中金:從OpenAI Sora看視頻生成模型技術進展
2月15日,OpenAI發布最新視頻生成模型Sora,能夠生成長達一分鐘的分辨率爲1920*1080的高質量視頻,在生成時長和生成質量上較其他現有模型和產品實現了明顯突破。
摘要
延續DiTs架構,Sora實現高質量長視頻生成。根據技術報告,Sora延續DiTs架構,隨訓練計算量提升而展現出顯著的生成能力提升(Scalable)。相較先前模型,我們認爲其最爲突出的創新之處在於:1)LDM自編碼器實現時間維度壓縮,使得長視頻生成成爲可能;2)直接對LDM中潛視頻進行圖塊化處理並直接使用Transformer建模,解除輸入格式限制的同時,能夠創新性地實現任何像素和長寬比視頻的生成;3)我們判斷其訓練數據集中可能包含帶有物理信息的合成數據,從而使模型展現出對物理信息的初步理解能力;4)復用DALL·E 3的重標注技術,對視頻數據生成高質量文字標注,借助GPT對提示詞進行擴展,提升生成效果。
技術基礎一:擴散模型是當前圖片/視頻生成的主要技術路线。擴散模型(Diffusion model)通過神經網絡(主要是U-Net)從純噪聲圖像中學習去噪過程,從而通過給定噪聲來完成圖像生成任務。潛在擴散模型(Latent diffusion model)通過降維進一步提升了訓練效率並降低訓練成本,成爲圖片生成的主要技術路线。在預訓練的圖片生成模型基礎上,學界提出生成關鍵幀並在時序上實現對齊即可將圖片生成模型轉化爲視頻生成模型,但這類模型存在生成時長短、穩定性差等劣勢。
技術基礎二:Transformer架構的引入使擴散模型能夠實現規模效應。DiTs(Diffusion transformer)將先前擴散模型的骨幹U-Net卷積網絡替換爲可伸縮性更強的Transformer,從而能夠實現更強的可拓展性,即能夠通過增加參數規模和訓練數據量來快速提升模型的性能表現,模型在圖片生成任務上表現優異。W.A.L.T.首次將Transformer架構引入視頻生成模型,使用窗口注意力降低了對算力的需求,並展現了良好的視頻生成能力。
我們認爲Sora實現了AI+視頻場景的效果突破,通過借助Transformer架構展現了優異的可拓展性(Scalable)。展望未來,我們判斷基於Transformer架構的大模型有望在更多模態領域實現復刻,看好多模態領域技術進展。
風險
技術進展不及預期;應用落地不及預期;行業競爭加劇。
Sora:基於DiTs架構,實現長視頻的高質量生成
Sora展現了高質量的長視頻生成能力,相較先前的視頻生成模型,我們認爲其最爲突出的創新之處在於:1)LDM自編碼器實現時間維度壓縮,使得長視頻生成成爲可能;2)直接對LDM中潛視頻進行圖塊化處理並直接使用Transformer建模,解除輸入格式限制的同時,能夠創新性地實現任何像素和長寬比視頻的生成;3)我們判斷其訓練數據集中可能包含帶有物理信息的合成數據,從而使模型展現出對物理信息的初步理解能力;4)復用DALL·E 3的重標注技術,對視頻數據生成高質量文字標注,借助GPT對提示詞進行擴展,提升生成效果。
圖表:Sora潛在的模型架構
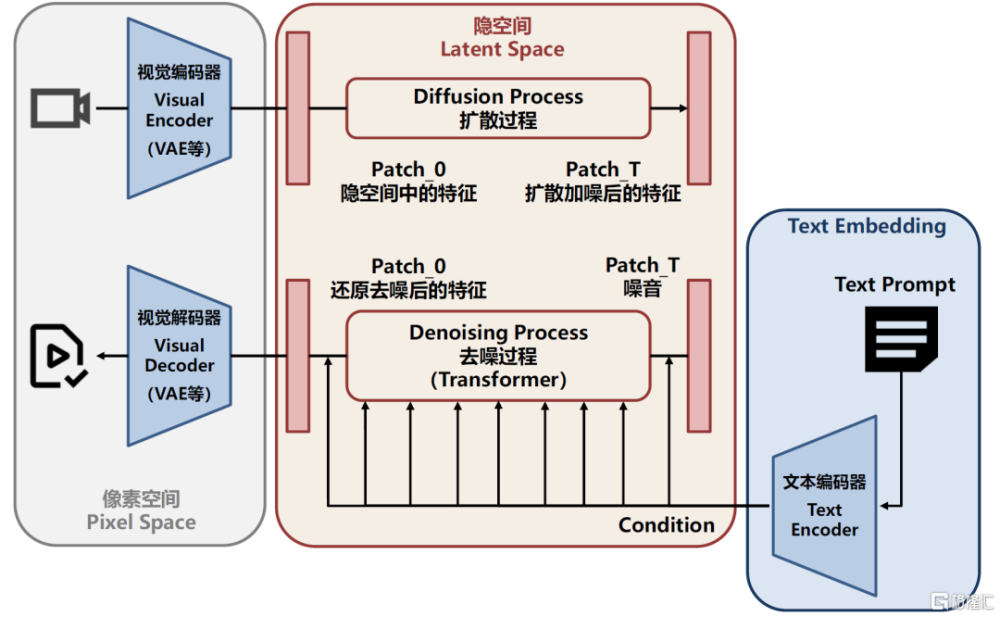
資料來源:Sora技術報告,中金公司研究部
潛在的模型架構:以DiTs爲核心,展現出優異的可拓展性。根據Sora的技術報告,其整體延續了DiTs(Diffusion transformer)架構,將Transformer引入潛在擴散模型(Latent diffusion model)實現良好的可拓展性。技術報告展示了伴隨模型擴大和訓練次數增加而產生的規模效應(Diffusion transformers scale effectively)。從架構上來看,我們判斷Sora可能主要由幾部分組成:
► Visual Encoder/Decoder(如VAE等):Encoder將原始圖片和視頻數據編碼進入隱空間,降低維數節省算力;Decoder將潛空間中的數據重新映射爲圖片和視頻數據。
► DiTs模塊(基於Transformer的擴散模型):模型的核心,將擴散模型的骨幹U-Net卷積網絡替換爲可伸縮性更強的Transformer,展現出優異的可拓展性。
► Text embedding:將用戶輸入的Prompt編碼爲文本嵌入向量,作爲DiTs模塊的Conditioning,引導模型生成符合文本描述的視頻。
圖表:Sora展現了明顯的可拓展性(Scalable),伴隨訓練計算量增加而性能明顯提升

資料來源:Sora技術報告,中金公司研究部
Sora的技術報告展示了數據處理和模型訓練過程中創新,我們歸納總結如下:
► 在Visual Encoder/Decoder階段,訓練了新的視頻壓縮網絡:OpenAI訓練了新的視頻壓縮網絡(Video compression network)對原始視頻數據在時間和空間上實現降維編碼(Encoder),並訓練了相應的解碼器(Decoder)實現潛空間(Latent space)到視頻像素空間(Pixel space)的映射;我們認爲時間維度上的壓縮可能是Sora能夠生成較長視頻的原因之一。
► 在DiTs階段,將視頻數據圖塊化爲Patches:類比基於Transformer的大語言模型(LLM)需要處理文本Tokens,基於Transformer的圖片和視頻模型也需要以分塊數據作爲處理對象,其將隱空間視頻分割爲“視覺圖塊(Visual patches)”作爲視頻數據的有效表示。我們認爲以上處理方法與W.A.L.T.論文基於關鍵幀+空間/時空窗口的方法或存在較大差異,通過直接對潛視頻空間中的數據進行直接圖塊化處理,Sora能夠處理任意分辨率、任意長寬比、任意時長的視頻,這一特性與主流的視頻生成模型相比具備優勢(主流視頻生成模型需要對視頻進行縮放和裁剪)。
► 復用DALL·E 3重標注技術,實現高質量視頻標注:在文字理解層面,Sora沒有基於人工標注的圖片-文字數據集進行訓練,而是復用了OpenAI自家的DALL·E 3的重標注技術(re-captioning),訓練了高質量的視頻標注器,並對訓練集中的視頻生成了文字標注。此外,Sora還發揮了OpenAI的GPT的優勢,能夠將用戶給出的較短的提示詞擴展爲較長的提示詞作爲視頻模型的輸入,實現更好的生成效果。
圖表:Sora將視頻單元劃分爲Patches,實現類似LLM模型中的Tokens角色
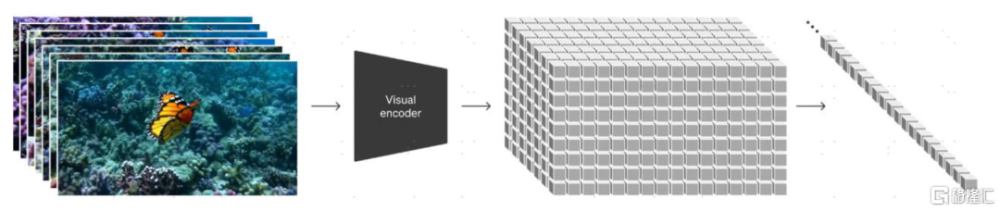
資料來源:Sora技術報告,中金公司研究部
圖表:Sora本質是擴散模型,通過Transformer去噪生成“幹淨”的Patches

資料來源:Sora技術報告,中金公司研究部
Transformer架構或充分發揮了OpenAI在算力和數據等領域的全方面優勢。整體來看,我們認爲Sora在架構層面還是延續了DiTs(Diffusion transformer),在潛視頻空間編解碼、圖塊劃分等領域或具備一定的創新。我們認爲Transformer架構的高擴展性充分發揮了OpenAI在算力(借助微軟的龐大算力群)、數據(具備高質量的有標注視頻數據集)的優勢,在視頻生成場景下實現了類似LLM領域的“GPT時刻”。
模型仍具備提升空間,視頻內容生成門檻有望大幅降低。模型也展現出了一定程度的不足,如模型對物理關系的理解能力不高(如玻璃破碎無法很好展現),以及模型生成視頻的因果邏輯仍有待驗證。盡管如此,我們認爲Sora打开了通過堆疊參數和數據規模實現性能提升的通道,我們判斷基於DiTs架構的視頻生成模型或成爲下一階段的主流技術,有望通過數據積累和參數規模上升實現持續的性能提升。伴隨模型能力越來越強,我們認爲高質量視頻內容生成成本和視頻創作門檻或將大幅降低;同時,我們判斷模型對物理信息的學習和提取也有望越來越強,未來在智能駕駛、具身智能等領域也有望實現應用突破。
視頻生成模型技術回顧:以擴散模型爲基,從U-Net到Transformer
擴散模型:圖片和視頻生成模型的骨幹
擴散模型是圖片/視頻生成模型的核心技術。擴散模型(Diffusion model)通過神經網絡(主要是U-Net)從純噪聲圖像中學習去噪過程,從而通過給定噪聲來完成圖像生成任務。潛在擴散模型(Latent diffusion model)則進一步將擴散模型優化,將圖像編碼壓縮到維度較小的隱空間進行擴散學習過程,再通過解碼器還原至圖片,是目前主流的圖片生成模型(如Stable Diffusion、DALL·E 3等)的骨幹。
圖表:擴散模型原理示意圖
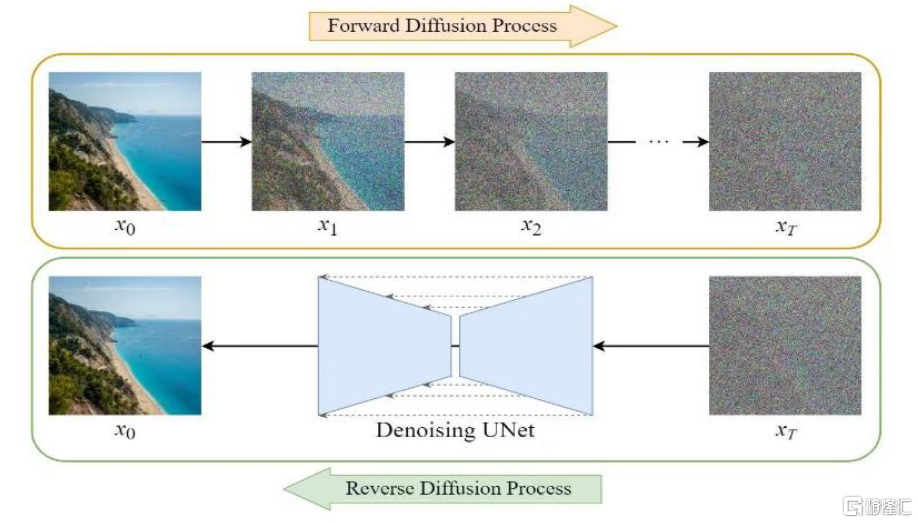
資料來源:Medium平台,中金公司研究部
視頻本質上是一系列圖像的連續展示,圖片生成是視頻生成的基礎。視頻本質上是一系列有前後邏輯關系的圖片的連續展示,因此圖片生成是視頻生成的基礎。目前主流的視頻生成模型的技術路线爲基於圖片生成模型進行微調,通過生成一些“關鍵幀”並在關鍵幀之間進行插值和時序對齊,從而達到視頻生成的效果。Blattmann等(2023)提出可以基於預訓練好的文生圖模型引入時間層,通過在視頻數據上進行微調,將圖片生成模型轉化爲視頻生成模型。
圖表:通過時序對齊,圖片生成模型可以訓練爲視頻生成模型
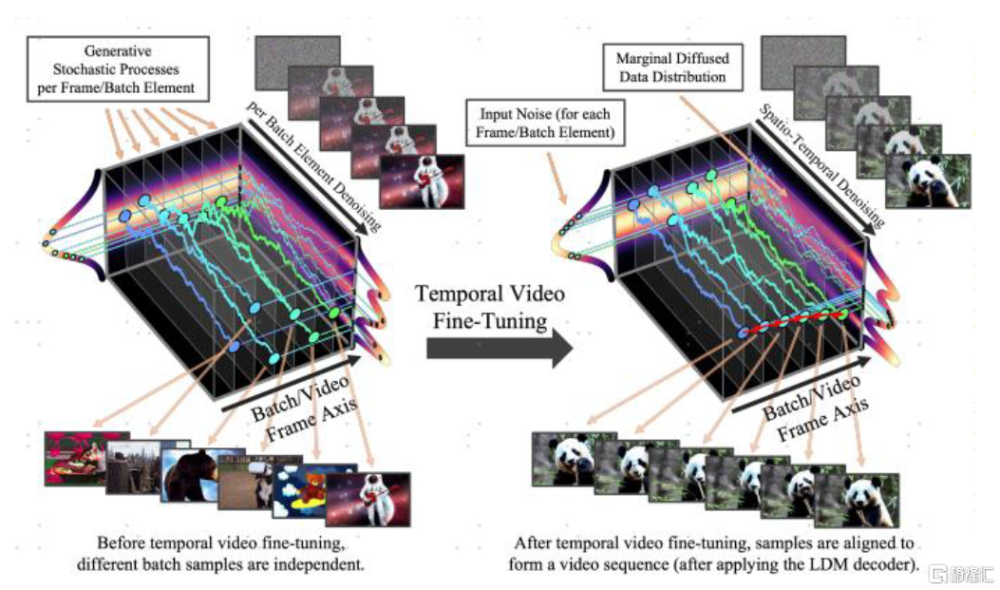
資料來源:《Align your Latents: High-Resolution Video Synthesis with Latent Diffusion Models》(Blattmann等, 2023),中金公司研究部
基於U-Net的擴散模型在信息損失和輸入多樣性方面具備一系列缺點。U-Net模型核心是卷積神經網絡,這導致U-Net在圖片生成過程中具備一些天然的缺點:1)U-Net的下採樣過程會造成信息的損失;2)卷積神經網絡要求輸入的圖片具有固定的分辨率,對輸入的限制也造成了輸出格式的限制(只能生成固定長寬比、固定分辨率的圖片),模型的可拓展性較弱。
先前的視頻生成模型在像素穩定性和邏輯一致性等方面仍存在提升空間。我們總結先前的擴散模型存在較爲一致的共性問題,主要包括:
► 畫面像素和穩定性:模型生成的視頻普遍像素較低,且部分關鍵幀可能存在風格偏移,導致視頻畫面出現“閃爍”;
► 邏輯連續性:視頻前後的圖像可能存在邏輯混亂,尤其是在長視頻生成任務過程中,較難保證視頻前後的邏輯一致性;
► 生成時長較短:多數視頻生成類模型和應用只能生成3-4秒鐘的視頻,時間過長可能會導致視頻的風格遷移或前後邏輯混亂;
► 缺乏高質量數據集:公开的視頻缺少標籤、缺乏多樣性,相較LLM可以在Common crawl訓練,圖片生成模型可以在ImageNet上訓練,目前還沒有大型的可以用於視頻訓練的數據。
圖表:視頻生成類AI大模型和產品進度,截至2023年底
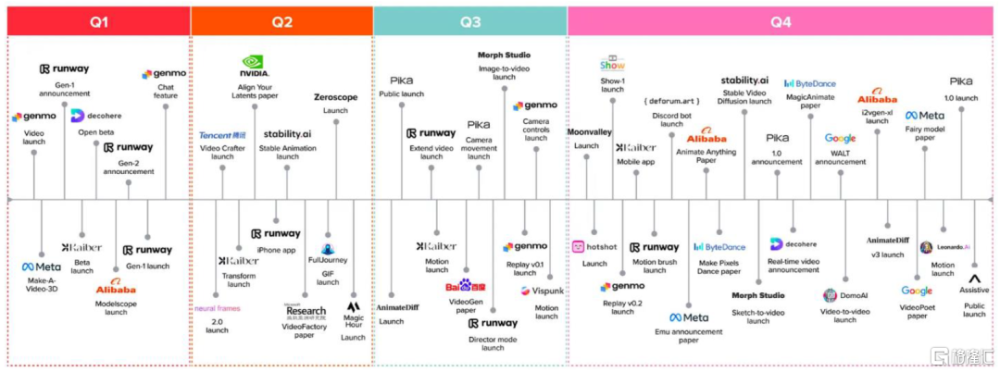
資料來源:a16z,中金公司研究部
DiTs:將Transformer架構引入擴散模型,模型可拓展性大幅增強
DiTs(Diffusion transformer)將Transformer架構引入擴散模型。2022年底,Peebles和Xie發表論文《Scalable Diffusion Models with Transformers》,將Transformer架構引入擴散模型,在圖片生成任務中表現出色。其核心是將先前擴散模型的骨幹U-Net卷積網絡替換爲可伸縮性更強的Transformer,從而能夠實現更強的可拓展性,即能夠通過增加參數規模和訓練數據量來快速提升模型的性能表現(類似GPT,實現“大力出奇跡”)。另一方面,由於Transformer的全注意力機制產生的內存需求會隨着輸入序列的長度增加而呈現平方增長,因此處理高維信號(如視頻)時,模型對計算成本的要求也會相應較高。
圖表:DiTs模型架構
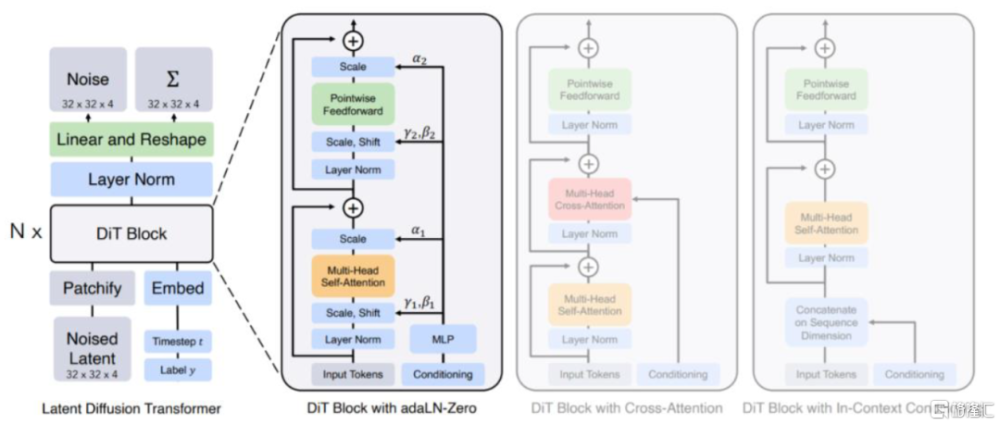
資料來源:《Scalable Diffusion Models with Transformers》(Peebles和Xie,2022),中金公司研究部
W.A.L.T.首次將Transformer引入視頻生成模型。2023年底,Gupta等發表論文《Photorealistic Video Generation with Diffusion models》,將Transformer架構整合到隱視頻擴散模型(Latent video diffusion model, LVDM)中,主要工作有兩項:
► 第一階段:用一個自動編碼器將視頻和圖像映射到一個統一的低維隱視頻空間,使得在圖像和視頻數據集上聯合訓練單個生成模型成爲可能,並顯著降低生成高分辨率視頻的計算成本;
► 第二階段:設計了一種用於隱視頻擴散模型的新Transformer模塊,對隱空間中的視頻幀進行分塊(Patchify),使用局部窗口注意力顯著降低計算需求。模型引入了兩種局部窗口,分別爲:1)空間窗口(SW)學習單個關鍵幀裏面的位置關系;2)時空窗口(STW)學習關鍵幀之間的時序關系。
W.A.L.T.开創性地將Transformer架構引入視頻生成任務中,同時使用窗口注意力(而非全注意力)降低了高維視頻信號對算力的需求,讓Transformer處理視頻數據得以實現。
圖表:W.A.L.T.模型首次實現將Transformer架構引入視頻生成模型
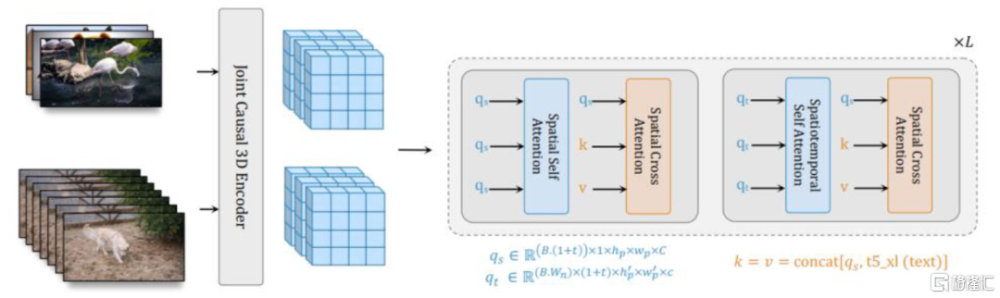
資料來源:《Photorealistic Video Generation with Diffusion models》(Gupta等,2023),中金公司研究部
本文摘自:2024年2月19日已經發布的《AI動態跟蹤:從OpenAI Sora看視頻生成模型技術進展》
於鐘海 分析員 SAC 執證編號:S0080518070011 SFC CE Ref:BOP246
王之昊 分析員 SAC 執證編號:S0080522050001 SFC CE Ref:BSS168
魏鸛霏 分析員 SAC 執證編號:S0080523060019 SFC CE Ref:BSX734
譚哲賢 聯系人 SAC 執證編號:S0080122070047
遊航 分析員 SAC 執證編號:S0080523010001 SFC CE Ref:BTI822
標題:中金:從OpenAI Sora看視頻生成模型技術進展
地址:https://www.iknowplus.com/post/82394.html







