谷歌新一代AI芯片發布,Jeff Dean:AI硬件性能提升更難了
昨夜晚間,谷歌突然對外披露公司新一代 AI 加速器Cloud TPU v5e。
谷歌在博客中指出,我們正處於計算領域千載難逢的拐點。設計和構建計算基礎設施的傳統方法不再足以滿足生成式人工智能和LLM等工作負載呈指數級增長的需求。事實上,過去五年裏LLM的參數數量每年增加 10 倍。因此,客戶需要具有成本效益且可擴展的人工智能優化基礎設施。
Google Cloud 則通過提供領先的人工智能基礎設施技術、TPU 和 GPU,以滿足开發者的需求,今天,谷歌宣布,公司在這兩個產品組合均得到重大增強。首先,我們正在通過 Cloud TPU v5e 擴展我們的 AI 優化基礎設施產品組合,這是迄今爲止最具成本效益、多功能且可擴展的 Cloud TPU,現已提供預覽版。TPU v5e 提供與 Google Kubernetes Engine (GKE)、Vertex AI 以及 Pytorch、JAX 和 TensorFlow 等領先框架的集成,因此您可以通過易於使用、熟悉的界面开始使用。
同時,谷歌還宣布,公司基於 NVIDIA H100 GPU的GPU 超級計算機 A3 VM將於下個月全面上市,爲您的大規模 AI 模型提供支持。
TPU v5e,爲大模型而生
谷歌表示,Cloud TPU v5e是Google Cloud 最新一代 AI 加速器,專爲提供中大規模訓練和推理所需的成本效益和性能而構建。雖然谷歌並沒披露更多關於這個芯片的工藝,但據猜測,這可能是基於5nm打造的。
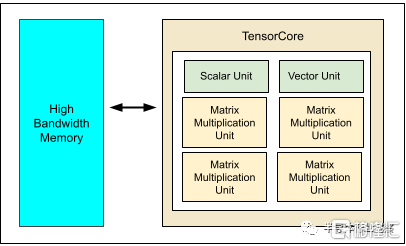
了解谷歌TPU 芯片的讀者都知道,在之前的產品中,他們都有一個或兩個 TensorCore 來運行矩陣乘法。與 v2 和 v3 Pod 類似,v5e 每個芯片都有一個 TensorCore。每個 TensorCore 有 4 個矩陣乘法單元 (MXU)、一個向量單元和一個標量單元。下表顯示了 v5e 的關鍵規格及其值。相比之下,v4 Pod 每個芯片有 2 個 TensorCore。
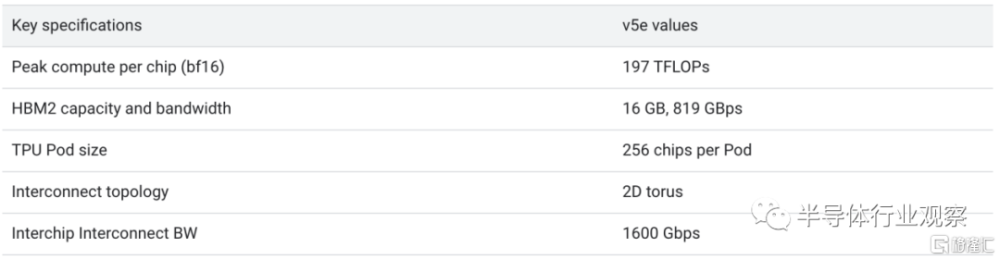
與 Cloud TPU v4 相比,TPU v5e 可爲LLM和新一代 AI 模型提供高達 2 倍的訓練性能和高達 2.5 倍的推理性能。TPU v5e 的成本不到 TPU v4 的一半,使更多組織能夠訓練和部署更大、更復雜的 AI 模型。
谷歌指出,v5e 每個 Pod 的芯片佔用空間較小,爲 256 個,經過優化,成爲transformer、文本到圖像和卷積神經網絡 (CNN) 訓練、微調和服務的最高價值產品。
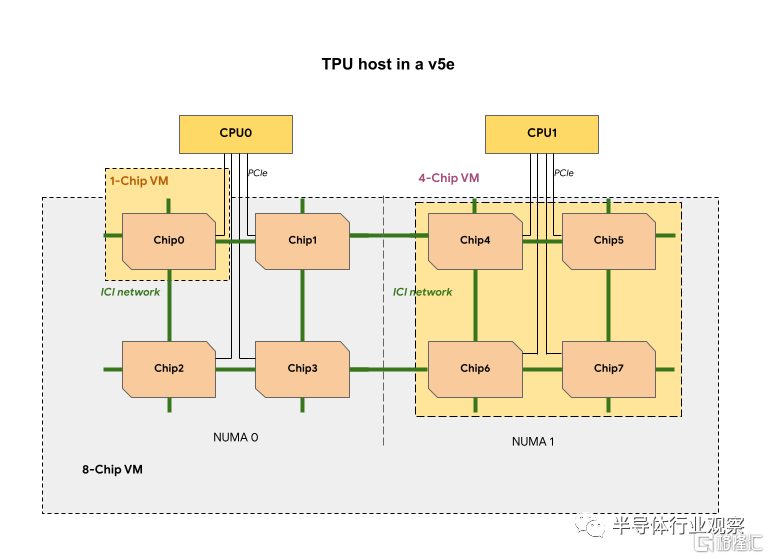
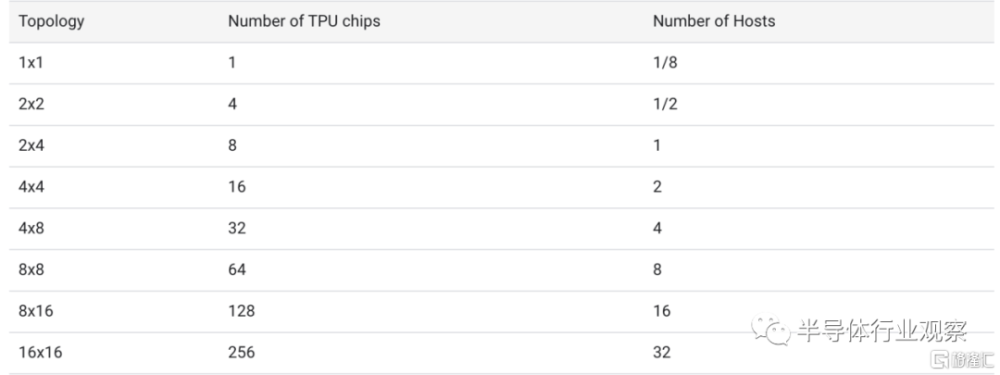
換而言之,通過 TPU v5e Pod 平衡性能、靈活性和效率,允許最多 256 個芯片互連,總帶寬超過 400 Tb/s 和 100 petaOps INT8 性能。TPU v5e 的用途也非常廣泛,支持八種不同的虛擬機 (VM) 配置,範圍從一個芯片到單個片內的 250 多個芯片。這使得客戶能夠選擇正確的配置來服務於各種 LLM 和 gen AI 模型大小。
與此同時,Cloud TPU v5e 還爲領先的 AI 框架(如 JAX、PyTorch 和 TensorFlow)以及流行的开源工具(如 Hugging Face 的 Transformers 和 Accelerate、PyTorch Lightning 和 Ray)提供內置支持。谷歌透露,公司將通過即將發布的 PyTorch/XLA 2.1 版本進一步加強對 Pytorch 的支持,其中包括 Cloud TPU v5e 支持,以及用於大規模模型訓練的模型和數據並行性等新功能。
據介紹,在公共預覽版,推理客戶可以使用 1 芯片 (v5litepod-1)、4 芯片 (v5litepod-4) 和 8 芯片 (v5litepod-8)。“爲了爲具有更多芯片的虛擬機騰出空間,調度程序可能會搶佔具有較少芯片的虛擬機。因此,8 芯片虛擬機很可能會搶佔 1 芯片和 4 芯片虛擬機。”谷歌表示。

他們進一步指出,爲了更輕松地擴展訓練作業,谷歌還在預覽版中引入了 Multislice 技術,該技術允許用戶輕松擴展 AI 模型,使其超出物理 TPU pod 的範圍,最多可容納數萬個 Cloud TPU v5e 或 TPU v4 芯片。
谷歌在博客中寫道,到目前爲止,使用 TPU 的訓練作業僅限於單個 TPU 芯片slice,TPU v4 的最大slice大小爲 3,072 個芯片。借助 Multislice,开發人員可以在單個 Pod 內通過芯片間互連 (ICI):inter-chip interconnect 或通過數據中心網絡 (DCN:Data center network) 跨多個 Pod 將工作負載擴展到數萬個芯片。Multislice 技術同時還爲谷歌最先進的 PaLM 模型的創建提供了動力。
“我們真正致力於使其成爲一個可擴展的解決方案,”谷歌的Lohmeyer說。“我們跨軟件和硬件進行設計。在這種情況下,該軟件[和]硬件與Multislice等新軟件技術協同工作的魔力,使我們的客戶能夠輕松擴展其 AI 模型,超越單個 TPU pod 或單個 GPU 集群的物理邊界,”他解釋道。“換句話說,單個大型人工智能工作負載現在可以跨越多個物理 TPU 集群,擴展到數萬個芯片,而且這樣做非常經濟高效。”Lohmeye強調。
Jeff Dean:AI 硬件性能的,下一個100倍將會更加困難
十年前,Jeff Dean 在一張紙上做了一些數學計算,並發現:如果谷歌將人工智能功能添加到其同名搜索引擎中,它就必須將其數據中心佔地面積擴大一倍,這就趨勢谷歌走上創建定制張量處理單元(TPU)矩陣數學引擎的道路。
十年過去了,人工智能變得更加復雜、計算密集,備受討論的 TPUv4 鐵雖然現在和未來很多年都很有用,但看起來有點過時了。全新推出的 TPUv5e將替代TPUv4 系統。
在日前开幕的Hotchips演講中,Jeff Dean表示,谷歌專注於驅動人工智能模型的三種不同方法——稀疏性、自適應計算和動態神經網絡——並且還試圖讓人工智能蛇喫掉它的尾巴而不是蠶食它。
在Jeff Dean看來,真正讓人工智能專家系統开始設計人工智能處理器可加快整個芯片开發周期,從而幫助不斷改進的硬件進入該領域,以滿足更快增長的模型。
Dean 解釋說,到目前爲止創建的人工智能模型,整個模型的層數不斷增加,參數數量呈爆炸式增長,由數十億、數百億、數千億的token snippets 數據驅動,每次人工智能都會被激活。在新token上訓練的模型或針對已完成的模型提出token以進行人工智能推理。
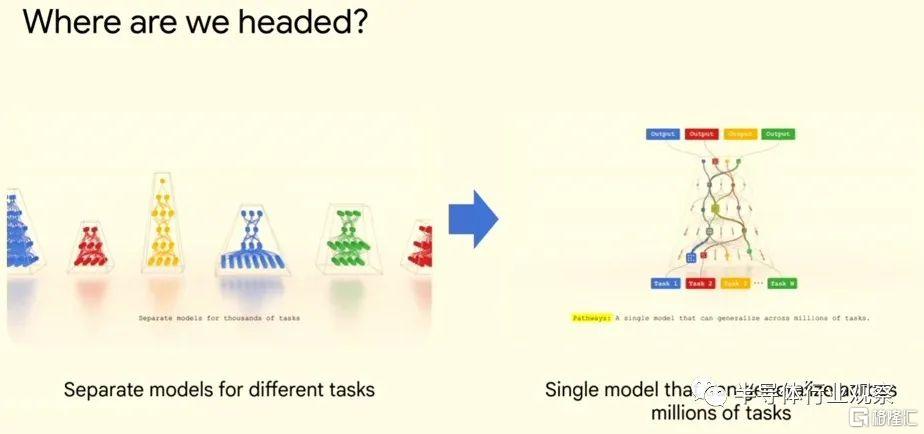
但是,有了像 Pathways 這樣的框架(它是 Google PaLM 系列模型的基礎),世界正在從專門針對不同任務的單獨 AI 模型轉向擁有單一基礎模型。
對於稀疏模型,AI 模型的各個部分會在需要時激活(activate ),並且僅激活這些部分。模型如何知道要激活哪些部分尚不清楚,這就是 Pathways 框架中的祕密武器,該框架已通過 Gemini 模型得到完善,毫無疑問使用了 Dean 所說的技術。
值得注意的是,Pathways 框架不像 Google 創建的早期且可能更爲初級的 TensorFlow 框架(該框架於 2015 年 11 月开源)那樣是开源的。因此,我們只能知道 Google 告訴我們的有關 Pathways 和 Gemini 的信息。
“與這個巨大的模型相比,稀疏模型的效率要高得多,”Dean解釋道。“他們只是調用整個模型的正確部分——正確的部分也是在訓練過程中學到的東西。然後模型的不同部分可以專門用於不同類型的輸入。最終的結果是,您最終會得到一些非常大的模型的正確 1% 或正確 10% 的結果,這會提高您的響應能力和更高的准確性,因爲您現在擁有比您大得多的模型容量可以進行其他訓練,然後可以調用正確的部分。”
根據 Dean 的說法,稀疏性的另一個方面對於系統架構師來說很重要,它與加速器中通常談論的細粒度稀疏性不同,在加速器中,單個向量或張量內的稀疏性(通常每四個中的兩個)矩陣中的值設置爲零,將其從密集型轉換爲稀疏型),這也不同於粗粒度稀疏性,其中模型中的大型模塊要么被激活,要么不被激活。這種稀疏性看起來像這樣,我們將幾個 Dean 的圖表合並到一頁上,這樣您就可以將其全部理解:
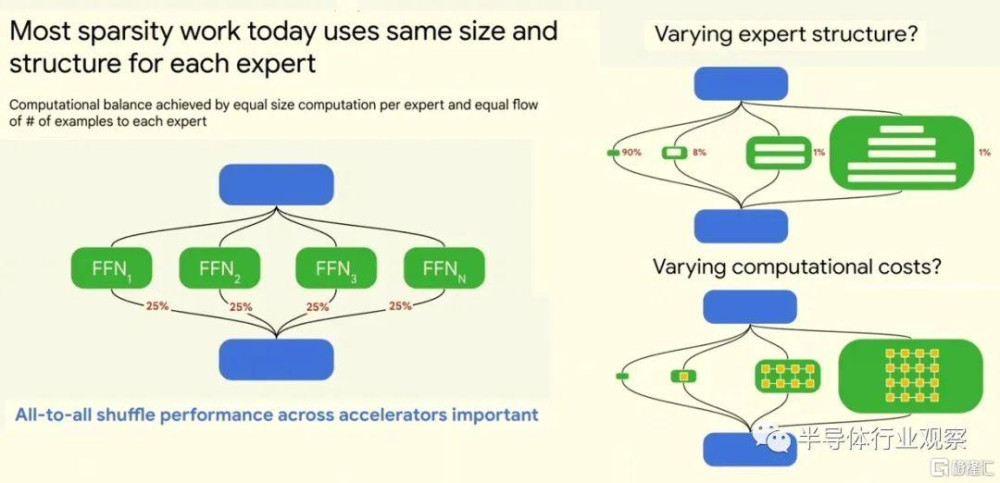
“當今大多數稀疏工作對每個專家都使用相同的大小和結構,”Dean說。“所以這裏有一些綠色專家爲他們服務。這裏有一些學習路由功能,可以了解哪個專家擅長哪種事情,然後將一些示例發送給適當的專家。計算平衡通常是通過每個專家的計算量相等以及每個專家的示例數量相等的流量來實現的。對於計算機架構師來說,這意味着跨加速器的全面混洗性能非常重要。對於所有稀疏模型來說都是如此——您希望能夠以正確的方式將事物從模型的一個部分快速路由到另一部分。”
“不過,您可能想做的一件事是,不是具有固定的計算成本,而是改變模型不同部分的計算成本。在每個示例上花費相同的計算量是沒有意義的,因爲有些示例的難度是原來的 100 倍。我們在真正困難的事情上花費的計算量應該是非常簡單的事情上的 100 倍。”Dean強調。
事實證明,一些小型專家可能只需要少量計算,並且可以用於生產中使用的模型中大約 90% 的提示。專家們爲了處理更復雜的事情而變得更大,具有不同的計算結構和可能更多的層,並且它們的計算量更大,因此運行成本更高。如果您正在運行人工智能服務,您將希望能夠將成本歸因於所提供的專家答案的價值,以便您可以適當收費。
提高效率和計算能力的途徑
當然,這不是谷歌的獨家理論——該公司之所以談論它是因爲 Pathways 框架這樣做:
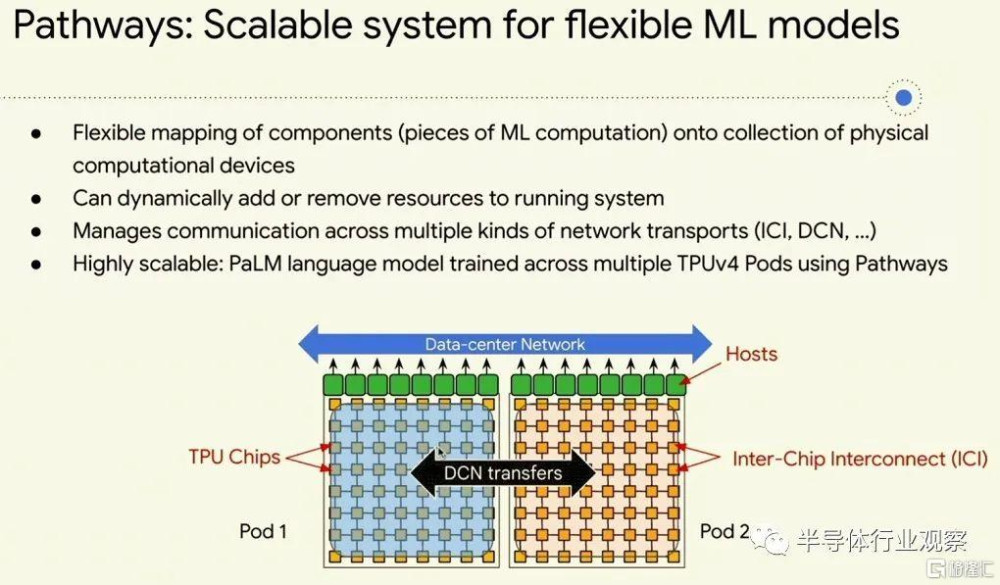
這就是稀疏性和自適應計算。
Dean 說,上圖中提到的最後一件事是動態神經網絡,這意味着可以在正在運行的系統中添加或刪除容量——這是我們幾十年來通用服務器所擁有的(雖然不是在 X86 平台上,但奇怪的是,這就是 Arm 和 RISC-V 可能能夠趕上大型機和 RISC/Unix 系統的地方)。CPU 及其工作負載的情況(虛擬機管理程序級別肯定存在動態分配)對於 GPU、TPU 和其他 AI 計算引擎來說也是如此。您希望能夠在運行推理或訓練時動態地爲任何給定模型添加或減少核心池的容量。
來自 Google 的具有 5000 億個參數的 PaLM 模型在 Pathways 上進行了訓練,並通過在具有 6,144 個 TPUv4 引擎的一對 pod 之間動態分配資源來實現這一目標,但 TPUv4 引擎實際上分布在總共 24,576 個引擎的 6 個 pod 中,所有這些都鏈接在一起通過高速數據中心網絡。像這樣:
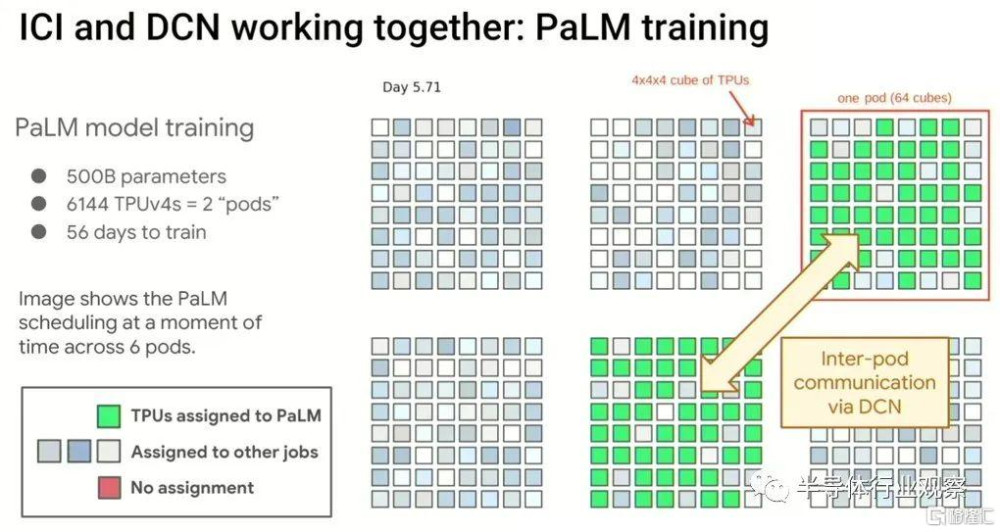
以下是 Dean 希望給系統架構師留下深刻印象的關鍵要點:
加速器的連接性(帶寬和延遲)很重要
規模對於訓練和推理都很重要
稀疏模型給內存容量和高效路由帶來壓力
機器學習軟件必須能夠輕松表達有趣的模型 - 就像上圖中所示的函數稀疏性
功率、可持續性和可靠性確實很重要
Google Fellow以及工程副總裁Amin Vahdat在隨後的演講中展示了人工智能行業面臨的模型大小增長的指數曲线:
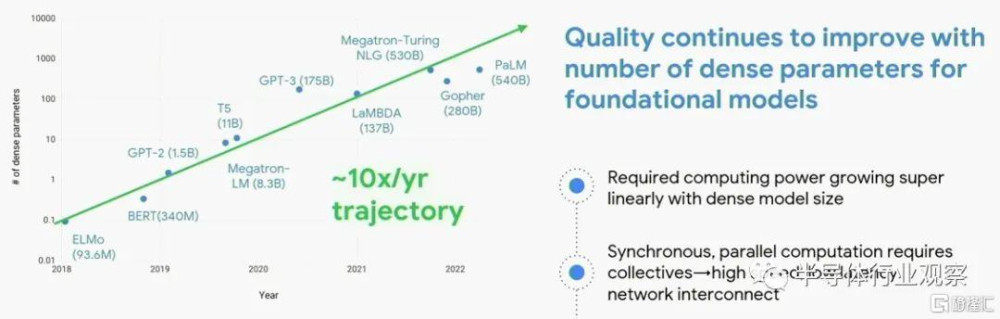
據觀察,我們絕對沒有理由相信模型的復雜性會因此而降低,計算能力的需求將會降低。但根據我們的估計,模型每年增長 10 倍,GPU 和 TPU 的性能最多每年增長 2 到 3 倍。公司必須通過擴展來彌補這一點,這很困難,並改進他們的模型,這也很困難。
這就是爲什么谷歌已經在其機群中部署了 TPUv5e 引擎的原因。在我們看來,谷歌的 TPUv6 可能正在开發中並准備就緒很快就會部署,以幫助支持Gemini模型的商業化。
爲了使每 TCO 的性能提高 100 倍,Vahdat進行了一個深入的講座,介紹了如何衡量人工智能或通用計算平台的相對價值,在人工智能出現之前,我們一直同意這一點系統——谷歌必須做很多事情,當中包括:
創建專門的硬件 - TPU - 用於密集矩陣乘法。
使用 HBM 內存將這些矩陣數學引擎的內存帶寬提高 10 倍。
創建專門的硬件加速器,用於稀疏矩陣中的分散/聚集操作 - 我們現在稱之爲 Sparsecore,它嵌入在 TPUv4i、TPUv4 和可能的 TPUv5e 引擎中。
採用液體冷卻可最大限度地提高系統電源效率,從而提高經濟效益。
使用混合精度和專門的數字表示來提高設備的實際吞吐量(Vahdat 稱之爲“有效吞吐量”)。
並具有用於參數分配的同步、高帶寬互連,事實證明,這是一種光路开關,可以在系統上的作業發生變化時幾乎即時重新配置網絡,並且還提高了機器的容錯能力。對於一個擁有數萬個計算引擎且工作負載需要數月才能運行的系統來說,這是一件大事,世界各地的 HPC 中心都非常清楚這一點。
“我們爲應對這一挑战而必須構建的計算基礎設施類型必須改變,”Vahdat在主題演講中說道。“我認爲,值得注意的是,如果我們試圖在通用計算上做到這一點,我們就不會達到今天的水平。換句話說,我們在過去 50 到 60 年間所形成的傳統智慧實際上已經被拋到了九霄雲外。我認爲可以公平地說,在谷歌,但更重要的是,在整個社區,機器學習周期將佔據我們想做的事情中越來越多的部分。”
谷歌專注於優化硬件和軟件以跨系統集群動態管理工作負載和功耗的一件事:
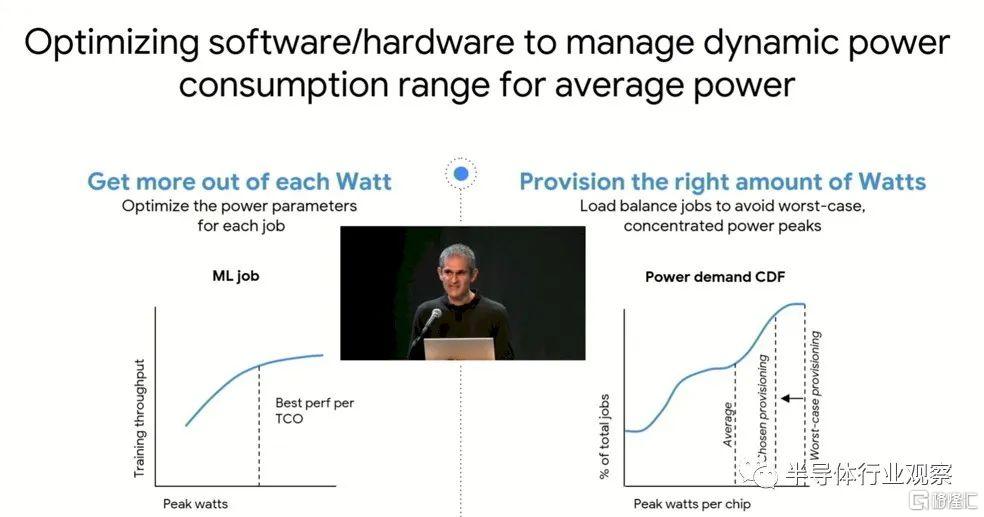
對於受內存限制的部分,電壓和電流強度可能會有很大差異,正如 Vahdat 所說,試圖管理數千到數萬個計算引擎集群的功耗是“介於困難和不可能之間的事情”。通過不在集群中創建大量熱點(這可能發生在 Google 訓練 PaLM 模型時),可以延長設備的使用壽命並減少中斷,這對於 AI 訓練等同步工作非常具有破壞性,就像 HPC 模擬一樣和建模。與其回滾到檢查點並從那裏开始,不如從一开始就避免中斷。
以下是如何利用核心頻率和電壓來平衡一些事情。
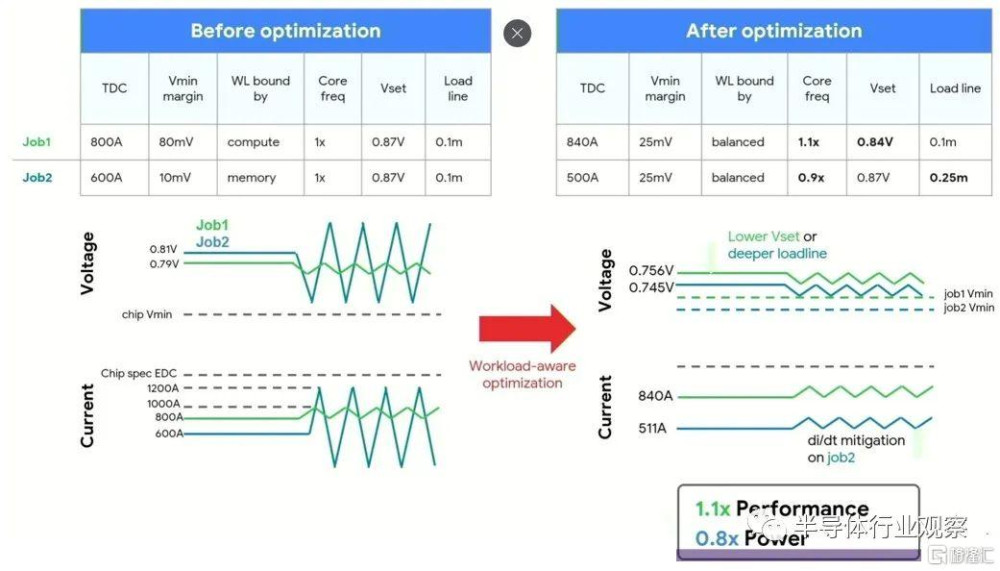
當然,快速更新TPU芯片是谷歌工作最重要的一部分。
Dean表示,目前芯片的問世大約需要三年時間。這需要六到十二個月的時間進行設計和探索,一年的時間來實施設計,六個月的時間與晶圓進行流片,十二個月的時間用於將其投入生產、測試和提升。
目前尚不清楚人工智能可以在多大程度上縮短芯片开發周期或可以減少多少人力,Dean也沒有提供任何估計。但顯然,硬件設計越接近新興人工智能模型就越好。
標題:谷歌新一代AI芯片發布,Jeff Dean:AI硬件性能提升更難了
地址:https://www.iknowplus.com/post/27934.html







