GPU的歷史性時刻!
8月23日,GPU巨頭Nvidia發布了2023年二季度財報,其結果遠超預期。總體來說,Nvidia二季度的收入達到了135億美元,相比去年同期增長了101%;淨利潤達到了61億美元,相比去年同期增長了843%。Nvidia公布的這一驚人的財報一度在盤後讓Nvidia股票大漲6%,甚至還帶動了衆多人工智能相關的科技股票在盤後跟漲。
Nvidia收入在二季度如此大漲,主要靠的就是目前方興未艾的人工智能風潮。ChatGPT爲代表的大模型技術從去年第三季度以來,正在得到全球幾乎所有互聯網公司的追捧,包括美國硅谷的谷歌、亞馬遜以及中國的百度、騰訊、阿裏巴巴等等巨頭。而這些大模型能進行訓練和推理的背後,都離不开人工智能加速芯片,Nvidia的GPU則是大模型訓練和推理加速目前的首選方案。由於個大科技巨頭以及初創公司都在大規模購买Nvidia的A系列和H系列高端GPU用於支持大模型訓練算力,這也造成了Nvidia的數據中心GPU供不應求,當然這反映到財報中就是收入和淨利潤的驚人增長。
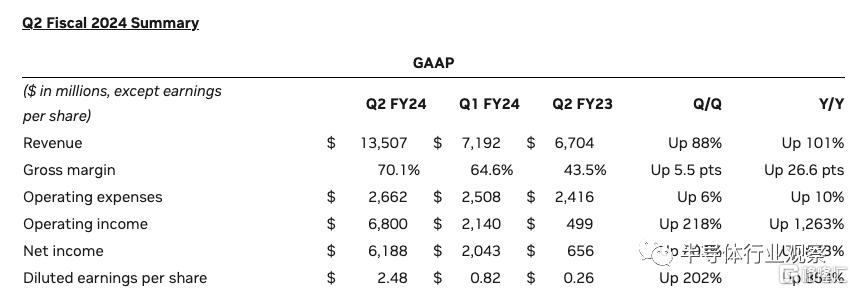
事實上,從Nvidia的財報中,除了亮眼的收入和淨利潤數字之外,還有一個關鍵的數字值得我們關注,就是Nvidia二季度的數據中心業務收入。根據財報,Nvidia二季度的數據中心業務收入超過了100億美元,相比去年同期增長171%。Nvidia數據中心業務數字本身固然非常驚人,但是如果聯系到其他公司的同期相關收入並進行對比,我們可以看到這個數字背後更深遠的意義。同樣在2023年第二季度,Intel的數據中心業務收入是40億美元,相比去年同期下降15%;AMD的數據中心業務收入是13億美元,相比去年同期下降11%。我們從中可以看到,在數據中心業務的收入數字上,Nvidia在2023年第二季度的收入已經超過了Intel和AMD在相同市場收入的總和。
這樣的對比的背後,體現出了在人工智能時代,人工智能加速芯片(GPU)和通用處理器芯片(CPU)地位的反轉。目前,在數據中心,人工智能加速芯片/GPU事實上最主流的供貨商就是Nvidia,而通用處理器芯片/CPU的兩大供貨商就是Intel和AMD,因此比較Nvidia和Intel+AMD在數據中心領域的收入數字就相當於比較GPU和CPU之間的出貨規模。雖然人工智能從2016年就开始火熱,但是在數據中心,人工智能相關的芯片和通用芯片CPU相比,獲得的市場份額增長並不是一蹴而就的:在2023年之前,數據中心CPU的份額一直要遠高於GPU的份額;甚至在2023年第一季度,Nvidia在數據中心業務上的收入(42億美元)仍然要低於Intel和AMD在數據中心業務的收入總和;而在第二季度,這樣的力量對比反轉了,在數據中心GPU的收入一舉超過了CPU的收入。
這也是一個歷史性的時刻。從上世紀90年代PC時代开始,CPU一直是摩爾定律的領軍者,其輝煌從個人電腦時代延續到了雲端數據中心時代,同時也推動了半導體領域的持續發展;而在2023年,隨着人工智能對於整個高科技行業和人類社會的影響,用於通用計算的CPU在半導體芯片領域的地位正在讓位於用於人工智能加速的GPU(以及其他相關的人工智能加速芯片)。
摩爾定律的故事在GPU上仍然在發生
衆所周知,CPU的騰飛離不开半導體摩爾定律。根據摩爾定律,半導體工藝特徵尺寸每18個月演進一代,同時晶體管的性能也得大幅提升,這就讓CPU在摩爾定律的黃金時代(上世紀80年代至本世紀第一個十年)突飛猛進:一方面CPU性能每一年半就迭代一次,推動新的應用出現,另一方面新的應用出現又進一步推動對於CPU性能的需求,這樣兩者就形成了一個正循環。這樣的正循環一直到2010年代,隨着摩爾定律逐漸接近物理瓶頸而慢慢消失——我們可以看到,最近10年中,CPU性能增長已經從上世紀8、90年代的15%年復合增長率(即性能每18個月翻倍)到了2015年後的3%年復合增長率(即性能需要20年才翻倍)。
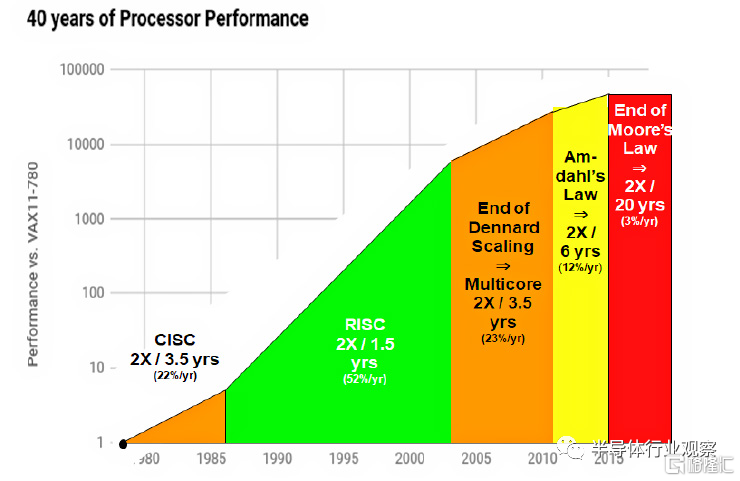
但是,摩爾定律對於半導體晶體管性能增長的驅動雖然已經消失,但是摩爾定律所預言的性能指數級增長並沒有消失,而是從CPU轉到了GPU上。如果我們看2005年之後GPU的性能(算力)增長,我們會發現它事實上一直遵循了指數增長規律,大約2.2年性能就會翻倍!
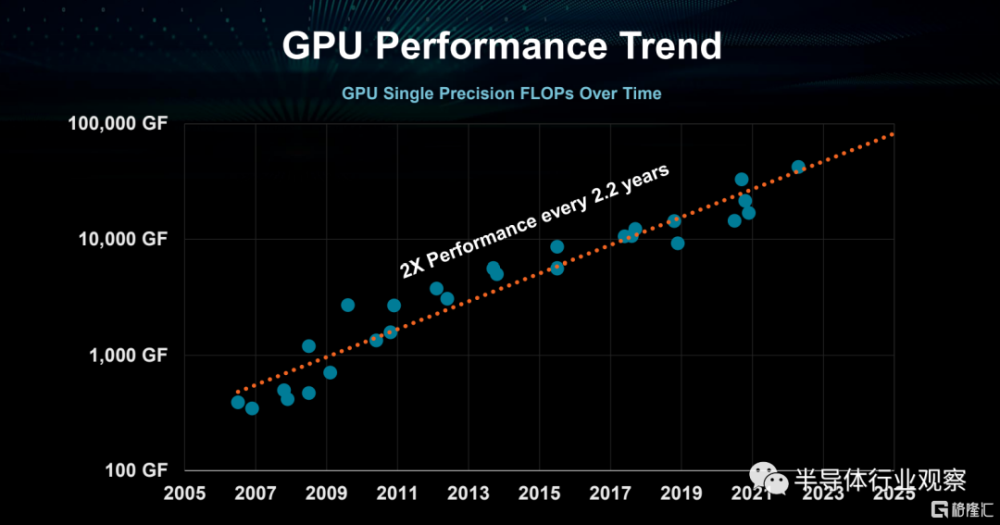
同樣是芯片,爲什么GPU能延續指數級增長?這裏,我們可以從需求和技術支撐兩方面來分析:需求意味着市場上是不是有應用對於GPU的性能指數級增長有強大的需求?而技術支撐則是,從技術上有沒有可能實現指數級性能增長?
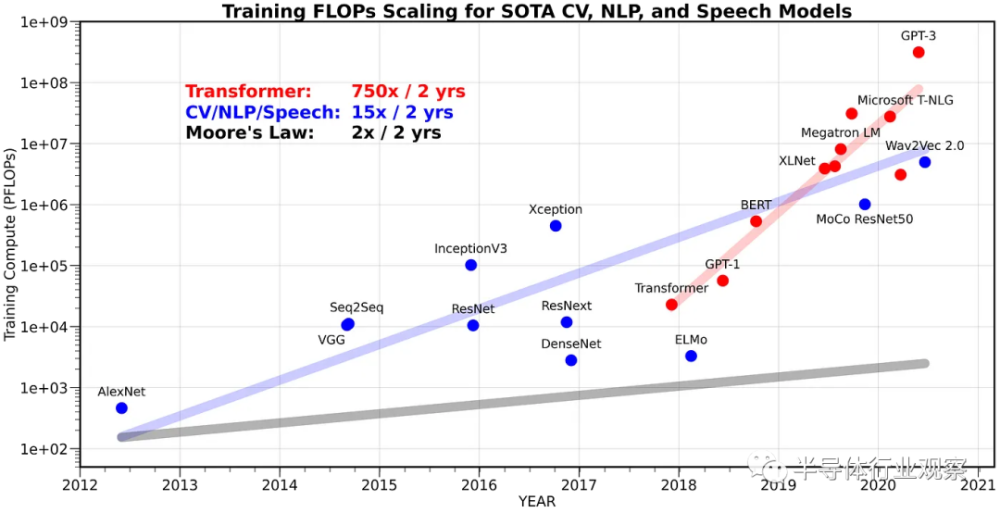
從需求上來說,人工智能確實存在着這樣強烈需求。我們可以看到,從2012年(神經網絡人工智能復興怨念开始)到至今,人工智能模型的算力需求確實在指數級增長。2012年到2018年是卷積神經網絡最流行的年份,在這段時間裏我們看到人工智能模型的算力需求增長大約是每兩年15倍。在那個時候,GPU主要負責的是模型訓練,而在推理部分GPU的性能一般都是綽綽有余。而從2018年進入以Transformer架構爲代表的大模型時代後,人工智能模型對於算力需求的演進速度大幅提升,已經到了每兩年750倍的地步。在大模型時代,即使是模型的推理也離不开GPU,甚至單個GPU都未必能滿足推理的需求;而訓練更是需要數百塊GPU才能在合理的時間內完成。這樣的性能需求增長速度事實上讓GPU大約每兩年性能翻倍的速度都相形見拙,事實上目前GPU性能提升速度還是供不應求!因此,如果從需求側去看,GPU性能指數級增長的曲线預計還會延續很長一段時間,在未來十年內GPU很可能會從CPU那邊接過摩爾定律的旗幟,把性能指數級增長的神話續寫下去。
GPU性能指數增長背後的技術支撐
除了需求側之外,爲了能讓GPU性能真正維持指數增長,背後必須有相應的芯片技術支撐。我們認爲,在未來幾年內,有三項技術將會是GPU性能維持指數級增長背後的關鍵。
第一個技術就是領域專用(domain-specific)芯片設計。同樣是芯片,GPU性能可以指數級增長而CPU卻做不到,其中的一個重要因素就是GPU性能增長不僅僅來自於晶體管性能提升和電路設計改進,更來自於使用領域專用設計的思路。例如,在2016年之前,GPU支持的計算主要是32位浮點數(fp32),這也是在高性能計算領域的默認數制;但是在人工智能興起之後,研究表明人工智能並不需要32位浮點數怎么高的精度,而事實上16位浮點數已經足夠用於訓練,而推理使用8位整數甚至4位整數都夠了。而由於低精度計算的开銷比較小,因此使用領域專用計算的設計思路,爲這樣的低精度計算做專用優化可以以較小的代價就實現人工智能領域較大的性能提升。從Nvidia GPU的設計我們可以看到這樣的思路,我們看到了計算數制方面在過去的10年中從fp32到fp16到int8和int4的高效支持,可以說是一種低成本快速提高性能的思路。除此之外,還有對於神經網絡的支持(TensorCore),稀疏計算的支持,以及Transformer的硬件支持等等,這些都是領域專用設計在GPU上的很好體現。在未來,GPU性能的提升中,可能是有很大一部分來自於這樣的領域專用設計,往往一兩個專用加速模塊的引入就能打破最新人工智能模型的運行瓶頸來大大提升整體性能,從而實現四兩撥千斤的效果。
第二個技術就是高級封裝技術。高級封裝技術對於GPU的影響來自兩部分:高速內存和更高的集成度。在大模型時代,隨着模型參數量的進一步提升,內存訪問性能對於GPU整體性能的影響越來越重要——即使GPU芯片本身性能極強,但是內存訪問速度不跟上的話,整體性能還是會被內存訪問帶寬所限制,換句話說就是會遇到“內存牆”問題。爲了避免內存訪問限制整體性能,高級封裝是必不可少的,目前的高帶寬內存訪問接口(例如已經在數據中心GPU上廣泛使用的HBM內存接口)就是一種針對高級封裝的標准,而在未來我們預期看到高級封裝在內存接口方面起到越來越重要的作用,從而助推GPU性能的進一步提升。高級封裝對於GPU性能提升的另一方面來自於更高的集成度。最尖端半導體工藝(例如3nm和以下)中,隨着芯片規模變大,芯片良率會遇到挑战,而GPU可望是未來芯片規模提升最激進的芯片品類。在這種情況下,使用芯片粒將一塊大芯片分割成多個小芯片粒,並且使用高級封裝技術集成到一起,將會是GPU突破芯片規模限制的重要方式之一。目前,AMD的數據中心GPU已經使用上了芯片粒高級封裝技術,而Nvidia預計在不久的未來也會引入這項技術來進一步繼續提升GPU芯片集成度。
最後,高速數據互聯技術將會進一步確保GPU分布式計算性能提升。如前所述,大模型的算力需求提升速度是每兩年750倍,遠超GPU摩爾定律提升性能的速度。這樣,單一GPU性能趕不上模型算力需求,那么就必須用數量來湊,即把模型分到多塊GPU上進行分布式計算。未來幾年我們可望會看到大模型使用越來越激進的分布式計算策略,使用數百塊,上千塊甚至上萬塊GPU來完成訓練。在這樣的大規模分布式計算中,高速數據互聯將會成爲關鍵,否則不同計算單元之間的數據交換將會成爲整體計算的瓶頸。這些數據互聯包括近距離的基於電氣互聯的SerDes技術:例如在Nvidia的Grace Hopper Superchip中,使用NVLINK C2C做數據互聯,該互聯可以提供高達900GB/s的數據互聯帶寬(相當於x16 PCIe Gen5的7倍)。另一方面,基於光互聯的長距離數據互聯也會成爲另一個核心技術,當分布式計算需要使用成千上萬個計算節點的時候,這樣的長距離數據交換也會變得很常見並且可能會成爲系統性能的決定性因素之一。
我們認爲,在人工智能火熱的年代,GPU將會進一步延續摩爾定律的故事,讓性能指數級發展繼續下去。爲了滿足人工智能模型對於性能強烈的需求,GPU將會使用領域專用設計、高級封裝和高速數據互聯等核心技術來維持性能的快速提升,而GPU以及它所在的人工智能加速芯片也將會成爲半導體領域技術和市場進步的主要推動力。
標題:GPU的歷史性時刻!
地址:https://www.iknowplus.com/post/27350.html







