AMD最強AI芯片全披露,吹響進攻號角
在今年六月於舊金山舉行的一場盛大發布會上,AMD CEO Lisa Su在介紹MI 300A之余,還對外公布了公司擁有1530億晶體管的新一代AI芯片MI 300X。因爲擁有強大的帶寬和內存,疊加人工智能市場被英偉達近乎壟斷的現狀,AMD的這顆芯片在發布之後,引起了人工智能從業者的廣泛關注。
Lisa Su在公司10月底的三季度的財報會議上更是樂觀預測,展望今年第四季度,來自數據中心圖形處理單元 (GPU) 的收入將達到約 4 億美元,而隨着收入持續增長,到 2024 年這一總額可能會超過 20 億美元。“這一增長將使 MI300 成爲 AMD 歷史上銷售額突破 10 億美元最快的產品,”Lisa Su 表示。

基於這些優越的表現,Lisa Su在今天的“Advancing AI”大會演講中提高了她對數據中心AI加速器的預測。一年前,她認爲2023年的AI加速器市場爲300億美元。到2027年,全球數據中心AI加速器的市場規模將達到1500億美元,這意味着期間的CAGR約爲50%。但現在,Lisa Su認爲,AI加速器在2023年的市場規模將達到450億美元,未來幾年的CAGR將高達70%,推動整個市場到2027年增加到4000億美元的規模。

AMD還同時揭开了MI 300X和MI 300A的神祕面紗,還帶來了RCom 6的更多介紹。
MI300X,全面領先競爭對手
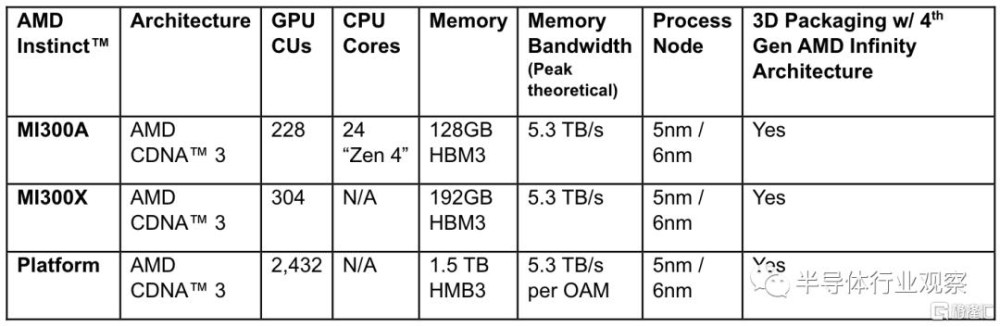
如圖所示,AMD Instinct MI300X 採用了8 XCD,4個IO die,8個HBM3堆棧,高達256MB的AMD Infinity Cache和3.5D封裝的設計,支持 FP8 和稀疏性等新數學格式,是一款全部面向 AI 和 HPC 工作負載的設計。
據筆者所了解,所謂 XCD,是AMD在GPU中負責計算的Chiplet。如圖所示,在MI 300X上,8個XCD包含了304 個CDNA 3 計算單元,那就意味着每個計算單元包含了34個CU(CU:Computing Unit)。作爲對比,AMD MI 250X 擁有220個CU,這也是一個較大的飛躍。

在IOD方面,AMD在這一代的加速器上同樣採用了Infinity Cache技術,也就是他們所說的“海量帶寬放大器”(massive bandwidth amplifier)。資料顯示,這是AMD在RDNA 2引入的技術。當時發布的時候,AMD方面表示,希望能夠借助Infinity Cache 技術,讓GPU 不但能夠擁有可快速訪問的高速、高帶寬片內緩存,而且還可以同時實現低功耗和低延遲。在MI 300X,這個緩存的數字提升到了256MB。與此同時,AMD還給這個芯片配備了7×16路的第四代AMD infinity Fabric link,爲其I/O保駕護航。
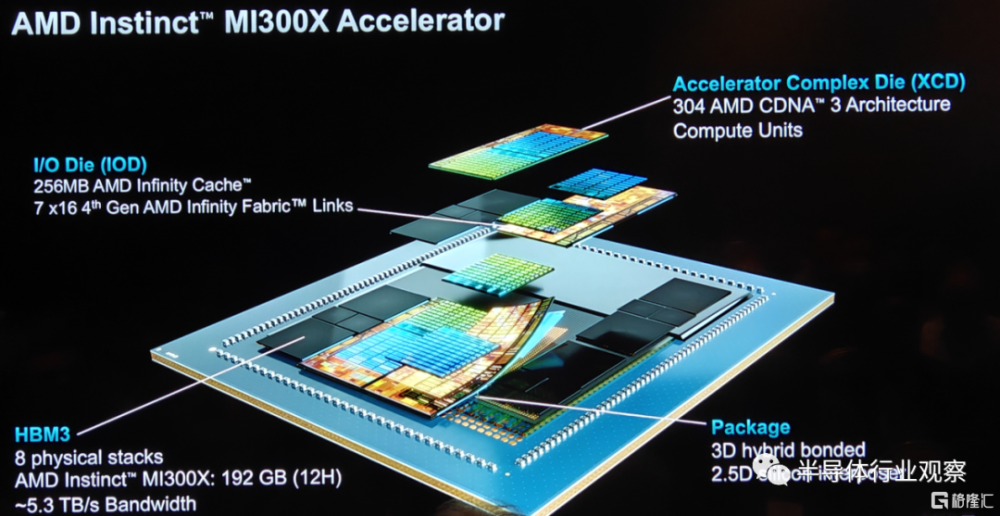
具體到封裝方面,AMD通過引入3D混合鍵合和2.5D的硅中介層,實現了一個自稱爲“3.5D封裝”的技術。
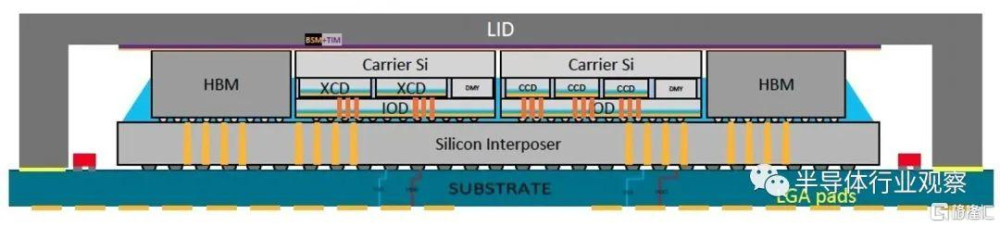
根據IEEE在報道中指出,這種集成是使用台積電的SoIC和 CoWoS技術完成的。其中,後者使用所謂的混合鍵合將較小的芯片堆疊在較大的芯片之上,這種技術無需焊接即可直接連接每個芯片上的銅焊盤。它用於生產 AMD 的V-Cache,這是一種堆疊在其最高端 CPU 小芯片上的高速緩存內存擴展小芯片。前者稱爲 CoWos,將小芯片堆疊在稱爲中介層的較大硅片上,該硅片旨在包含高密度互連中。
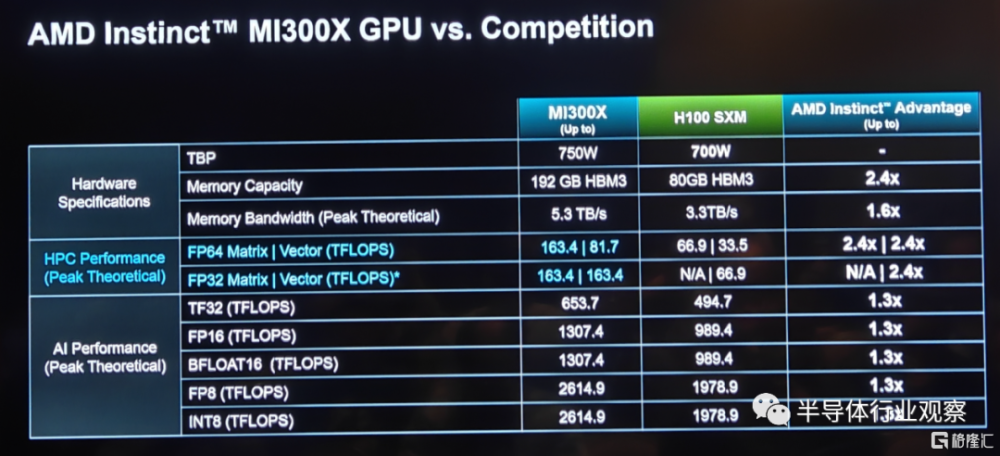
來到HBM 3配置方面,通過八個物理堆棧的HBM,讓MI300 X的HBM容量高達192GB,是英偉達H100 80GB HBM 3的2.4倍,這和之前提供的數據一致。但在帶寬方面,和上次提供的5.2TB/s的不一樣,AMD在新的展示文件中表示,MI 300X的峰值存儲帶寬爲5.3TB/s,這是英偉達H100 SXM(存儲帶寬爲3.3TB/s)的2.4倍。
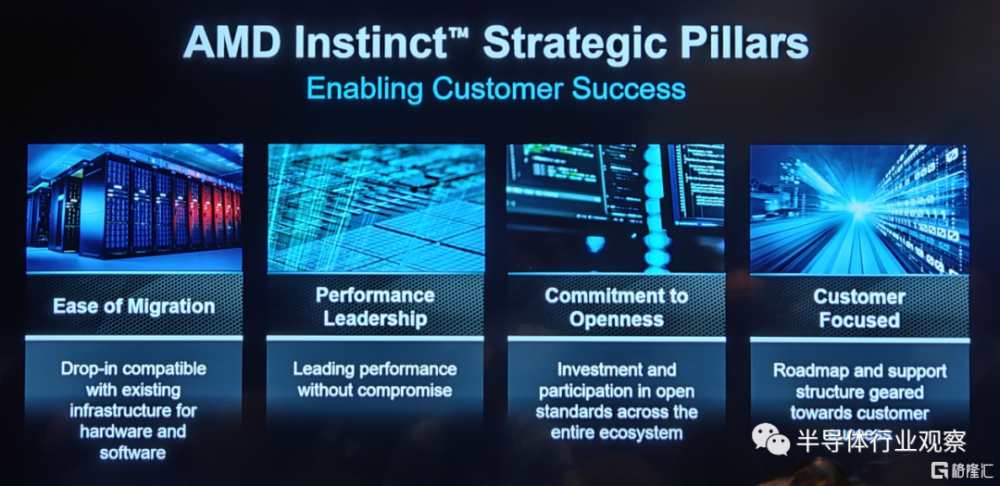
如上圖所示,受惠於這些領先的設計,MI300 X在多個性能測試中領先於競爭對手。而按照他們所說,AMD在Instinct的產品战略方面有四個战略支柱,分別是易於遷移、性能領先、致力於开放和客戶聚焦。當中易於遷移是指 MI 300X將與現在的硬件和軟件框架兼容;性能領先則意味着不妥協的領先性能;致力於开放則着重強調了公司投資和積極參與到整個生態系統的开源標准系統中去;客戶聚焦則代表着公司以客戶爲己任,打造適合客戶需求的路线圖的決心。
事實上,如圖所示,AMD採用了8個MI 300X打造了一個擁有優越性能平台,具體參數如下圖所示,這也讓其成爲了業界領先的標准設計。更重要的是,由於該產品的兼容性,使其能夠大大降低客戶硬件或者軟件遷移的時間和成本。

AMD總結說,基於行業標准 OCP 設計構建的新一代Instinct平台配備了八個 MI300X 加速器,可提供行業領先的1.5TB HBM3內存容量。AMD Instinct平台的行業標准設計允許 OEM 合作夥伴將MI300X加速器設計到現有的AI產品中,並簡化部署並加速基於AMD Instinct加速器的服務器的採用。
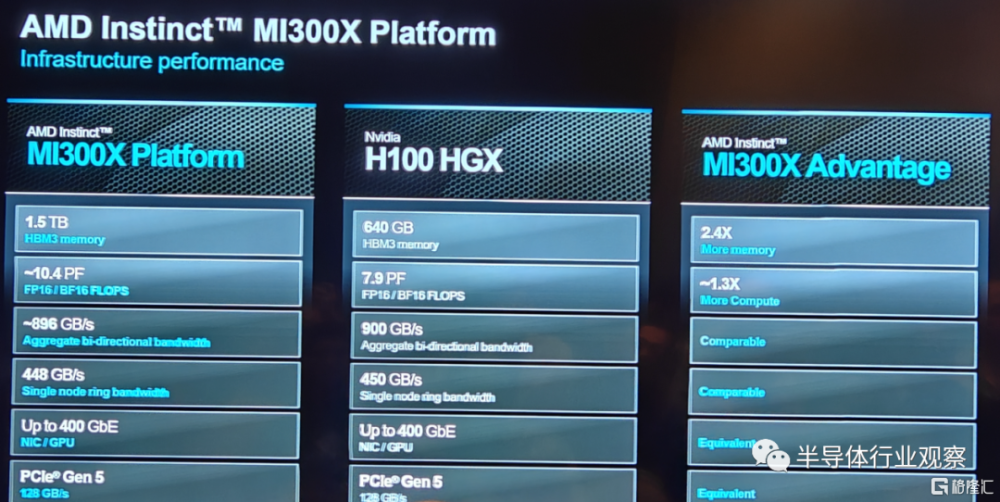
與Nvidia H100 HGX相比,AMD Instinct平台在類似BLOOM 176b等LLM上運行推理時,吞吐量可提高高達1.6倍,並且是市場上能夠對Llama2等700億參數模型運行推理的唯一選擇。
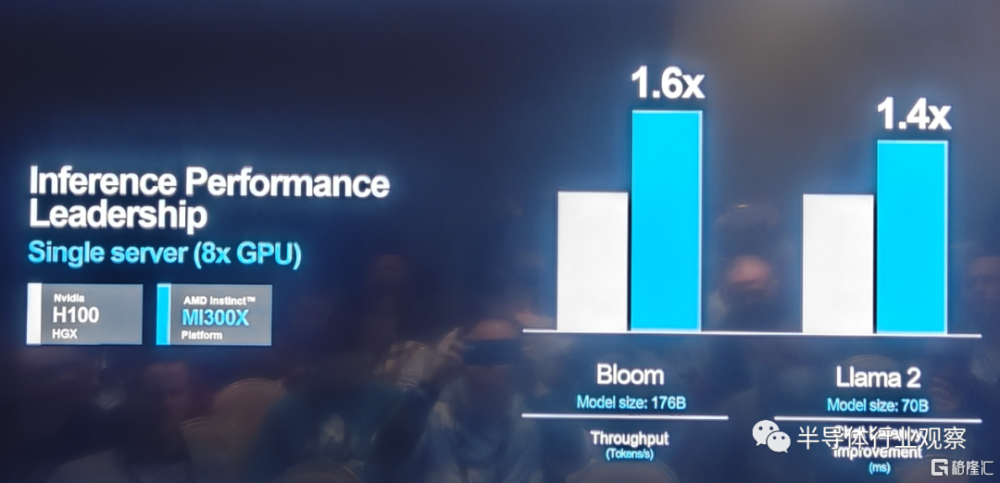
在關鍵AI kernel性能表現上,基於MI 300X的平台表現也優於競爭對手。
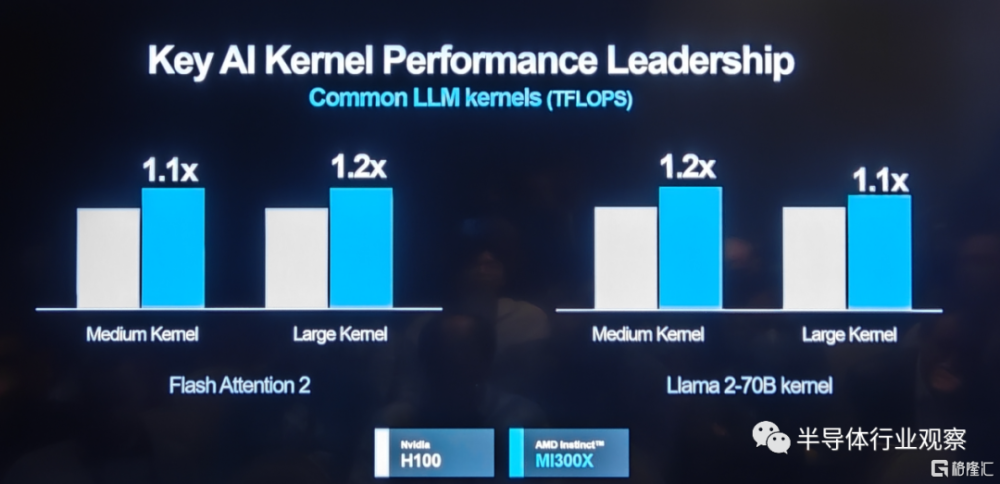
在某些模型的訓練上,如下圖所示,AMD MI 300X在和英偉達H100相比時也不遜色。
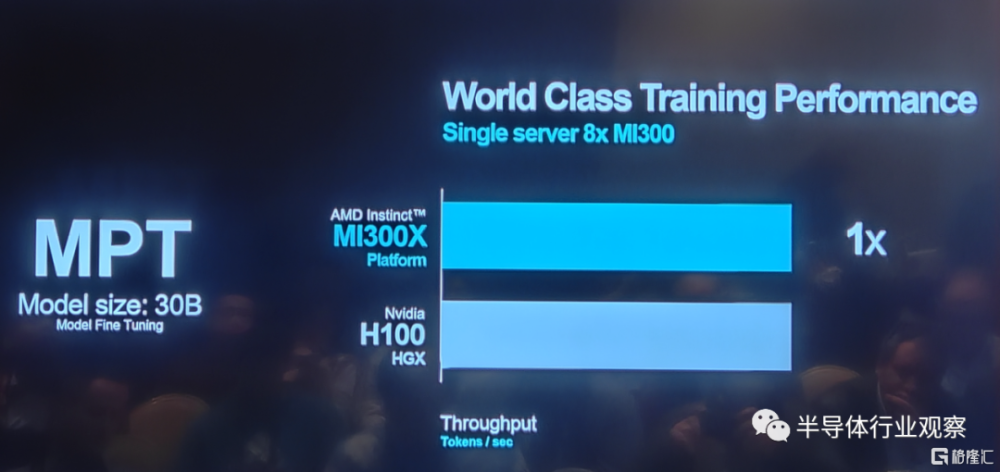
從下圖數據,我們則可以看到AMD最新芯片平台在訓練和推理方面的更多優勢。

MI 300A,業界首個APU加速器
在這次發布會上,AMD還深入介紹了業界首個APU加速器MI 300A。
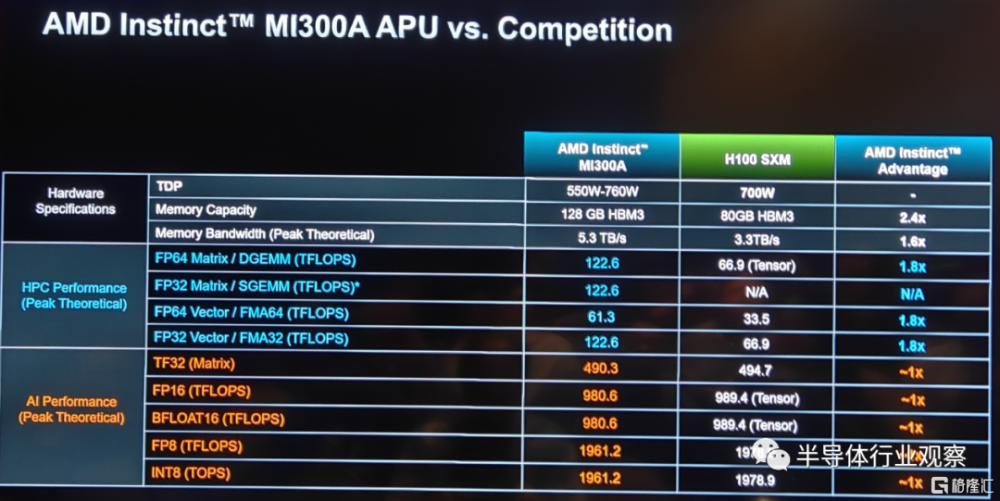
作爲全球首款適用於HPC和AI的數據中心APU,AMD Instinct MI300A APU利用3D封裝和第四代AMD Infinity架構,在HPC和AI融合的關鍵工作負載上提供領先的性能。MI300A APU 結合了高性能AMD CDNA 3 GPU內核、最新的AMD“Zen 4” 86 CPU內核和128GB下一代HBM3 內存。與上一代的AMD Instinct MI250X相比,在FP32 HPC和AI上獲得約爲1.9倍的每瓦性能提升。

具體到產品設計方面,如上圖所示,MI 300A和MI 300X擁有很多的相似之處,例如3.5D封裝和256MB的AMD infinity Cache以及4個IOD。但在HBM和計算單元方面,也有了不同之處。例如雖然MI 300A同樣也是採用了HBM 3設計,但是其容量大小卻小於MI 300X。
在I/O die方面,雖然擁有和MI 300X同樣的infinity Cache,但MI 300A的I/O配置了4×16的第四代Infinity Fabric Link和4×16的PCIe 5,這與MI 300X又有所不同。
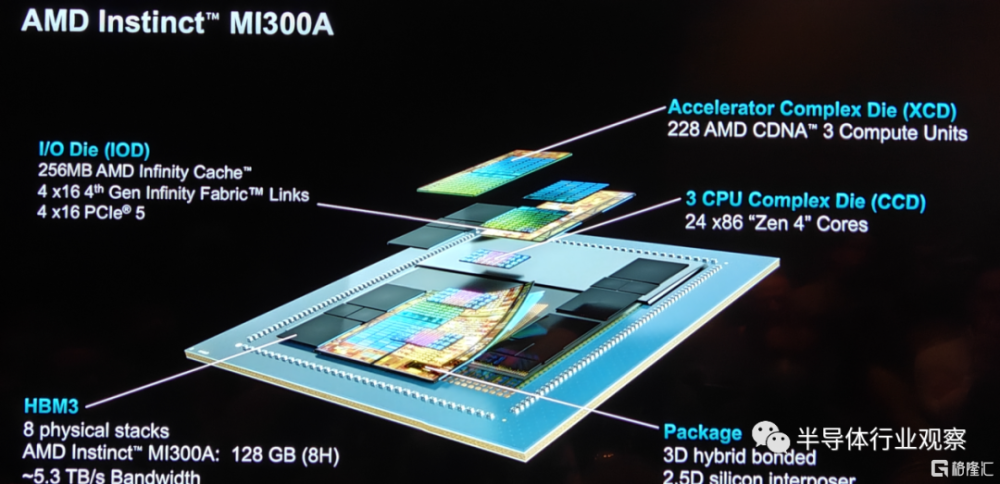
對於這兩個不同的MI 300系列產品,在計算單元方面方面的差距是尤爲明顯。和MI 300X只採用XCD計算單元不一樣,MI 300A採用了6個XCD和3個CCD,這就意味着其擁有228個CDNA 3 CU和24個“zen 4”核心。
其實,“CPU+GPU”的設計並不是AMD獨家的,例如應爲的GH200,就是採用了同樣的概念,英特爾也曾經在Falcon Shores上規劃了XPU的設計。雖然Intel取消了XPU的設計,但AMD依然堅持走在這條路上,因爲按照他們之前的說法,從一致內存架構向統一內存APU架構的轉變,有望提高效率、消除冗余內存副本,且無需將數據從一個池復制到另一個池,以實現降低功耗和延遲的目的。
不過,從IEEE的報道也可以看到,英偉達和AMD的做法有所不同。在英偉達方面,Grace 和 Hopper 都是獨立的芯片,它們都集成了片上系統所需的所有功能塊(計算、I/O 和緩存),它們之間是通過 Nvidia NVLink Chip-2-Chip 互連水平連接的,而且很大——幾乎達到了光刻技術的尺寸極限。
AMD則使用 AMD Infinity Fabric 互連技術集成了三個 CPU 芯片和六個 XCD 加速器。而隨着功能的分解,MI300 中涉及的所有硅片都變得很小。最大的 I/O die甚至還不到 Hopper 的一半大小。而且 CCD 的尺寸僅爲I/O die的1/5左右,這種小尺寸帶來了良率和成本的優勢。
AMD方面在今日的介紹中也總結說,這種APU設計擁有統一的內存、共享的AMD infinity Catch、動態功率共享(dynamic power shared)和易於變成等優勢,這將解鎖前所未有的新性能體驗。
在實際與Nvidia H100的對比中,MI 300A同樣不落下風。例如在HPC OpenFOAM motorbike測試中,AMD MI 300A領先於競爭對手四倍。
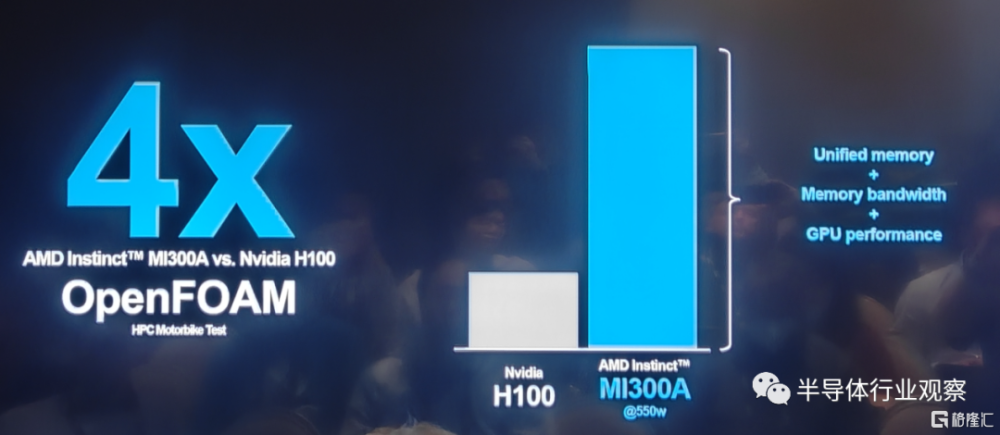
在Peak HPC的每瓦性能表現上,MI 300A更是能做到同爲“CPU+GPU”封裝設計的Nvidia GH200的兩倍。

在衡量HPC性能的多項測試中,MI 300A也與H100不相伯仲。
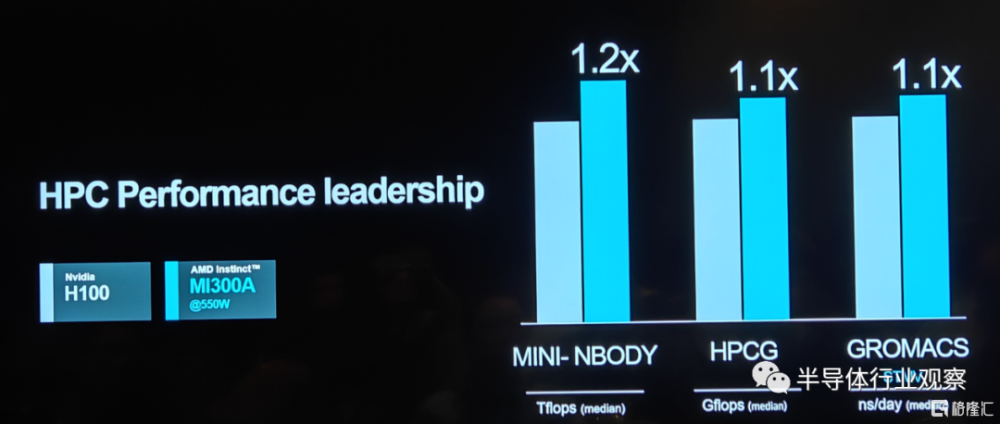
正因爲擁有如此出色的表現,AMD的MI 300系列獲得了客戶的高度認可,這也是文章开頭Lisa Su所披露公司AI加速器獲得了快速增長訂單的根源所在。他們表示,MI 300A更適合於數據中心和HPC應用,例如有望成爲世界上速度最快的超級計算機El Capitan就是MI 300A的客戶。至於MI 300X則更適合於生成式AI的應用場景。AMD在發布會上也強調,公司這兩款產品都受到了客戶的高度評價。
無可否認,從過去的多年發展看來,AMD在硬件方面正在快速更上,且獲得了不錯的表現。但正如Semianalysis分析師Dylen Patel所說,對於AI加速器而言,所有的魔鬼細節都是體現在軟件中。
“在過去的十年中,機器學習軟件开發的格局發生了重大變化。許多框架已經出現又消失,但大多數都嚴重依賴於利用Nvidia的CUDA,並且在Nvidia GPU上表現最佳。”Dylen Patel強調。他同時指出,在AMD方面,其ROCm的表現在過去並沒有那么好,例如RCCL庫 (Communications Collectives Libraries) 總體來說並沒有足夠好。
爲此,AMD正在加強公司在軟件方面的實力,例如ROCM 6就是這次發布會上的一個亮點。
加強軟件布局,加緊拓寬客戶
AMD總裁Victor Peng在多個場合都強調過,軟件非常重要。他甚至認爲,軟件是AMD想要在市場上做出改變的首要任務。
在六月的發布會上,Victor Peng曾介紹說,AMD 擁有一套完整的庫和工具ROCm,可以用於其優化的AI軟件堆棧。與專有的CUDA不同,這是一個开放平台。而在過去的發展中,公司也一直在不斷優化 ROCm 套件。AMD同時還在與很多合作夥伴合作,希望進一步完善其軟件,方便开發者的AI开發和應用。
在過去 6 個月中,AMD也的確取得了一些巨大進展。

據介紹,AMD推出了AMD Instinct GPU开源軟件堆棧的最新版本 ROCm 6,該軟件堆棧針對生成式 AI(尤其是大型語言模型)進行了優化。還支持新數據類型、高級圖形和內核優化、優化庫和最先進的注意力算法(attention algorithms)。

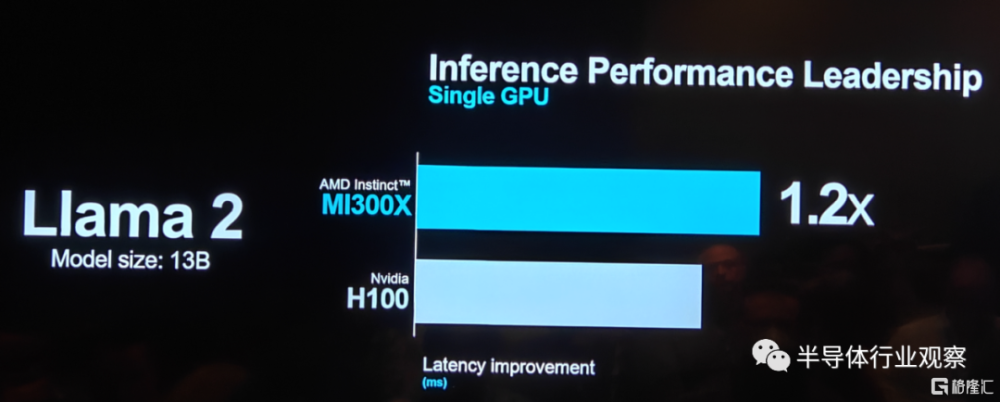
在將ROCm 6與MI300X一起時,與運行在MI250上的ROCm 5相比,擁有70億參數的Llama 2上文本生成的整體延遲性能提高了約8倍。

在參數大小爲130億的Llama 2做推理性能測試時,MI300X的延遲表現稍稍優於英偉達的H100。
在這些軟硬件提升支持下,包括Databricks、Essential Al和Lamini在內的三家構建新興模型和人工智能解決方案的人工智能初創公司與AMD一起討論了他們如何利用AMD Instinct MI300X加速器和开放ROCm 6軟件堆棧爲企業客戶提供差異化的人工智能解決方案。最炙手可熱的人工智能公司OpenAl也宣布在Triton 3.0中添加了對AMD Instinct加速器的支持——爲AMD加速器提供开箱即用的支持,使开發人員能夠在AMD硬件上進行更高級別的工作。
與此同時,微軟、Meta、Oracle也分享了與AMD的合作。其中,微軟談到了如何通過部署MI 300X來爲Azure ND MI 300X v5 VM賦能,並優化了其AI工作負載;Meta也在數據中心部署MI 300X和ROCm 6,以實現AI推理負載。值得一提的,在於Meta的合作中,AMD還展現了公司ROCm 6在Llama2上做得一些優化;Oracle也表示將提供基於MI 300X加速器的裸金屬計算方案。他們還將在不久的將來提供基於MI 300X的生成式AI服務。
此外,包括戴爾、惠普、聯想、超微、技嘉、Inventec、QCT、Ingensys和Wistron在內的多家數據中心基礎設施提供商也都已經或將計劃在其產品集成MI300。
和曾經的數據中心CPU市場一樣,GPU市場當前也是一家獨大,這是一個公开的祕密。但無論是從市場發展現狀、客戶需求,或者未來發展需要來看,擁有另外的AI加速器供應商是刻不容緩的。
擁有MI 300系列的AMD無疑是最優的一個候選。讓我們期待Lisa Su帶領這個過去幾年在CPU領域創造奇跡的團隊在GPU市場上再創輝煌。
標題:AMD最強AI芯片全披露,吹響進攻號角
地址:https://www.iknowplus.com/post/59068.html







