英偉達芯片,最新路线圖
衆所周知,隨着生成式AI的大熱,英偉達正在數據中心領域大殺四方,這也幫助他們實現了更好的業績。根據公司公布的數據,截至 2023 年 7 月 30 日的第二季度,英偉達收入爲 135.1 億美元,較上一季度增長 88%,較去年同期增長 101%。
不過,英偉達目前的業績預期很多都是基於當前的芯片和硬件所做的。但有分析人士預計,如果包含企業 AI 及其 DGX 雲產品,該數據中心的市場規模將至少是遊戲市場的 3 倍,甚至是 4.5 倍。
瑞銀分析師Timothy Arcuri也表示,英偉達目前在DGX雲計算方面的收入約爲10億美元。但在與客戶交談後,他認爲,該公司每年可能從該部門獲得高達100億美元的收入。他給出的理由是Nvidia仍然可以在DGX雲上添加額外的產品,包括預先訓練的模型,訪問H100 GPU等等。他說,現在這些領先GPU仍然“非常難”獲得訪問,能夠根據需要擴大和縮小規模,並與現有的雲或內部部署基礎設施“基本上無縫集成”。
因此,英偉達在最近公布了一個包括H200、B100、X100、B40、X40、GB200、GX200、GB200NVL、GX200NVL 等新部件在內的產品路线圖,這對英偉達未來的發展非常重要。
數據中心路线圖
根據servethehome披露的路线圖,英偉達的一項重大變化是他們現在將其基於 Arm 的產品和基於 x86 的產品分开,其中 Arm 處於領先地位。作爲參考,普通客戶現在甚至無法購买 NVIDIA Grace 或 Grace Hopper,因此在 2023-2025 年路线圖的堆棧中顯示它是一個重要的細節。以下是 NVIDIA 提出的路线圖:
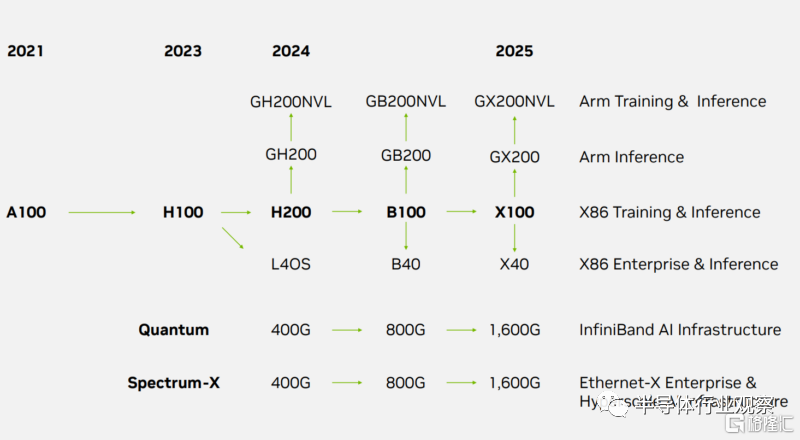
在Arm方面,英偉達計劃將在2024年推出GH200NVL,在2024年推出GB200NVL,然後在2025年推出GX200NVL。我們已經看到 x86 NVL 系列與NVIDIA H100 NVL一起推出,但這些都是基於 Arm 的解決方案。然後是 2024 年推出的 GH200NVL。還有快速跟隨的 GB200NVL,然後是 GX200NVL。還有非 NVL 版本。
在NVIDIA 宣布推出雙配置的新型 NVIDIA Hopper 144GB HBM3e 型號(可能最終成爲 GH200NVL)的時候,我們介紹了具有 142GB/144GB 內存的 GH200 (非 NVL)。據介紹,與當前一代產品相比,雙配置的內存容量增加了 3.5 倍,帶寬增加了 3 倍,包括一台具有 144 個 ArmNeoverse 核心、8 petaflops 的 AI 性能和 282GB 最新 HBM3e內存技術的產品。

GB200 將成爲 2024 年的下一代加速器,GX200 將成爲 2025 年的下一代加速器。
面向 x86 市場,英偉達預計 2024 年將推出 H200,它會在 Hopper 架構上進行更新,並具有更多內存。B100和B40是下一代架構部件,隨後是2025年的X100和X40。考慮到B40和X40位於“企業”賽道上,而當前的L40S是PCIe卡,因此這些可能是PCIe卡。
在網絡方面,Infiniband 和以太網都將於 2024 年從 400Gbps 發展到 800Gbps,然後在 2025 年達到 1.6Tbps。鑑於我們已經在 2023 年初研究了 Broadcom Tomahawk 4 和交換機,並看到了合作夥伴今年的800G Broadcom Tomahawk 5 交換機,感覺有點像 NVIDIA 以太網產品組合在以太網方面明顯落後。Broadcom 的 2022-2023 年 800G 系列似乎與 NVIDIA 的 2024 年升級保持一致,NVIDIA 在 2023 年中期宣布了 Spectrum 4,而Tomahawk 5 則在大約 21-22 個月前宣布。在業界,芯片發布與投入生產之間通常存在很大的差距。

由此可見,在 Infiniband 方面,NVIDIA 是孤軍奮战。從該路线圖中,我們沒有看到 NVSwitch/NVLink 路线圖。
其他人工智能硬件公司應該會被 NVIDIA 的企業人工智能路线圖嚇到。在人工智能訓練和推理領域,這意味着 2024 年將更新當前的 Hopper,然後在 2024 年晚些時候過渡到 Blackwell 一代,並在 2025 年採用另一種架構。
在 CPU 方面,我們最近已經看到了令人激動的更新節奏,x86 方面的核心數量之战出現了大幅增長。例如,英特爾的頂級 Xeon 核心數量預計從 2021 年第二季度初到2024 年第二季度將增加 10 倍以上。NVIDIA 在數據中心領域似乎也在緊跟這一步伐。對於構建芯片的人工智能初創公司來說,考慮到 NVIDIA 的新路线圖步伐,這現在是一場競賽。
對於英特爾、AMD,或許還有 Cerebras 來說,隨着 NVIDIA 銷售大型高利潤芯片,他們的目標將會發生變化。它還將基於 Arm 的解決方案置於頂級賽道中,這樣它不僅可以在 GPU/加速器方面獲得高利潤,而且可以在 CPU 方面獲得高利潤。
一個值得注意的落後者似乎是以太網方面,這感覺很奇怪。
精准的供應鏈控制
據semianalysis說法,英偉達之所以能夠在群雄畢至的AI芯片市場一枝獨秀,除了他們在硬件和軟件上的布局外,對供應鏈的控制,也是英偉達能坐穩今天位置的一個重要原因。
英偉達過去多次表明,他們可以在短缺期間創造性地增加供應。英偉達愿意承諾不可取消的訂單,甚至預付款,從而獲得了巨大的供應。目前,Nvidia 有111.5 億美元的採購承諾、產能義務和庫存義務。Nvidia 還額外籤訂了價值 38.1 億美元的預付費供應協議。單從這方面看,沒有其他供應商可以與之相媲美,因此他們也將無法參與正在發生的狂熱AI浪潮。
自 Nvidia 成立之初起,黃仁勳就一直積極布局其供應鏈,以推動 Nvidia 的巨大增長雄心。黃仁勳曾在重述了他與台積電創始人張忠謀的早期會面中表示:
“1997 年,當張忠謀和我相遇時,Nvidia 那一年的營收爲 2700 萬美元。我們有 100 個人,然後我們見面了。你們可能不相信這一點,但張忠謀曾經打銷售電話。你以前經常上門拜訪,對嗎?你會進來拜訪客戶,我會向張忠謀解釋英偉達做了什么,你知道,我會解釋我們的芯片尺寸需要有多大,而且每年都會變得越來越大而且更大。你會定期回到英偉達,讓我再講一遍這個故事,以確保我需要那么多晶圓,明年,我們开始與台積電合作。Nvidia 做到了,我認爲是 1.27 億,然後,從那時起,我們每年增長近 100%,直到現在。”

張忠謀一开始不太相信英偉達需要這么多晶圓,但黃仁勳堅持了下來,並利用了當時遊戲行業的巨大增長。英偉達通過大膽供應而取得了巨大成功,而且通常情況下他們都是成功的。當然,他們必須時不時地減記價值數十億美元的庫存,但他們仍然從超額訂購中獲得了積極的收益。
如果某件事有效,爲什么要改變它?
最近這一次,英偉達又搶走了SK海力士、三星、美光HBM的大部分供應,這是GPU和AI芯片正在追逐的又一個核心。英偉達向所有 3 個 HBM 供應商下了非常大的訂單,並且正在擠出除Broadcom/Google之外的其他所有人的供應。
此外,Nvidia 還已經买下了台積電 CoWoS 的大部分供應。但他們並沒有就此止步,他們還出去考察並买下了Amkor的產能。
Nvidia 還利用了 HGX 板或服務器所需的許多下遊組件,例如重定時器、DSP、光學器件等。拒絕英偉達要求的供應商通常會受到“胡蘿卜加大棒”的對待。一方面,他們可以從英偉達那裏獲得看似難以想象的訂單,另一方面,他們也面臨着被英偉達現有供應鏈所設計的問題。他們僅在供應商至關重要並且無法設計出來或多源時才使用提交和不可取消。
每個供應商似乎都認爲自己是人工智能贏家,部分原因是英偉達從他們那裏訂購了大量訂單,而且他們都認爲自己贏得了大部分業務,但實際上,英偉達的發展速度是如此之快,甚至已經超出了他們的想想。
回到上面的市場動態,雖然 Nvidia 的目標是明年數據中心銷售額超過 700 億美元,但只有 Google 擁有足夠的上遊產能,能夠擁有超過 100 萬個規模的有意義的單元。即使AMD最新調整了產能,他們在AI方面的總產能仍然非常溫和,最高只有幾十萬台。
精明的商業計劃
衆所周知,Nvidia 正在利用 GPU 的巨大需求,利用 GPU 向客戶進行追加銷售和交叉銷售。供應鏈上的多位消息人士告訴semianalysis,英偉達正在基於多種因素對企業進行優先分配,這些因素包括但不限於:多方採購計劃、計劃生產自己的人工智能芯片、購买英偉達的 DGX、網卡、交換機和光學器件等。
Semianalysis指出,CoreWeave、Equinix、Oracle、AppliedDigital、Lambda Labs、Omniva、Foundry、Crusoe Cloud 和 Cirrascale 等基礎設施提供商所面臨的分配的產品數量遠比亞馬遜等大型科技公司更接近其潛在需求。
據semianalysis所說,事實上,Nvidia 的捆綁銷售非常成功,盡管之前是一家規模很小的光收發器供應商,但他們的業務在 1 季度內增長了兩倍,並有望在明年實現價值超過 10 億美元的出貨量。這遠遠超過了 GPU 或網絡芯片業務的增長率。
而且,這些策略是經過深思熟慮的,例如目前,在 Nvidia 系統上通過可靠的 RDMA/RoCE 實現 3.2T 網絡的唯一方法是使用 Nvidia 的 NIC。這主要是因爲Intel、AMD、Broadcom缺乏競爭力,仍然停留在200G。
在Semianalysis开來,Nvidia正在趁機管理其供應鏈,使其 400G InfiniBand NIC 的交貨時間明顯低於 400G 以太網 NIC。請記住,兩個 NIC (ConnectX-7) 的芯片和電路板設計是相同的。這主要取決於 Nvidia 的 SKU 配置,而不是實際的供應鏈瓶頸。這迫使公司購买 Nvidia 更昂貴的 InfiniBand 交換機,而不是使用標准以太網交換機。當您購买具有 NIC 模式 Bluefield-3 DPU 的 Spectrum-X 以太網網絡時,Nvidia 會破例。
事情還不止於此,看看供應鏈對 L40 和 L40S GPU 的瘋狂程度就知道了。
Semianalysis透露,爲了讓那些原始設備制造商贏得更多的 H100 分配,Nvidia 正在推動 L40S的銷售,這些 OEM 也面臨着購买更多 L40S 的壓力,進而獲得更好的 H100 分配。這與 Nvidia 在 PC 領域玩的遊戲相同,筆記本電腦制造商和 AIB 合作夥伴必須購买大量的 G106/G107(中端和低端 GPU),才能爲更稀缺、利潤率更高的 G102/G104 獲得良好的分配(高端和旗艦 GPU)。
台灣供應鏈中的許多人都被認爲 L40S 比 A100 更好,因爲它的 FLOPS 更高。需要明確的是,這些 GPU 不適合 LLM 推理,因爲它們的內存帶寬不到 A100 的一半,而且沒有 NVLink。這意味着除了非常小的模型之外,以良好的總體擁有成本在它們上運行LLM幾乎是不可能的。高批量大小(High batch sizes)具有不可接受的令牌/秒/用戶(tokens/second/user),使得理論上的 FLOPS 在實踐中對於 LLM 毫無用處。
Semianalysis說,OEM 廠商也面臨着支持 Nvidia 的 MGX 模塊化服務器設計平台的壓力。這有效地消除了設計服務器的所有艱苦工作,但同時也使其商品化,創造了更多競爭並壓低了 OEM 的利潤。戴爾、HPE 和聯想等公司顯然對 MGX 持抵制態度,但台灣的低成本公司,如超微、廣達、華碩、技嘉、和碩和華擎,正在急於填補這一空白,並將低成本“企業人工智能”商品化。
當然,這些參與 L40S 和 MGX 遊戲的 OEM/ODM 也獲得了 Nvidia 主线 GPU 產品更好的分配。
雖然英偉達正在面臨着芯片廠商和系統廠商自研芯片的夾擊。但這些布局,似乎短期內都能讓英偉達高枕無憂。他們依然會是AI時代最成功的“賣鏟人”。
標題:英偉達芯片,最新路线圖
地址:https://www.iknowplus.com/post/40996.html