英偉達,被彎道超車?
據不完全統計,目前半導體行業已开發出約 1000 種封裝類型,按互連類型來劃分,其中包括了引线鍵合、倒裝芯片、晶圓級封裝 (WLP) 和硅通孔 (TSV)等,無數個die通過互聯器件相連接,構成了如今日漸繁盛的封裝市場。
其中的先進封裝,成爲了近兩年最受關注和歡迎的領域,先進制程進展越緩慢,它的重要性就愈發突出, AMD、英特爾和英偉達這傳統的“御三家”紛紛涉足,從2D封裝轉战2.5D封裝,還向3D封裝這座高峰發起了挑战。
2023年6月,AMD在舊金山正式推出了MI300X與MI300A兩款AI加速器, 其中MI300X 採用了8 XCD,4個IO die,8個HBM3堆棧,高達256MB的AMD Infinity Cache和3.5D封裝的設計,支持 FP8 和稀疏性等新數學格式,是一款全部面向 AI 和 HPC 工作負載的設計,而它的晶體管也達到了1530 億顆,成爲了 AMD 迄今爲止制造的最大芯片。

AMD表示,MI300X 在人工智能推理工作負載中的性能比英偉達 H100高出1.6倍,在訓練工作中的性能與 H100相當,從而爲業界提供了亟需的高性能替代品,以取代英偉達的GPU。此外,這些加速器的 HBM3 內存容量也是英偉達 GPU 的兩倍多,達到驚人的 192 GB,使其 MI300X 平台能夠支持每個系統兩倍多的 LLM,並能運行比 H100 HGX 更大的模型。
最受矚目的當然還是AMD所宣稱的3.5D封裝,AMD表示,通過引入3D混合鍵合和2.5D的硅中介層,實現了全新的“3.5D封裝”技術。
AMD 高級副總裁兼企業研究員 Sam Naffziger 表示:“這是真正令人驚嘆的硅堆棧,提供了業界目前已知的最高密度性能。這一集成採用了台積電的兩種技術,即 SoIC(集成芯片系統)和 CoWoS(晶片基板芯片)。前者(SoIC)使用混合鍵合技術將較小的芯片堆疊在較大的芯片之上,無需焊料就能直接連接每個芯片上的銅墊,其幫助高速緩衝存儲V-Cache 芯片堆疊在最高端的 CPU 芯片上,而後者(CoWos)將芯片堆疊在一塊更大的硅片上,這塊硅片被稱爲內插板(interposer),用於容納高密度互連。”
當英偉達還在H200中使用台積電CoWoS的2.5D封裝時,AMD卻率先一步,實現了台積電SoIC 3D封裝和CoWoS 2.5D封裝的結合,而它更早之前對Chiplet的布局,似乎早已爲這次彎道超車做足了准備。
搭積木一樣造芯片
首先我們來回顧一下MI300X和MI300A的具體架構,根據AMD官方的解釋,MI300系列採用了台積電的 3D 混合鍵合 SoIC(集成電路上硅)技術,在四個底層 I/O 芯片之上對各種計算元件進行 3D 堆疊,無論是 CPU CCD(核心計算芯片)還是 GPU XCD。每個 I/O 芯片可以容納兩個 XCD 或三個 CCD。每個 CCD 與現有 EPYC 芯片中使用的 CCD 相同,每個 CCD 擁有八個超线程 Zen 4 核心。MI300A 使用了其中的三個 CCD 和六個 XCD,而 MI300X 使用了八個 XCD。
所謂 XCD,是AMD在GPU中負責計算的Chiplet,在MI 300X上,8個XCD包含了304 個CDNA 3 計算單元,那就意味着每個計算單元包含了34個CU。作爲對比,AMD MI 250X 擁有220個CU,這是一個較大的飛躍。
而HBM 堆棧則採用了 2.5D 封裝技術的標准中介層進行連接,每個 I/O 芯片都包含一個 32 通道 HBM3 內存控制器,用於托管 8 個 HBM 堆棧中的兩個,從而爲該設備提供了總共 128 個 16 位內存通道。MI300X 採用 12Hi HBM3 堆棧,容量爲 192GB,而 MI300A 使用 8Hi 堆棧,容量爲 128GB。
具體而言,AMD 的 CPU CCD 通過 3D 混合鍵合到底層 I/O 芯片,通過利用標准 2.5D 封裝的GMI3接口進行通信,AMD 爲此添加了一個新的焊盤通孔接口,可繞過 GMI3 鏈路,從而提供垂直堆疊芯片所需的 TSV。
5nm XCD GPU 芯片標志着 AMD GPU 設計的全面芯片化,XCD 和 IOD 具有硬件輔助機制,可將作業分解爲更小的部分、分派它們並保持它們同步,從而減少主機系統开銷,這些單元還具有硬件輔助的緩存一致性。
爲了MI300系列封裝的這一小步,AMD准備了多年的時間,最早的起源可以追溯到1965年,當時AMD工程師以 "芯片組 "概念爲基礎,开發出一種將每個大芯片拆分成小塊的設計。

在和英特爾的CPU競爭中,推土機架構的失敗讓AMD的處境岌岌可危,它亟需一個低成本的解決方案來與英特爾更先進的架構競爭,Zen應運而生,新一代Ryzen處理器採用芯片組或 MCM(多芯片模塊)架構,標志着整個 PC 和芯片制造行業的徹底轉變。
Zen初代架構相對簡單,採用了SoC 設計,從內核到 I/O 和控制器的所有內容都位於同一芯片上,同時引入了 CCX 概念,其中 CPU 核心被分爲四核單元,並使用無限高速緩存進行組合,由兩個四核 CCX 組成一塊芯片,不過消費級仍然是單芯片的設計。
而Zen+ 的情況基本上保持不變(採用了更先進節點),但 Zen 2 是一個重大升級,這是第一個基於Chiplet的消費類 CPU 設計,具有兩個計算芯片或CCD加一個 I/O 芯片。AMD 在 Ryzen 9 上添加了第二個 CCD,其核心數量在消費者領域前所未見。
Zen 3進一步完善了Chiplet設計,取消了CCX並將八個核心和32MB緩存合並到一個統一的CCD中,這大大減少了緩存延遲並簡化了內存子系統,AMD 銳龍處理器首次提供了比對手英特爾更好的遊戲性能。Zen 4 除了縮小 CCD 設計外,沒有對 CCD 設計做出顯着改變。
而EPYC系列中,第一代 AMD EPYC 處理器中基於四個復制的小芯片。每個處理器都有 8 個“Zen”CPU 內核、2 個 DDR4 內存通道和 32 個 PCIe 通道,以滿足性能目標,AMD 必須爲四個小芯片之間的 Infinity Fabric 互連提供一些額外的空間。
第二代EPYC的第一個Chiplet稱爲I/O die(IOD),採用12nm工藝,包含8個DDR4內存通道,128個PCIe gen4 I/O通道以及其他I/O(如USB和SATA, SoC數據結構,和其他系統級功能)。第二個Chiplet則是復合核心die(CCD),採用7nm工藝。在實際產品中,AMD將一個IOD與多達8個ccd組裝在一起,每個CCD提供8個Zen 2 CPU內核,因而可以一次提供64個內核。
第三代EPYC上,AMD提供多達64個核心和128個线程,採用AMD最新的Zen 3核心。該處理器設計有八個Chiplet,每個Chiplet有八個核心,這次Chiplet中的所有八個核心都是連接的,從而實現了有效的雙 L3 緩存設計,以實現較低的整體緩存延遲結構。
第四代EPYC中,AMD在原來的架構上採用多達 12 個 5 納米復雜核心芯片 (CCD) 的小芯片設計,其中I/O 芯片採用 6nm 工藝技術,而其周圍的 CCD 則採用 5nm 工藝。每個芯片具有 32MB 的 L3 緩存和 1 MB 的 L2 緩存。
這些CPU最終爲MI300系列的Chiplet鋪平了技術方面的道路。
2021年1月,AMD申請並通過了一項MCM GPU Chiplet 設計的專利,AMD在美國專利商標局公开了一項標題爲“使用高帶寬交聯的 GPU Chiplets”的專利,專利號爲“US 2020/0409859 A1”,在專利描述中,AMD概述了Chiplet設計中的圖形芯片未來的樣子,GPU Chiplet應直接與 CPU 通信,而其他小Chiplet通過無源、高帶寬交叉鏈路相互通信,並作爲片上系統 (SoC) 布置在相應的中介層上。
2023年11月,AMD又公开了一項關於Chiplet 設計的專利,其描述了一種與現有芯片布局截然不同的 GPU 設計,即在大型主 GPU 芯片周圍分布大量內存緩存芯片(MCD),其描述了一種將幾何工作量分配到多個芯片上的系統,所有芯片並行工作。此外,沒有一個 "中央芯片 "會將工作分配給下屬芯片,因爲它們都將獨立運行。該專利表明,AMD 正在探索用芯片組來制造 GCD,而不僅僅是一塊巨大的硅片。
從消費領域到超算領域,再到AI領域, AMD利用Chiplet掀起了一場紅色風暴,而爲這場風暴不斷提供助力的,正是來自台積電的先進封裝技術。
AMD背後的人
在接受IEEE Spectrum採訪時,AMD產品技術架構師Sam Naffziger講到:“五六年前,我們开始研發 EPYC 和 Ryzen CPU 系列。當時,我們進行了廣泛的研究,以找到最適合連接芯片的封裝技術。這是一個涉及成本、性能、帶寬密度、功耗和制造能力的復雜方程式。想出好的封裝技術相對容易,但要真正做到大批量、低成本地生產,則完全是兩碼事。”
2011年,台積電首次开發了2.5D封裝 CoWoS,隨即就被賽靈思的高端 FPGA 採用,但由於其價格過於昂貴,在封裝市場上遲遲打不开局面,直到AI浪潮的席卷全球,英偉達、AMD、谷歌、英特爾紛紛拋來了橄欖枝,將CoWoS推上了最熱門先進封裝的寶座。
下面是台積電的 CoWoS(晶圓基板上芯片)封裝示意圖。CoWoS 允許在單個封裝上集成多個芯片或裸片。這樣就能將不同類型的芯片(如處理器、內存和圖形芯片)集成到單個封裝中,從而提高性能、降低功耗並縮小外形尺寸。多個芯片通過硅通孔(TSV)垂直堆疊,並用微凸塊互連。與傳統的2D封裝相比,這種堆疊方法可以縮短互連長度、降低功耗並提高信號完整性。
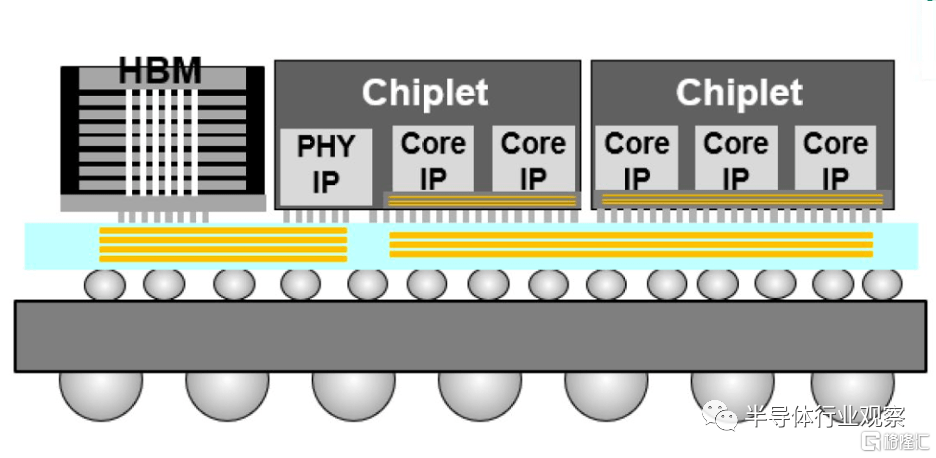
CoWoS在AMD的Chiplet上出力不少,通過將大型單片芯片劃分爲較小的芯片組,設計人員可以專注於優化每個芯片組的特定功能。,可實現更好的電源管理、更高的時鐘速度和更高的每瓦性能,同時還有助於將這些高性能芯片與內存等其他組件集成到一個封裝中,從而進一步提高系統性能。
CoWoS爲之後的3D封裝提供了寶貴經驗,2018年,台積電推出了SoIC 技術,其作爲一種創新的多晶片堆疊技術,主要是針對 10nm 以下的工藝技術進行晶圓級接合,與CoWoS技術相比,SoIC可提供更高的封裝密度、更小的鍵合間隔,還可以與CoWoS/InFo共用,實現多個Chiplet集成。
在IEDM 會議上,台積電副總裁介紹了該公司 SoIC 路线圖的更多細節。根據路线圖,台積電首先採用目前可用的 9μm 鍵合間距。然後,它計劃推出 6μm 間距,接着是 4.5μm 和 3μm。換而言之,台積電希望每兩年左右推出一種新的鍵距,每一代產品的縮放比例提高 70%。
他還用AMD的處理器作爲SoIC應用的例子,AMD 設計了基於 7nm 工藝的處理器和 SRAM,然後交由台積電生產,最後以 9μm 鍵合間距的SoIC技術來連接芯片。
這裏提到的,正是AMD在2021年推出的代號爲Milan-X的EPYC處理器裏加入的3D V-Cache緩存,這也是世界上首款採用3D芯片堆疊的數據中心處理器。
AMD 表示,3D V-Cache 在當前第三代 EPYC CPU 每個計算芯片 32 MB 的 SRAM 基礎上又增加了 64 MB,使 Milan-X 每個計算芯片的三級緩存達到 96 MB,由於 Milan-X 處理器架構中最多有 8 個計算芯片,因此 CPU 中共享的 L3 緩存最多可達 768 MB,額外的 L3 緩存可以緩解內存帶寬壓力並減少延遲,從而顯着提高應用程序性能。
能實現這一步,台積電的 SoIC 技術功不可沒,其將 V-Cache 中的互連永久綁定到 CPU,縮小了芯片之間的距離,從而實現 2 TB/s 的通信帶寬,與第三代 EPYC CPU 使用的 2D 小芯片封裝相比,Milan-X CPU 中的互連的每比特能耗僅爲三分之一,互連密度提高了 200 倍,功效提高了三倍。
這一項技術後續也被下放到了Ryzen 7 5800X3D處理器之中,开始在消費市場中大展身手,包括最新的Ryzen 9 7950X3D,同樣用到了3D V-Cache的技術。
2023年,台積電在北美技術論壇上着重介紹了全新的3DFabric技術,其主要由先進封裝、3D芯片堆疊和設計等三部分組成。通過先進封裝,可以在單一封裝中置入更多處理器及存儲器,從而提升運算效能;在設計支持上,台積電推出开放式標准設計語言的最新版本,協助芯片設計人員處理復雜大型芯片。
2011年至2023年,台積電十余年的封裝技術演進讓AMD的Chiplet夢想終於得以實現,而MI300系列也正是建立在最新的3DFabric基礎之上,將台積電SoIC 前端技術與 CoWoS後端技術相集成,堪稱量產先進封裝技術的集大成者。
藍色巨人的封裝版圖
對於英特爾來說,封裝同樣是它發展的重心之一,而且與AMD不同的是,英特爾選擇了自己搞封裝,力圖掌握芯片研發生產應用的全流程。
英特爾對標台積電CoWoS的2.5D封裝技術被稱爲EMIB, 2017年正式應用於產品,英特爾的數據中心處理器Sapphire Rapid就是採用的這項技術;第一代的3D IC封裝則稱爲Foveros,2019年時已用於英特爾計算機處理器Lakefield。
EMIB最大特色就是通過硅橋(Sillicon Bridge),從下方來連接存儲器(HBM)和運算等各種芯片(die)。也因爲硅橋會埋在基板(substrate)中並連接芯片,讓存儲器和運算芯片能直接相連,加快芯片本身的能效。
Foveros則是3D堆棧,將存儲器、運算和架構等不同功能的芯片組堆棧起來後,運用銅线穿透每一層,達到連接的效果,最後,工廠會將已經堆棧好的芯片送到封裝廠座組裝,將銅线與電路板上的電路做接合。
2022年,英特爾首次將下2.5D和3D封裝技術融合在一起,命名爲Co-EMIB,這是一個將EMIB和Foveros技術相結合的創新應用,能夠讓兩個或多個Foveros元件互連,並且基本達到單芯片的性能水准,藉由這一項技術,推出了當時晶體管規模最大的SoC——Ponte Vecchio,主要面向高性計算市場。
每顆 Ponte Vecchio 處理器實際上都是 使用英特爾Co-EMIB 連接在一起的兩個Chiplet的鏡像集,Co-EMIB 在兩個 3D Chiplet堆棧之間形成高密度互連的橋梁,橋本身是嵌入封裝有機基板中的一小塊硅。硅上的互連线可以比有機基板上的互連线更窄。Ponte Vecchio 與封裝基板的普通連接間隔爲 100 微米,而 Co-EMIB 芯片中的連接密度幾乎是其兩倍,Co-EMIB 芯片還將高帶寬存儲器 (HBM) 和 Xe Link I/O Chiplet連接到“基礎硅”(最大的Chiplet),其他芯片則堆疊在該“基礎硅”上。
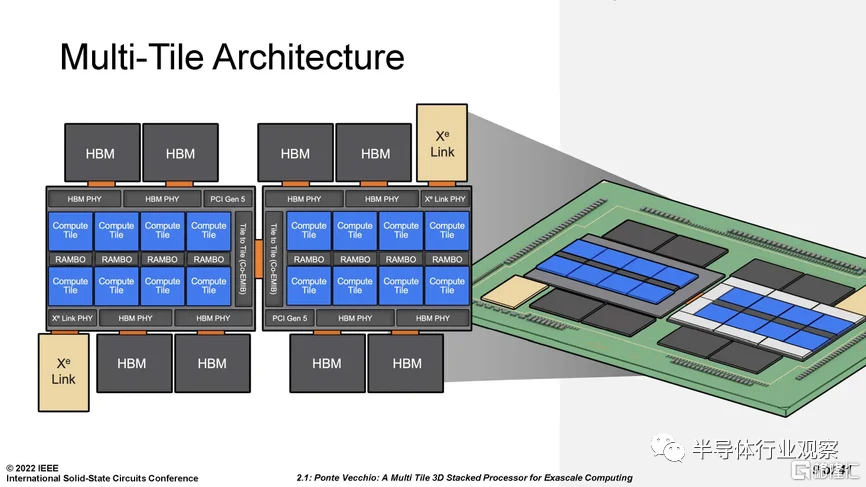
基礎芯片還使用了英特爾的 3D 堆疊技術,稱爲 Foveros,該技術在兩個芯片之間建立了密集的芯片到芯片垂直連接陣列。這些連接僅相距 36 微米,並通過“面對面”連接芯片來實現;也就是說,一個芯片的頂部粘合到另一個芯片的頂部。信號和電源通過TSV硅通孔進入該堆棧,硅通孔是相當寬的垂直互連,直接穿過大部分硅。Ponte Vecchio 上使用的 Foveros 技術是對用於制造英特爾Lakefield 移動處理器的技術的改進,信號連接密度增加了一倍。
做到這一點並不容易,英特爾院士Wilfred Gomes表示,這需要在產量管理、時鐘電路、熱調節和功率傳輸方面進行創新。例如,英特爾工程師選擇爲處理器提供高於正常水平的電壓(1.8 伏),以便降低電流,簡化封裝,基片中的電路將電壓降低到接近 0.7 伏,以便在計算芯片上使用,而且每個計算芯片都必須在基片中擁有自己的電源域。
對於英特爾來說,Ponte Vecchio將它目前已有的先進封裝技術推到了巔峰,與AMD的MI300系列相比,也未遜色多少,可謂是如今先進封裝的紅藍雙星。
實際上,英特爾雖然在先進制程上略落後於台積電,但在先進封裝卻與台積電不相上下。英特爾表示,自己靈活的代工服務,允許客戶混合搭配其晶圓制造和封裝產品,作爲老牌廠商的它,晶圓封裝廠分散在世界各地,可以利用地理優勢來擴大產能和服務。
英特爾CEO Pat Gelsinge在接受採訪時也表示,英特爾擁有下一代內存架構的先進能力,以及3D 堆疊的優勢,既能用於Chiplet,也能用於人工智能和高性能服務器的超大封裝,未來我們將把這些技術應用到產品中,同時也將展示給代工廠(IFS)的客戶、
爲什么是Chiplet?
在看完AMD、英特爾以及台積電的技術歷程後,相信許多人都會有一個疑問,爲什么他們如此執着於3D封裝和Chiplet呢?
原因源自半導體行業內部的需求,摩爾定律的出現,讓不斷提高的設備集成度能夠繼續適應相同的物理尺寸,光刻縮小可以使構建塊縮小 30%,那么就可以在不增加芯片尺寸的情況下增加 42% 的電路。
但並非所有半導體器件都能享受這一紅利,例如可以包含模擬電路的 I/O,其擴展速度約爲邏輯的一半,這就讓人不得不尋找新的出路。而且光刻縮小的成本也不便宜,採用 7nm 工藝加工的晶圓成本高於採用 14nm 工藝加工的晶圓成本,5nm 工藝的成本高於 7nm 工藝,依此類推……隨着晶圓價格的上漲,Chiplet往往比單片更加經濟實惠。
此外,由於新芯片設計需要設計和工程資源,並且由於新節點的復雜性不斷增加,每個新工藝節點的新設計的典型成本也隨之增加,這一的情況進一步激勵人們創建可重復使用的設計。
Chiplet設計理念使這成爲可能,因爲只需改變芯片的數量和組合即可實現新的產品配置,通過將單個小芯片集成到 1、2、3 和 4 芯片配置中,可以從單個流片創建 4 種不同的處理器品種,而如果想把它們整合進一塊芯片中,就需要 4 次單獨的流片。
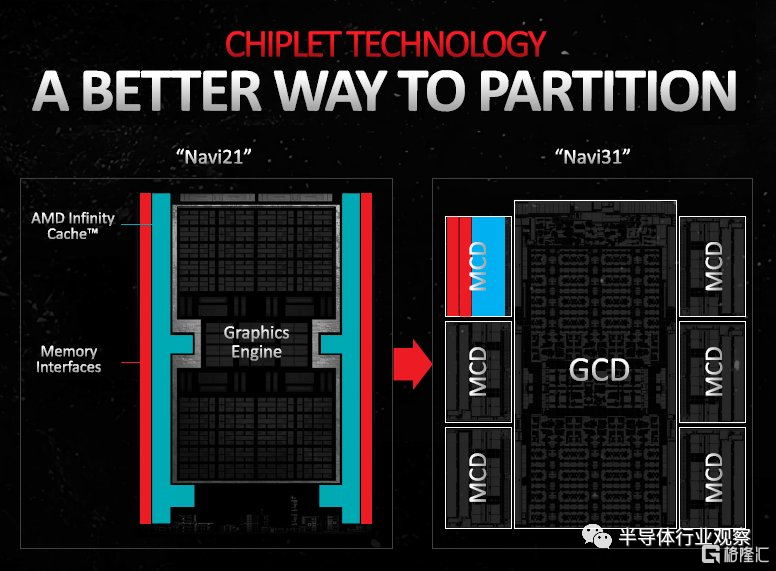
AMD 在其關於新款 Radeon RX 7900 系列 "Navi 31 "圖形處理器的技術演示中,詳細解釋了爲什么必須爲高端圖形處理器採用芯片組路线。
事實上,AMD 近十年裏的 Radeon GPU 與CPU相比,不管是利潤還是收入都不容樂觀,在面臨英偉達競爭的情況下,降低制造成本的必要性愈發突出,隨着 GeForce "Ada Lovelace "一代的推出,英偉達繼續押注在單片硅 GPU 上,即使是最大的 "AD102 "芯片也還是單片 GPU,這爲 AMD 提供了一個降低 GPU 制造成本的機會。
Chiplet讓AMD其能夠和英偉達展开價格战,拿下更多的市場份額。最典型的例子是,AMD 對 Radeon RX 7900 XTX 和 RX 7900 XT 分別採用了相對激進的999美元和899美元定價,根據AMD 的官網數據,這兩款產品有能力與英偉達 1199 美元的 RTX 4080 一決高下,在某些情況下,甚至有可能與 1599 美元的 RTX 4090 展开較量。
事實上,這就是Chiplet的最顯著的優點之一,通過使用Chiplet,AMD可以快速提高良率並簡化設計/驗證,同時可以爲每個小芯片選擇最佳工藝。邏輯部分可以採用尖端工藝制造,大容量SRAM可以使用7nm左右的工藝制造,而I/O和外圍電路可以使用12nm或28nm左右的工藝制造,從而減少了設計和制造成本。
此外,Chiplet也能幫助它輕松制造衍生類型,例如相同邏輯但不同外圍電路,或相同外圍電路但不同邏輯,而且可以混合使用來自不同制造商的小芯片,而不是局限在單個制造商上。
AMD如此,英特爾也不外乎是,AMD仰賴台積電已有的技術,全力研究芯片架構設計,英特爾就要稍微喫力一點,一方面研究先進制程和封裝,另外一方面也要着手芯片與Chiplet的迭代改進,兩家甚至還在封裝上打起了擂台賽。
如今去評判比賽的勝負已經不重要了,因爲3D封裝與Chiplet逐漸從數據中心和AI加速器走向消費市場的PC處理器,最終惠及筆記本與手機,成爲了大家認定的新趨勢,
寫在最後
與AMD和英特爾相比,英偉達在3D封裝以及Chiplet上卻顯得如此“遲鈍”。
2017年6月英偉達發表論文《MCM-GPU: Multi-Chip-Module GPUs for Continued Performance Scalability》提出了MCM設計,其基本可以看成是如今的Chiplet。
但英偉達一直未將這一設計付諸於實踐中,反而在2021年12月發表了一篇名爲《GPU Domain Specialization via Composable On-Package Architecture》的論文,其中所提出的COPA-GPU架構,實際只是單獨分離了L2緩存,這也就是說,英偉達會在未來繼續堅持Monolithic單一光刻設計。
英偉達堅持大芯片的原因其實很簡單,die與die之間通訊帶寬永遠無法和monolithic內部的通訊帶寬相比,Chiplet也許不適合高AI算力場合,更適合在CPU領域中大展拳腳,2022年英偉達發布的Grace CPU Superchip,就通過NVLink-C2C技術實現芯片高速互連,該芯片還遵循由業界共同制定的Chiplet互連規範UCIe。
在Chiplet上的謹慎,也讓英偉達與3D封裝沒了緣分,雖然英偉達目前是台積電2.5D封裝CoWoS的最大客戶之一,但SoIC的客戶裏暫時還不包括它,也讓它成了御三家裏最晚擁抱這項先進技術的一家了。
伴隨着Chiplet的高速發展,英偉達也可能在未來开始擁抱這一設計理念,今年的爆料人士Kopite7kimi稱,英偉達面向高性能計算(HPC)和人工智能(AI)客戶的下一代Blackwell GB100 GPU將全面採用Chiplet設計。
如今AMD在AI芯片上先行一步,利用Chiplet和3.5D封裝打造了更大更強的MI300X,英特爾也已經全面擁抱Chiplet和3D封裝,英偉達雖然依舊坐擁龐大的AI市場,但它的寶座卻出現了一道微不可察的裂縫,紅藍綠這三家,誰能在芯片封裝上掌握真正的話語權呢?
標題:英偉達,被彎道超車?
地址:https://www.iknowplus.com/post/69117.html







