黃仁勳剛剛發布,英偉達最強GPU B200,首次採用Chiplet?
遙想2023年3月,英偉達舉行了GTC 2023主題演講,英偉達CEO黃仁勳不僅闡述了該公司在人工智能時代的諸多成就和對未來發展愿景的期待,同時也帶來Grace Hopper超級芯片、AI Foundations雲服務、AI超級計算服務DGX Cloud、全球首個GPU加速量子計算系統等在內的多款重磅硬件新品。
而在北京時間2024年3月19日上午,英偉達再次舉辦了一年一度的 NVIDIA GTC主題演講,英偉達CEO 黃仁勳通過這次演講,分享了新一代的AI突破,也讓各位觀衆見證了AI的又一次變革時刻。

穿着熟悉皮衣的黃仁勳自然是這場演講裏的主角,“世界上沒有哪一個會議有如此多樣化的研究人員,其中有大量的生命科學、醫療保健、零售、物流公司等等,”他說,“全球價值 100 萬億美元的公司都聚集在 GTC。”
黃仁勳表示:“我們已經到了一個臨界點,我們需要一種新的計算方式......加速計算是一種巨大的提速。所有的合作夥伴都要求更高的功率和效率,那么英偉達能做些什么呢?”
下一代AI平台——Blackwell
隨後登場的是Blackwell B200,一個更大的GPU,其命名來自於大衛·哈羅德·布萊克威爾他是一位專門研究博弈論和統計學的數學家,也是第一位入選美國國家科學院的黑人學者。
據英偉達介紹,B200的尺寸是“人工智能超級芯片”Hopper 的兩倍,集成有 2080 億個晶體管,其採用定制的兩掩模版極限 N4P TSMC 工藝制造,GPU 芯片通過 10TBps 芯片到芯片鏈路連接成爲單個GPU。這在上面有兩個讓人好奇的點:
首先,從技術上講,雖然他們使用的是新節點 - TSMC 4NP - 但這只是用於 GH100 GPU 的 4N 節點的更高性能版本。這也讓英偉達多年來第一次無法利用主要新節點的性能和密度優勢。這意味着 Blackwell 的幾乎所有效率增益都必須來自架構效率,而該效率和橫向擴展的絕對規模的結合將帶來 Blackwell 的整體性能增益。

其次,從字面上我們可以看到,這個全新旗艦將在單個封裝上配備兩個 GPU 芯片。換而言之,NVIDIA 終於在他們的旗艦加速器實現了Chiplet化。雖然他們沒有透露單個芯片的尺寸,但我們被告知它們是“reticle-sized”的芯片,每個芯片的面積應該超過 800mm2。GH100 芯片本身已經接近台積電的 4 納米掩模版極限,因此 NVIDIA 在此方面的增長空間很小 - 至少不能停留在單個芯片內。
黃仁勳指出:“人們認爲我們制造GPU,但GPU的外觀和以前不一樣了。”
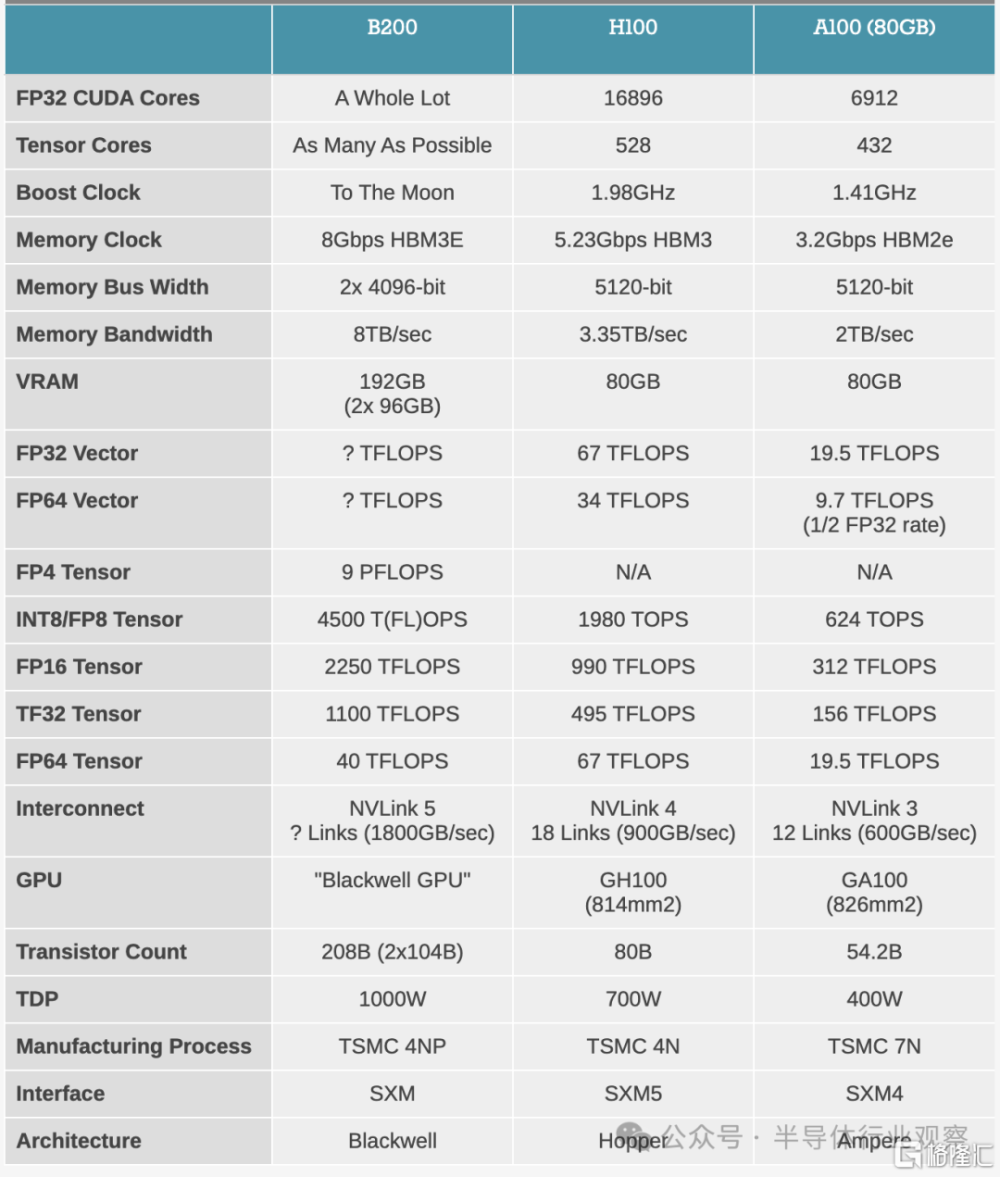
英偉達表示,新的 B200 GPU 通過其 2080 億個晶體管提供高達 20 petaflops的 FP4 性能,配備 192GB HBM3e 內存,提供高達 8 TB/s 的帶寬。

對於他們的首款多芯片芯片,NVIDIA 打算跳過尷尬的“一個芯片上有兩個加速器”階段,直接讓整個加速器像單個芯片一樣運行。據 NVIDIA 稱,這兩個芯片作爲“一個統一的 CUDA GPU”運行,可提供完整的性能,毫不妥協。其關鍵在於芯片之間的高帶寬 I/O 鏈路,NVIDIA 將其稱爲 NV 高帶寬接口 (NV-HBI:NV-High Bandwidth Interface ),並提供 10TB/秒的帶寬。據推測,這是總計,這意味着芯片可以在每個方向上同時發送 5TB/秒。
由於英偉達迄今尚未詳細說明此鏈接的構建,所以我們不清楚NVIDIA 是否始終依賴晶圓上芯片 (如CoWoS)還是使用基礎芯片策略 (如AMD MI300),或者是否依賴在一個單獨的本地中介層上,僅用於連接兩個芯片(例如 Apple 的 UltraFusion)。不管怎樣,英偉達這個方案比我們迄今爲止看到的任何其他雙芯片橋接解決方案的帶寬都要大得多,這意味着有大量的引腳在發揮作用。
在 B200 上,每個芯片與 4 個 HBM3E 內存堆棧配對,總共 8 個堆棧,形成 8192 位的有效內存總线寬度。所有人工智能加速器的限制因素之一是內存容量(也不要低估對帶寬的需求),因此能夠放置更多堆棧對於提高加速器的本地內存容量非常重要。
總的來說,B200 提供 192GB 的 HBM3E,即 24GB/堆棧,與 H200 的 24GB/堆棧容量相同(並且比原來的 16GB/堆棧 H100 多出 50% 的內存)。
據 NVIDIA 稱,該芯片的 HBM 內存總帶寬爲 8TB/秒,每個堆棧的帶寬爲 1TB/秒,即每個引腳的數據速率爲 8Gbps。正如我們之前所說,內存最終設計爲每針 9.2Gbps 或更高,但我們經常看到 NVIDIA 在其服務器加速器的時鐘速度上表現得有點保守。不管怎樣,這幾乎是 H100 內存帶寬的 2.4 倍(或者比 H200 高出 66%),因此 NVIDIA 看到了帶寬的顯著增加。
最後,目前我們還沒有關於單個 B200 加速器的 TDP 的任何信息。毫無疑問,它會很高——在後登納德世界中,你不可能將晶體管增加一倍以上,而不付出某種功率損失。NVIDIA 將同時銷售風冷 DGX 系統和液冷 NVL72 機架,因此 B200 並不超出風冷範圍,但在 NVIDIA 確認之前,我預計數量不會少。
總體而言,與集群級別的H100 相比,NVIDIA 的目標是將訓練性能提高 4 倍,將推理性能提高 30 倍,同時能源效率提高 25 倍。我們將在此過程中介紹其背後的一些技術,並且更多有關 NVIDIA 打算如何實現這一目標的信息無疑將在主題演講中披露。
但這些目標最有趣的收獲是幹擾性能的提高。NVIDIA 目前在訓練領域佔據主導地位,但推理市場是一個更廣泛、競爭更激烈的市場。然而,一旦這些大型模型經過訓練,就需要更多的計算資源來執行它們,NVIDIA 不想被排除在外。但這意味着要找到一種方法,在競爭更加激烈的市場中取得(並保持)令人信服的領先地位,因此 NVIDIA 的工作任務艱巨。
與 Hopper 系列一樣,Blackwell 也有“超級芯片”提供——兩個 B200 GPU 和一個 Nvidia Grace CPU,芯片間鏈路速度爲 900GBps。英偉達表示,與 Nvidia H100 GPU 相比,GB200 Superchip 在 LLM 推理工作負載方面的性能提高了 30 倍,並將成本和能耗降低了 25 倍。
最後,還將推出 HGX B100。它的基本理念與 HGX B200 相同,配備 x86 CPU 和 8 個 B100 GPU,只不過它設計爲與現有 HGX H100 基礎設施直接兼容,並允許最快速地部署 Blackwell GPU。每個 GPU 的 TDP 限制爲 700W,與 H100 相同,吞吐量下降至 FP4 的 14 petaflops。
除了紙面性能的提升外,Blackwell還支持了第二代 Transformer 引擎,它通過爲每個神經元使用 4 位而不是 8 位,使計算、帶寬和模型大小加倍,而配備的第五代 NVLink能夠爲每個 GPU 提供 1.8TB/s 雙向吞吐量,確保多達 576 個 GPU 之間的無縫高速通信。

英偉達還公布了由GB200驅動的GB200 NVL72,這是一個多節點、液冷、機架式系統,適用於計算最密集的工作負載。它結合了36個Grace Blackwell超級芯片,其中包括72個Blackwell GPU和36個Grace CPU,通過第五代NVLink互連。
新的 NVLink 芯片具有 1.8 TB/s 的全對全雙向帶寬,支持 576 個 GPU NVLink 域。它是在同一台積電 4NP 節點上制造的 500 億個晶體管芯片。該芯片還支持 3.6 teraflops 的 Sharp v4 片上網絡計算,這有助於高效處理更大的模型。
上一代支持高達 100 GB/s 的 HDR InfiniBand 帶寬,因此這是帶寬的巨大飛躍。與 H100 多節點互連相比,新的 NVSwitch 速度提高了 18 倍。這應該能夠顯着改善更大的萬億參數模型人工智能網絡的擴展性。
與此相關的是,每個 Blackwell GPU 都配備了 18 個第五代 NVLink 連接。這是 H100 鏈接數量的十八倍。每個鏈路提供 50 GB/s 的雙向帶寬,或每個鏈路 100 GB/s
此外,GB200 NVL72還包括NVIDIA BlueField-3數據處理單元,可在超大規模人工智能雲中實現雲網絡加速、可組合存儲、零信任安全和GPU計算彈性。與相同數量的英偉達H100 Tensor Core GPU相比,GB200 NVL72在LLM推理工作負載方面的性能最多可提升30倍,成本和能耗最多可降低25倍。

在演講中,亞馬遜、谷歌、Meta、微軟、甲骨文雲和 OpenAI 等公司確認將在今年晚些時候部署 Blackwell GPU。
“Blackwell 提供了巨大的性能飛躍,並將加快我們交付領先模型的能力。我們很高興繼續與 Nvidia 合作增強 AI 計算能力。”OpenAI 首席執行官 Sam Altman 說道。
特斯拉和 xAI 首席執行官埃隆·馬斯克 (Elon Musk) 補充道:“目前沒有什么比 Nvidia 的人工智能硬件更好的了。”
下一代AI超算——DGX SuperPOD
在發布Blackwell GPU後,英偉達還推出了下一代AI超級計算機——由 NVIDIA GB200 Grace Blackwell 超級芯片提供支持的 NVIDIA DGX SuperPOD,用於處理萬億參數模型,並具有持續的正常運行時間,以實現超大規模生成式 AI 訓練和推理工作負載。
據英偉達介紹,新型 DGX SuperPOD 採用新型高效液冷機架規模架構,採用 NVIDIA DGX™ GB200 系統構建,可在 FP4 精度下提供 11.5 exaflops 的 AI 超級計算能力和 240 TB 的快速內存,可通過額外的機架擴展到更多。

每個 DGX GB200 系統均配備 36 個 NVIDIA GB200 超級芯片,其中包括 36 個 NVIDIA Grace CPU 和 72 個 NVIDIA Blackwell GPU,通過第五代NVIDIA NVLink®連接爲一台超級計算機。與 NVIDIA H100 Tensor Core GPU 相比,GB200 Superchips 對於大型語言模型推理工作負載的性能提升高達 30 倍。
NVIDIA 創始人兼首席執行官黃仁勳表示:“NVIDIA DGX AI 超級計算機是 AI 工業革命的工廠。” “新的 DGX SuperPOD 結合了 NVIDIA 加速計算、網絡和軟件的最新進展,使每個公司、行業和國家都能完善和生成自己的人工智能。”
下一代AI網絡交換機——X800
英偉達還在演講中發布了專爲大規模人工智能而設計的新一代網絡交換機 X800 系列。
英偉達表示,NVIDIA Quantum-X800 InfiniBand和 NVIDIA Spectrum-X800 Ethernet是全球首款能夠實現端到端 800Gb/s 吞吐量的網絡平台, 突破了計算和 AI 工作負載網絡性能的界限。它們配備的軟件可進一步加速各類數據中心中的人工智能、雲、數據處理和 HPC 應用程序,包括那些採用新發布的基於 NVIDIA Blackwell 架構的產品系列的數據中心。

具體而言,Quantum-X800 平台包括英偉達Quantum Q3400交換機和英偉達ConnectX-8 SuperNIC,共同實現了業界領先的800Gb/s端到端吞吐量。與上一代產品相比,帶寬容量提高了 5 倍,利用英偉達可擴展分級聚合和縮減協議(SHARPv4)進行的網內計算能力提高了 9 倍,達到 14.4Tflops。
Spectrum-X800平台爲人工智能雲和企業基礎設施提供了優化的網絡性能。利用SpectrumSN5600 800Gb/s交換機和英偉達BlueField-3超級網卡,Spectrum-X800平台可提供對多租戶生成式人工智能雲和大型企業至關重要的高級功能集。
英偉達網絡高級副總裁 Gilad Shainer 表示:“NVIDIA 網絡對於我們 AI 超級計算基礎設施的可擴展性至關重要。” “NVIDIA X800 交換機是端到端網絡平台,使我們能夠實現對新 AI 基礎設施至關重要的萬億參數規模的生成式 AI。”
據英偉達透露,這兩款產品的目前客戶包括微軟Azure 和 Oracle Cloud Infrastructure。
AI助力光刻
在演講一开始,英偉達就宣布,台積電和新思將使用英偉達的計算光刻平台即去年宣布的cuLitho 投入生產,以加速制造並突破下一代先進半導體芯片的物理極限。
計算光刻是半導體制造過程中計算最密集的工作負載,每年在 CPU 上消耗數百億小時。芯片的典型掩模組(其生產的關鍵步驟)可能需要 3000 萬小時或更多小時的 CPU 計算時間,因此需要在半導體代工廠內建立大型數據中心。
而英偉達稱,通過加速計算,350 個 NVIDIA H100 系統現在可以取代 40,000 個 CPU 系統,加快生產時間,同時降低成本、空間和功耗。

自去年推出以來,cuLitho 爲 TSMC 的創新圖案化技術帶來了新的機遇。在共享工作流上進行的 cuLitho 測試顯示,兩家公司共同將曲线流程速度和傳統曼哈頓式流程速度分別提升了 45 倍和近 60 倍。這兩種流程的不同點在於曲线流程的光掩模形狀爲曲线,而曼哈頓式流程的光掩模形狀被限制爲水平或垂直。
英偉達表示,自己开發了應用生成式人工智能的算法,以進一步提升cuLitho平台的價值。在通過 cuLitho 實現的加速流程的基礎上,新的生成式人工智能工作流程可將速度提高 2 倍。通過應用生成式人工智能,可以創建近乎完美的反向掩膜或反向解決方案,以考慮光的衍射。然後通過傳統的嚴格物理方法得出最終光罩,從而將整個光學近似校正(OPC)流程的速度提高了兩倍。
目前,工廠工藝中的許多變化都需要對 OPC 進行修改,從而增加了所需的計算量,並在工廠开發周期中造成了瓶頸。cuLitho 提供的加速計算和生成式人工智能可減輕這些成本和瓶頸,使工廠能夠分配可用的計算能力和工程帶寬,在开發 2 納米及更先進的新技術時設計出更多新穎的解決方案。
TSMC 首席執行官魏哲家博士表示:“通過與 NVIDIA 一同將 GPU 加速計算整合到 TSMC 的工作流中,我們大幅提升了性能、增加了吞吐量、縮短了周期時間並減少了功耗。TSMC 正在將NVIDIA cuLitho 投入到生產中,利用這項計算光刻技術推動關鍵的半導體微縮環節。
Synopsys 總裁兼首席執行官 Sassine Ghazi 表示:“二十多年來,Synopsys Proteus 光掩模合成軟件產品一直是經過生產驗證的首選加速計算光刻技術,而計算光刻是半導體制造中要求最嚴苛的工作負載。發展至先進的制造工藝後,計算光刻的復雜性和計算成本都急劇增加。通過與 TSMC 和 NVIDIA 合作,我們开創了能夠運用加速計算的力量將周轉時間縮短若幹數量級的先進技術,因此這一合作對於實現埃米級微縮至關重要。”
隨着EDA廠商新思將該技術集成到其軟件工具中,以及代工龍頭台積電的應用,計算光刻未來前景廣闊,可能會被更多芯片廠商所採用。
依舊遙遙領先
B200的推出,延續了H100之後英偉達的GPU霸權,就目前來說,依舊沒有公司能夠撼動它的地位,這是它過去深耕十年應有的回報。
但你可以注意到一個小細節,英偉達終於放棄了單體芯片設計,而是轉向多芯片設計,原因也很簡單,B200採用的是台積電改進版的N4P工藝,在晶體管密度上沒有大幅升級,而H100已經是一個全掩模版尺寸的芯片——它的芯片尺寸爲 814 mm2,理論最大值爲 858 mm2,在這樣的情況下,轉向雙芯片似乎並不難理解。
此外,英偉達也不再滿足於銷售單個芯片,而是兜售一整個系統,也就是英偉達 B200 NVL72,包含 600000 個零件,重1361 公斤的它,可能會成爲AI企業的新寵兒。
可以說,英偉達已經靠B200牢牢吸住了AI產業下一年的金,依舊是這一領域中毫無爭議的王。
標題:黃仁勳剛剛發布,英偉達最強GPU B200,首次採用Chiplet?
地址:https://www.iknowplus.com/post/91244.html







