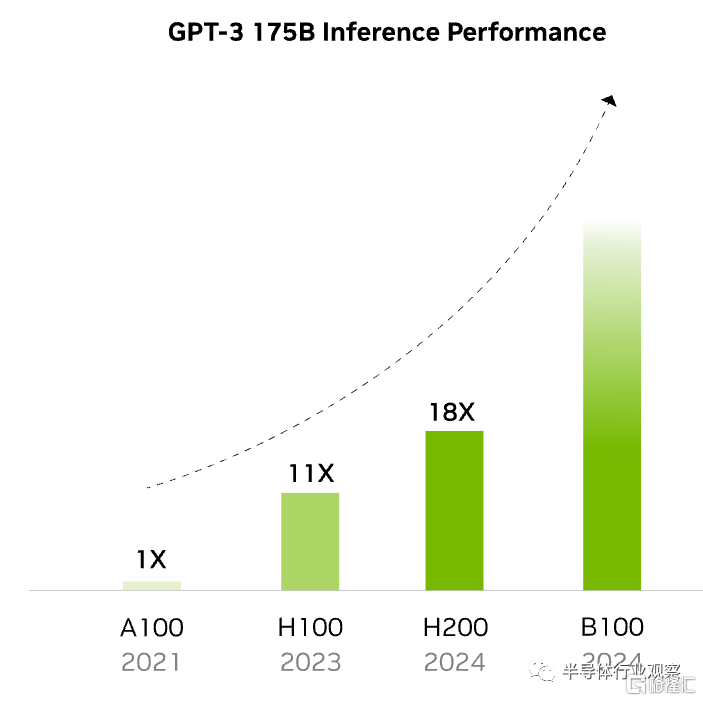
在處理 Llama2 (一個 700 億參數的 LLM)等 LLM 時,H200 的推理速度比 H100 GPU 提高了 2 倍。
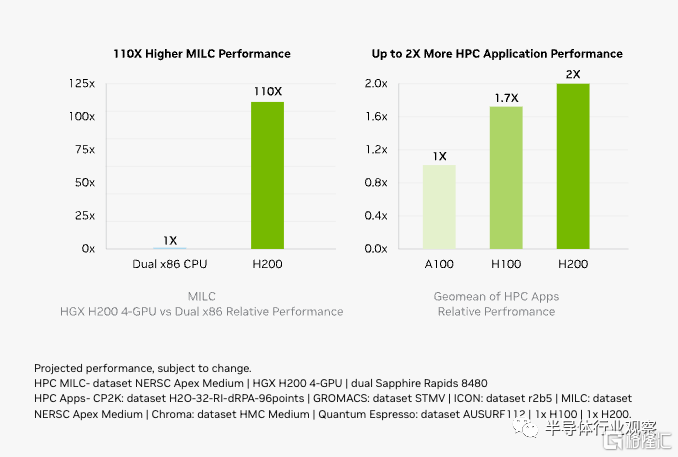
英偉達進一步指出,內存帶寬對於 HPC 應用程序至關重要,因爲它可以實現更快的數據傳輸,減少復雜的處理瓶頸。對於模擬、科學研究和人工智能等內存密集型 HPC 應用,H200 更高的內存帶寬可確保高效地訪問和操作數據,與 CPU 相比,獲得結果的時間最多可加快 110 倍。
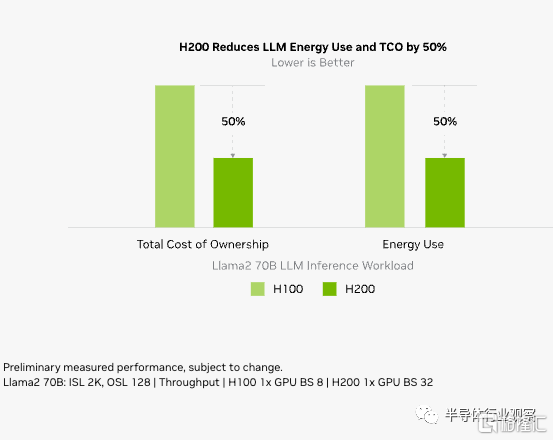
隨着 H200 的推出,能源效率和 TCO 達到了新的水平。這項尖端技術提供了無與倫比的性能,且功率配置與 H100 相同。人工智能工廠和超級計算系統不僅速度更快,而且更環保,提供了推動人工智能和科學界向前發展的經濟優勢。
NVIDIA H200 將應用於具有四路和八路配置的 NVIDIA HGX H200 服務器主板,這些主板與 HGX H100 系統的硬件和軟件兼容。它還可用於8 月份發布的採用 HBM3e 的 NVIDIA GH200 Grace Hopper superichip。
據介紹,八路 HGX H200 提供超過 32 petaflops 的 FP8 深度學習計算和 1.1TB 聚合高帶寬內存,可在生成式 AI 和 HPC 應用中實現最高性能。
英偉達表示,H200 可以部署在各種類型的數據中心中,包括本地、雲、混合雲和邊緣。NVIDIA 的全球生態系統合作夥伴服務器制造商(包括華擎 Rack、華碩、戴爾科技、Eviden、技嘉、惠普企業、英格拉科技、聯想、QCT、Supermicro、緯創資通和緯穎科技)可以使用 H200 更新其現有系統。
而除了CoreWeave、Lambda和 Vultr 之外,亞馬遜網絡服務、谷歌雲、微軟 Azure 和甲骨文雲基礎設施將從明年开始成爲首批部署基於 H200 實例的雲服務提供商。
HBM3e,H200的升級重點
隨着速度更快、容量更大的 HBM3E 內存將於 2024 年初上线,NVIDIA 一直在准備其當前一代服務器 GPU 產品以使用新內存。早在 8 月份,我們就看到 NVIDIA 計劃發布配備 HBM3E 的 Grace Hopper GH200 超級芯片版本。這次NVIDIA 宣布的H200,其實就是配備 HBM3E 內存的獨立 H100 加速器的更新版本。
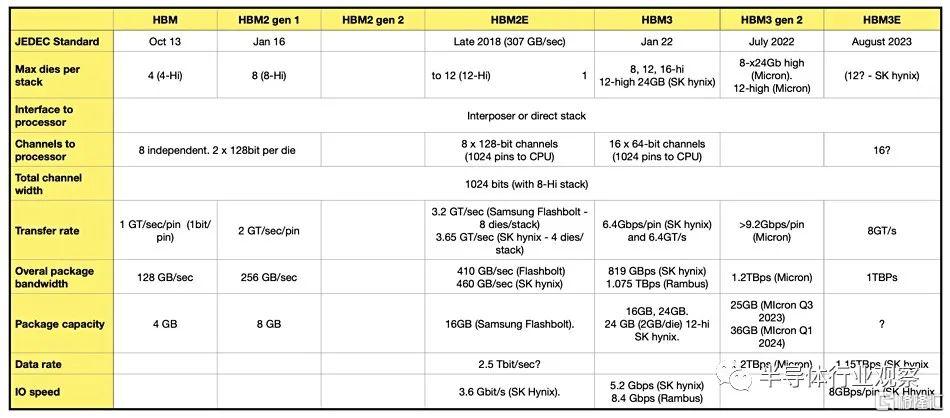
據SK海力士介紹,HBM3E不僅滿足了用於AI的存儲器必備的速度規格,也在發熱控制和客戶使用便利性等所有方面都達到了全球最高水平。在速度方面,其最高每秒可以處理1.15TB(太字節)的數據。其相當於在1秒內可處理230部全高清(Full-HD,FHD)級電影(5千兆字節,5GB)。值得一提的是,美光在七月還宣布推出超過 1.2TBps HBM3 gen 2 產品,這表明 SK 海力士還有很多追隨的工作要做。
與 Grace Hopper 的同類產品一樣,H200 的目的是通過推出具有更快和更高容量內存芯片版本,作爲 Hx00 產品线的中期升級。利用美光和其他公司即將推出的HBM3E 內存,NVIDIA 將能夠提供在內存帶寬受限的工作負載中具有更好的實際性能的加速器,而且還能夠提供能夠處理更大工作負載的部件。這對於生成式AI 領域尤其有幫助——迄今爲止,該領域幾乎推動了對 H100 加速器的所有需求——因爲最大的大型語言模型可以最大程度地支持 80GB H100。
與此同時,由於 HBM3E 內存要到明年才能發貨,NVIDIA 一直在利用這個間隙發布 HBM3E 更新部件。繼今年夏天發布 GH200 後,NVIDIA 宣布採用 HBM3E 的 Hx00 加速器獨立版本只是時間問題,現在H200終於到來。
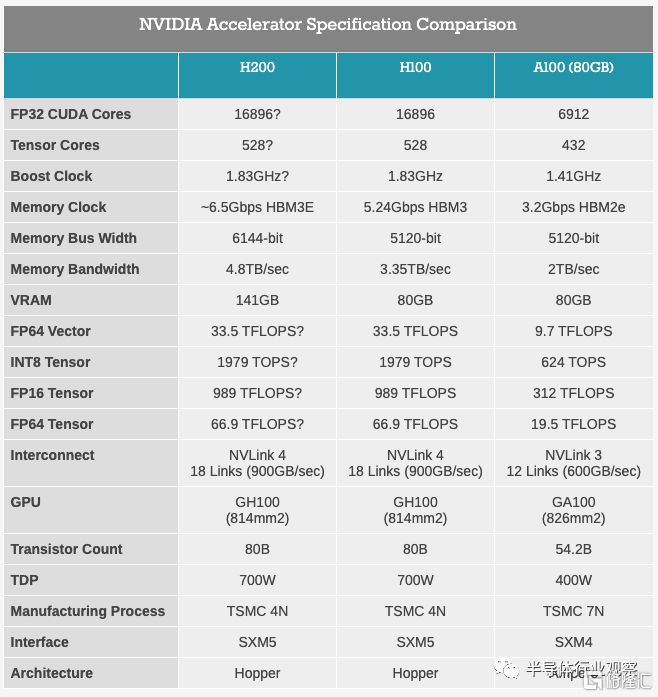
從今天披露的規格來看,H200 基本上看起來就像是 GH200 的 Hopper 一半,作爲自己的加速器。當然,這裏最大的區別是將 HBM3 替換爲 HBM3E,這使得 NVIDIA 能夠提高內存帶寬和容量,並且 NVIDIA 啓用了第 6 個HBM內存堆棧,該堆棧在原始 H100 中被禁用。這將使 H200 的內存帶寬從 80GB 提升至 141GB,內存帶寬從 3.35TB/秒提升至 NVIDIA 初步預期的 4.8TB/秒。
根據總帶寬和內存總线寬度向後推算,這表明 H200 的內存將以大約 6.5Gbps/引腳運行,與原始 H100 的 5.3Gbps/引腳 HBM3 內存相比,頻率增加了大約 25%。這實際上遠低於 HBM3E 額定的內存頻率(美光希望達到 9.2Gbps/pin),但由於它正在針對現有 GPU 設計進行改造,因此看到 NVIDIA 當前的內存控制器沒有相同的內存頻率範圍也就不足爲奇了。
H200還將保留GH200不同尋常的141GB內存容量。HBM3E 內存本身的物理容量爲 144GB(以六個 24GB 堆棧的形式出現),但 NVIDIA 出於產量原因保留了部分容量。因此,客戶無法訪問板載的所有 144GB,但與 H100 相比,他們可以訪問所有六個堆棧,並具有容量和內存帶寬優勢。
正如我們之前所說,運送具有全部 6 個工作堆棧的部件基本上需要完美的芯片,因爲 H100 的規格非常慷慨地允許 NVIDIA 運送具有非功能堆棧的部件。因此,與同類 H100 加速器(已經供不應求)相比,這可能是體積較小、良率更低的部件。
除此之外,到目前爲止,NVIDIA 尚未透露任何信息表明 H200 將比其前身具有更好的原始計算吞吐量。雖然內存變化應該會提高實際性能,但 NVIDIA 爲 HGX H200 集群引用的 32 PFLOPS FP8 性能與當今市場上的 HGX H100 集群相同。
不過據anadtech分析,H200 迄今爲止僅適用於 SXM5 插槽,並且在矢量和矩陣數學方面具有與 Hopper H100 加速器完全相同的峰值性能統計數據。區別在於,H100 具有 80 GB 和 96 GB 的 HBM3 內存,在初始設備中分別提供 3.35 TB/秒和 3.9 TB/秒的帶寬,而 H200 具有 141 GB 更快的 HBM3e 內存,帶寬爲 4.8總帶寬 TB/秒。
與 Hopper 基准相比,內存容量增加了 1.76 倍,內存帶寬比 Hopper 基准增加了 1.43 倍——所有這些都在相同的 700 瓦功率範圍內。作爲對比,AMD 的Antares MI300X 將提供 5.2 TB/秒的帶寬和 192 GB 的 HBM3 容量,並且很可能提供更高的峰值浮點功率,但也可能只是更有效的浮點功率。
最後,與配備 HBM3E 的 GH200 系統一樣,NVIDIA 預計 H200 加速器將於 2024 年第二季度推出。
HGX H200和Quad GH200 ,同時發布
除了 H200 加速器之外,NVIDIA 還發布了 HGX H200 平台,這是使用較新加速器的 8 路 HGX H100 的更新版本。HGX 載板是 NVIDIA H100/H200 系列的真正支柱,包含 8 個 SXM 外形加速器,這些加速器以預先安排的全連接拓撲連接。HGX 板的獨立性質使其能夠插入合適的主機系統,從而允許 OEM 定制其高端服務器的非 GPU 部分。

鑑於 HGX 與 NVIDIA 的服務器加速器齊頭並進,HGX 200 的發布很大程度上只是一種形式。盡管如此,NVIDIA 仍確保在 SC23 上宣布這一消息,並確保 HGX 200 主板與 H100 主板交叉兼容。因此,服務器制造商可以在當前的設計中使用 HGX H200,從而實現相對無縫的過渡。
隨着 NVIDIA 現在批量發售 Grace 和 Hopper(以及 Grace Hopper)芯片,該公司還宣布推出一些使用這些芯片的其他產品。其中最新的是 4 路 Grace Hopper GH200 板,NVIDIA 簡稱爲 Quad GH200。
名副其實,Quad GH200 將四個 GH200 加速器放置在一塊板上,然後可以安裝在更大的系統中。各個 GH200 以 8 芯片、4 路 NVLink 拓撲相互連接,其想法是使用這些板作爲更大系統的構建塊。
實際上,Quad GH200 是與 HGX 平台相對應的 Grace Hopper。與僅 GPU 的 HGX 板不同,Grace CPU 的加入在技術上使每個板獨立且自支撐,但將它們連接到主機基礎設施的需求保持不變。
Quad GH200 節點將提供 288 個 Arm CPU 內核和總計 2.3TB 的高速內存。值得注意的是,NVIDIA 在這裏沒有提到使用 GH200 的 HBM3E 版本(至少最初沒有),因此這些數字似乎是原始的 HBM3 版本。這意味着我們希望每個 Grace CPU 配備 480GB LPDDR5X,每個 Hopper GPU 配備 96GB HBM3。或者總共1920GB LPDDR5X和384GB HBM3內存。
一台超級計算機:23762個GH200,18.2 兆瓦
在發布H200的同時,NVIIDA 還宣布與 Jupiter 合作贏得了一項新的超級計算機設計。根據 EuroHPC 聯合組織的訂購,Jupiter 將成爲由 23,762 個 GH200 節點構建的新型超級計算機。一旦上线,Jupiter 將成爲迄今爲止宣布的最大的基於 Hopper 的超級計算機,並且是第一台明確(且公开)針對標准 HPC 工作負載以及已經出現的低精度張量驅動的 AI 工作負載的超級計算機。定義迄今爲止宣布的基於 Hopper 的超級計算機。
Jupiter 與 Eviden 和 ParTec 籤約,徹底展示了NVIDIA 技術。基於 NVIDIA 今天發布的 Quad GH200 節點,Grace CPU 和 Hopper GPU 成爲超級計算機的核心。各個節點均由 Quantum-2 InfiniBand 網絡支持,毫無疑問基於 NVIDIA 的 ConnectX 適配器。
該公司沒有透露具體的核心數量或內存容量數據,但由於我們知道單個 Quad GH200 主板提供的功能,因此數學計算很簡單。在高端(假設沒有出於良率原因進行回收/合並),這將是 23,762 個 Grace CPU、23,762 個 Hopper H100 級 GPU、大約 10.9 PB 的 LPDDR5X 和另外 2.2PB 的 HBM3 內存。
該系統預計爲人工智能用途提供 93 EFLOPS 的低精度性能,或爲傳統 HPC 工作負載提供超過 1 EFLOPS 的高精度 (FP64) 性能。後一個數字尤其值得注意,因爲這將使 Jupiter 成爲第一個用於 HPC 工作負載的基於 NVIDIA 的百億億次系統。
也就是說,應謹慎對待 NVIDIA 的 HPC 性能聲明,因爲 NVIDIA 仍在計算張量性能 - 1 EFLOPS 是 23,762 個 H100 只能通過 FP64 張量運算提供的東西。理論 HPC 超級計算機吞吐量的傳統指標是矢量性能而不是矩陣性能,因此該數字與其他系統不完全可比。不過,由於 HPC 工作負載也部分地大量使用了矩陣數學,因此這也不是一個完全無關的說法。否則,對於任何尋求強制性 Frontier 比較的人來說,Jupiter 的直接矢量性能將約爲 800 TFLOPS,而 Frontier 的直接矢量性能是 Frontier 的兩倍多。另一方面,這兩個系統在現實條件下的接近程度將取決於它們各自的工作負載中使用了多少矩陣數學(LINPACK 結果應該很有趣)。
該系統的價格標籤尚未公布,但功耗爲:18.2 兆瓦電力(比 Frontier 少約 3 兆瓦)。因此,無論系統的真實價格是多少,就像系統本身一樣,它絕不是嬌小的。
根據 NVIDIA 的新聞稿,該系統將安裝在德國於利希研究中心 (Forschungszentrum Jülich) 設施中,用於“創建氣候和天氣研究、材料科學、藥物發現、工業工程和量子計算領域的基礎人工智能模型”。” 該系統計劃於 2024 年安裝,但尚未公布預計上线日期。
標題:英偉達H200突然發布:容量翻倍,帶寬狂飆
地址:https://www.iknowplus.com/post/51580.html







